«Система управления базами данных»
Что такое СУБД?
До появления СУБД разработчики работали непосредственно с файлами (так называемыми «электронными картотеками»), полностью создавая всю «начинку»: определяли форматы хранения, способы индексации и поиска данных, механизмы проверки корректности. Подобный подход был достаточно трудоёмким и негибким: любая модификация структуры данных или правил доступа означала переписывание значительной части программного кода.
С возникновением более совершенных моделей данных (иерархической, сетевой, реляционной) появилась идея отделить управление данными от прикладных программ. Возникли специальные комплексы программных средств — системы управления базами данных (СУБД). Их главная задача — предоставить универсальные механизмы для хранения и обслуживания данных, чтобы прикладным разработчикам не приходилось снова и снова изобретать базовые операции.
Система управления базами данных (Database Management System, DBMS) – это комплекс программных средств, с помощью которых можно создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ пользователей.
Современная БД немыслима без СУБД. Последняя обеспечивает удобные инструменты для:
- проектирования и администрирования (создание структуры таблиц, настройка прав, заданий, мониторинг);
- управления безопасностью (разграничение прав пользователей);
- реализации механизмов параллельного доступа;
- резервного копирования и восстановления;
- взаимодействия с программными приложениями (через язык SQL или другие интерфейсы).
Особый акцент в определении нужно сделать на «контролируемом доступе», который включает в себя:
- Предотвращение несанкционированного доступа к данным.
- Контроль многопользовательского (параллельного) доступа.
- Поддержку целостности данных.
- Восстановление данных после сбоев.
Таким образом, СУБД не только предоставляет базовые операции с данными, но и берёт на себя большую часть «ответственности» по обеспечению корректности, защиты и сохранности информации.
Ключевой функционал СУБД
Основные функции были выделены ещё Э.Ф. Коддом в начале 1980-х годов. С тех пор этот список только дополнялся:
-
Доступность данных
СУБД должна предоставить средства для вставки, редактирования, удаления и выборки данных без необходимости углубляться в физические аспекты хранения. С точки зрения пользователя операции должны быть «прозрачными»: детали реализации (как именно информация хранится на диске, где лежат индексы и т. д.) скрыты. -
Метаописание данных
Наличие системного каталога (или словаря данных), в котором хранится структура БД: имена таблиц, их столбцов и типов данных, связи, ограничительные условия, учётные записи пользователей и вспомогательная статистика. Метаданные помогают понять суть хранимой информации и обеспечивают более безопасный и упорядоченный доступ. -
Управление параллельностью
Одновременная работа многих пользователей с общими данными требует механизмов, которые предотвращают конфликты при одновременном редактировании и чтении. СУБД должна уметь управлять блокировками, обеспечивать «сериальность» транзакций, решать конфликты блокировок или, по крайней мере, снижать риски некорректных обновлений. -
Обработка данных в рамках транзакции
Данные в СУБД обновляются целостными блоками (транзакциями). Если внутри транзакции что-то идёт не так (программа аварийно завершается, пропадает связь, возникает ошибка), изменения автоматически отменяются (откат). Принцип «либо все операции выполнились, либо ни одна» обеспечивает непротиворечивое состояние данных.Классическим примером является снятие наличных в банкомате: если не происходит физическая выдача денег, транзакция откатывается, и сумма возвращается на счёт клиента.
-
Обеспечение целостности данных
Правила целостности — «каркас», который гарантирует, что данные в БД не придут в несоответствие. Обычно говорят о целостности доменов (типов), строк (уникальность первичных ключей), связей (ссылочная целостность), а также о дополнительных корпоративных ограничениях. СУБД должна не допускать операций, нарушающих эти правила. -
Восстановление данных
При аппаратных сбоях или ошибках СУБД должна уметь восстанавливать утраченную или повреждённую информацию. Основная защита — система резервного копирования и журналы транзакций, что позволяет «откатить» или «прокрутить» изменения в нужную точку во времени. -
Обмен данными
Современная СУБД должна поддерживать сетевые протоколы и обеспечивать удалённый доступ к БД, чтобы пользователи могли взаимодействовать с информацией из разных точек (локальной сети, интернета и т. д.). -
Контроль за доступом
Только авторизованные пользователи с необходимыми правами могут работать с базой. Это включает проверку логинов и паролей, разграничение уровней доступа (чтение, модификация, администрирование и т. д.).
Также в большинстве случаев можно выделить другие дополнительные сервисы (мониторинг производительности, статистический анализ запросов, экспорт/импорт и проч.), которые часто необходимы для крупных проектов, где важны тонкая настройка и анализ работы системы.
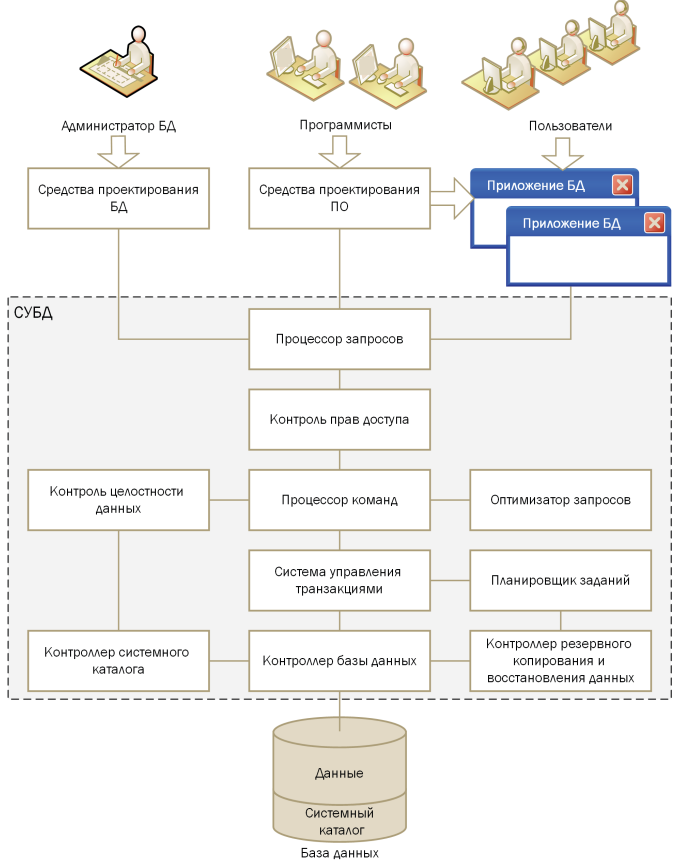
Компоненты СУБД
СУБД — это сложный программный комплекс, над созданием которого трудятся высококвалифицированные специалисты. Несмотря на то что разные СУБД могут существенно отличаться друг от друга, можно в обобщённом виде выделить типовые компоненты.
-
Участники работы с БД
- Администратор БД (Database Administrator, DBA): разрабатывает проект, настраивает структуру БД, определяет схемы резервного копирования, управляет безопасностью, отслеживает производительность, вносит изменения по мере необходимости.
- Программисты (разработчики клиентских и серверных приложений): больше внимания уделяют созданию форм ввода и отчётов, интеграции с другими системами, написанию кода, взаимодействующего с БД.
- Конечные пользователи: обычно работают с заранее разработанными формами и отчётами; иногда даже не осознают, что система использует СУБД.
-
Модули, обрабатывающие SQL-запросы
- Процессор запросов: принимает инструкции SQL и переводит их в «понятные» ядру СУБД низкоуровневые операции.
- Оптимизатор запросов: определяет оптимальный план выполнения, используя индексы и статистику.
- Система управления транзакциями: координирует обработку обновлений и решает, как фиксировать или откатывать результаты.
-
Модуль безопасности
- Контроль прав доступа: проверяет, имеет ли пользователь право выполнять данную операцию (чтение, запись, удаление), сверяет логин/пароль и уровень привилегий.
- Модуль целостности: следит за соблюдением ограничений (доменных, ссылочных и т. д.), используя данные из системного каталога.
-
Системный каталог (словарь данных)
- Это «мозг» СУБД, хранящий метаданные обо всех элементах базы. Здесь описаны все объекты БД: таблицы, индексы, представления, типы данных, ограничения, пользователи, статистическая информация.
- В большинстве СУБД системный каталог реализован в виде специальных служебных таблиц, скрытых от обычных пользователей.
-
Контроллер БД
- Обеспечивает взаимодействие с файлами, где фактически хранятся данные и системный каталог.
- Использует стандартные механизмы операционной системы (чтение, запись, блокировки на уровне файлов и т. д.).
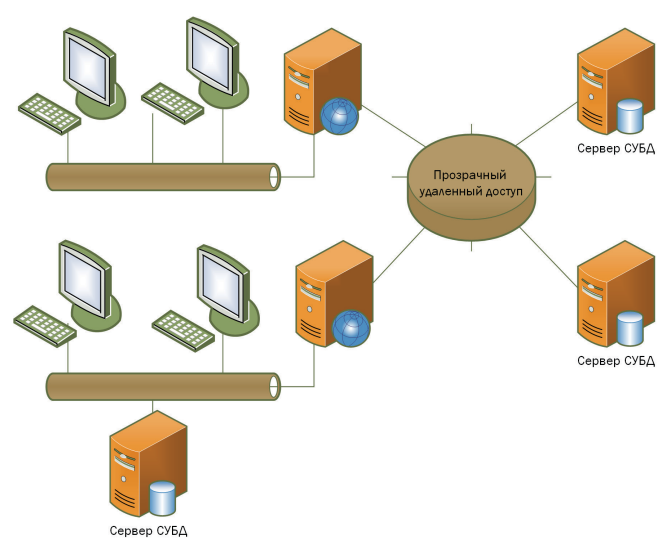
Архитектурные решения доступа к БД
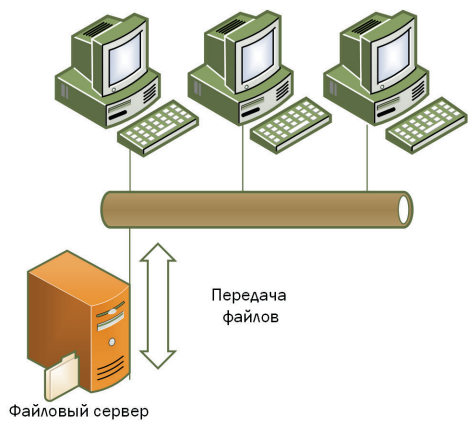
«Файл-сервер»
Файлы базы находятся в сетевой папке сервера. Приложение (клиент) на рабочей станции напрямую открывает и модифицирует файлы, по сути, перекачивая их через сеть.
Недостатки.
- Высокая нагрузка на сеть при чтении и записи больших объёмов данных.
- Управление параллельностью и целостностью усложнено, так как несколько клиентов могут работать с одной и той же «кусочной» информацией.
- На каждом рабочем месте нужно устанавливать или дублировать основные модули СУБД.
Такой подход применялся в начале развития микрокомпьютеров и до сих пор сохраняется в самых простых решениях (например, Microsoft Access при одновременной работе нескольких человек).
«Клиент-сервер»
На выделенной машине разворачивается полноценный сервер СУБД, где хранятся файлы базы. Клиентские приложения общаются с ним через язык SQL или другое протокольное API, передавая запросы и получая результаты.
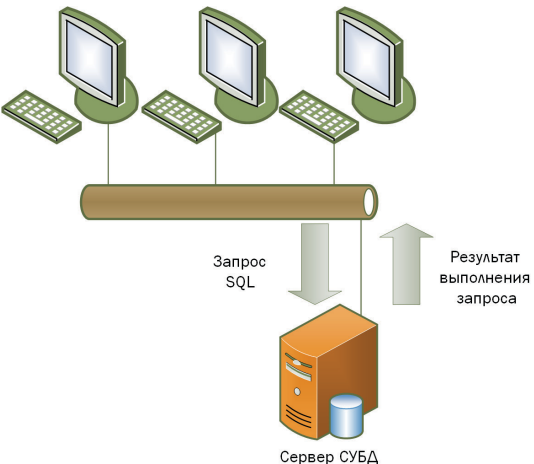
Преимущества.
- Централизованное хранение: легко управлять безопасностью и резервным копированием.
- Эффективность: по сети передаются только результаты выполнения запроса, а не весь файл.
- Параллельная работа: сервер СУБД умеет распределять нагрузку, блокировать данные на уровне строк или страниц, управлять транзакциями.
- Прозрачность: клиенты могут работать в разных ОС (Windows, Linux и т. д.), если имеются нужные драйверы и сетевые протоколы.
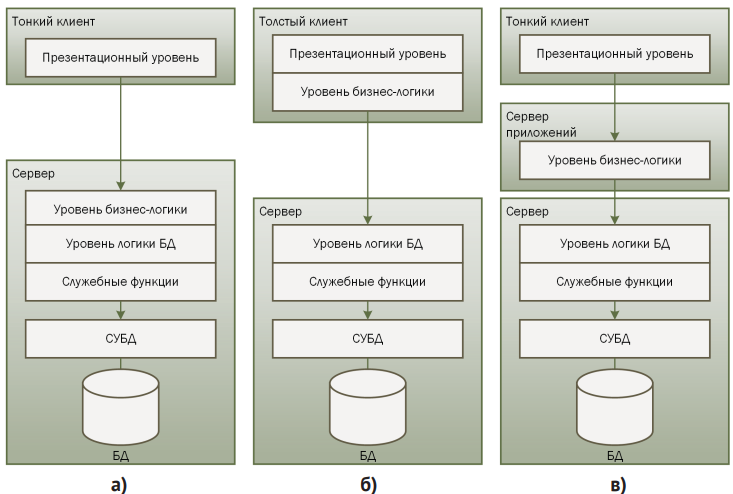
Варианты распределения логики между сервером и клиентом:
- Тонкий клиент (Thin Client): клиент предоставляет лишь интерфейсную часть (формы, экранные поля, кнопки); вся «бизнес-логика» и механизмы проверки сосредоточены на сервере.
- Толстый клиент (Fat Client): часть логики по обработке данных, проверке бизнес-правил и даже формированию SQL-запросов переносится на рабочую станцию пользователя.
Примеры СУБД: MySQL, Oracle, Microsoft SQL Server, PostgreSQL, InterBase, Firebird и др.
Многоуровневая архитектура
Иногда между клиентом и сервером БД вводят дополнительный уровень — сервер приложений. Клиент уже не подключается напрямую к СУБД, а взаимодействует с этим промежуточным сервером, который:
- инкапсулирует бизнес-логику;
- контролирует трансляцию данных для разных клиентов;
- может масштабироваться и балансировать нагрузку.
Технологии: CORBA, DCOM, SOAP, RPC, сокеты и т. д.
Преимущества: гибкость, возможность интеграции разных систем, централизованное управление логикой.
Недостатки: сложность проектирования и большие требования к квалификации разработчиков.
Распределенная система
В распределённых БД данные могут храниться на нескольких серверах, часто географически удалённых. Для пользователя это может выглядеть как единая база, хотя за кулисами происходит обмен между узлами, осуществляются механизмы репликации и фрагментации.
- Гомогенные (все узлы используют одну и ту же СУБД).
- Гетерогенные (узлы разных производителей, возможна конвертация форматов).
Распределённые БД повышают отказоустойчивость (при падении одного узла система продолжает работать), но усложняют администрирование (нужно синхронизировать данные, следить за целостностью во всех сегментах).
«Реляционная модель»
Реляционный подход был разработан математиком Эдгаром Фрэнком Коддом (1923–2003). В июне 1970 года он опубликовал статью «Реляционная модель данных для больших совместно используемых банков данных» (Codd E. F. A Relational Model of Data for Large Shared Data Banks. CACM 13: 6), в которой впервые сформулировал концепцию реляционной модели.
Первопричиной возникновения нового по тем временам подхода к проектированию баз данных послужили существенные ограничения предыдущих моделей. Сетевая и иерархическая модели, существовавшие до реляционной, оказались сложными в управлении и непонятными широкому кругу пользователей. Кодд стремился найти способ, сочетающий математическую строгость (опора на теорию множеств) с высокой доступностью и простотой при проектировании.
Реляционная модель предлагает рассматривать базу данных как совокупность связных двумерных таблиц (отношений). При этом каждая таблица отражает некоторую сущность и её свойства, а теория множеств обеспечивает математическое обоснование для операций над этими таблицами.
«Модель данных» — это логическая конструкция, описывающая объекты базы и операции над ними. Чтобы она стала реальной БД, её нужно физически реализовать в конкретной СУБД.
Любая реляционная база данных начинается с понимания того, какие объекты (или сущности) будет описывать система и какими признаками (или атрибутами) эти объекты обладают.
Основные понятия
Сущность (entity) – это обобщённый класс объектов, подлежащих хранению в базе. Чаще всего сущность отвечает на вопросы «Кто?» или «Что?». Например, в библиотеке: «Автор», «Книга», «Читатель», а в авиакомпании: «Рейс», «Самолёт», «Пассажир». Экземпляр сущности — это конкретный представитель данного класса. Если сущность – это «Книга», то экземплярами будут «Война и мир» и «Ромео и Джульетта»; если сущность – это «Самолёт», то экземплярами станут конкретные борты с их уникальными номерами.
«Экземпляр сущности» в реальной СУБД соответствует отдельной строке в реляционной таблице.
У каждой сущности есть отличительные свойства, которые в базе данных называются атрибутами. Например, самолёт может иметь такие характеристики, как марка, максимальная скорость, дата выпуска, а читатель — имя, номер телефона и адрес. При проектировании БД нужно выбирать именно те параметры, которые важны для решения прикладных задач, отбрасывая избыточные или неактуальные.
- Простые. Хранят одно однозначное значение (например, «Название», «Дата рождения»).
- Составные. Объединяют несколько более мелких значений, часто встречаются с адресами (город, улица, индекс и т. д.).
- Производные. Вычисляются на основе других полей. Так, налог может рассчитываться в проценте от заработной платы; возраст сотрудника – из «даты рождения» и «текущей даты».
- Многозначные. Позволяют хранить несколько значений в одном атрибуте, например список телефонов. В классической реляционной модели предпочтительнее создавать отдельную таблицу для таких данных, но иногда допускают многозначные поля для упрощения проекта.
В современных БД в качестве многозначных атрибутов в современных СУБД (например, PostgreSQL) часто используются тип данных, хранящий данные в формате
JSON.
При проектировании БД крайне важно предусмотреть такой атрибут, который уникально отличает один экземпляр сущности от другого. В одном случае это номер паспорта (для человека), в другом — заводской номер (для самолёта). Часто разработчики выбирают искусственное автоинкрементное поле, которое получает новое значение при каждой вставке строки, исключая дубликаты.
Идентифицирующие атрибуты впоследствии становятся ключами (первичными) в реляционных таблицах. Они гарантируют, что все экземпляры сущности различимы и система может безошибочно обращаться к нужной записи.
Тип данных и домен
Чтобы описать конкретный атрибут, в базе данных необходимо указать, какого типа там будут храниться значения. Однако одного выбора типа (целое число, строка, дата и т. д.) часто оказывается недостаточно, поэтому вводят дополнительные ограничения, которые называются доменами.
В любой СУБД или языке программирования мы встречаемся с вопросом, как хранить определённую информацию:
- Числа могут быть целыми (
INTEGER) или вещественными (FLOAT,REAL). - Тексты обозначаются строковыми типами (
CHAR,VARCHAR).Вопрос. Чем отличаются типы
CHARиVARCHAR? - Даты и время имеют собственные типы (
DATE,DATETIME,TIMESTAMP).
Типизация указывает размер занимаемой памяти и определяет допустимые операции. Так, невозможно складывать строку «ABC» с числом 123 без явного преобразования, а результат деления никогда не занесётся напрямую в целое поле, если в нём не учесть округление.
Тип данных задаёт физический формат хранения: сколько байт отвести, как распознавать содержимое. Но не решает, логично ли значение (например, «телефон» в виде числа с ведущим нулём или «дата рождения» в формате доисторического периода).
Понятие домен расширяет тип данных дополнительными логическими правилами и ограничениями, более близкими к реальной предметной области. К примеру,
- Почтовый индекс в России — это строго 6 цифр. Просто задать тип
CHAR(6)означает «6 символов», но не проверяет, что там действительно цифры. Если же мы опишем домен индекса как «строка из 6 цифр», то СУБД не допустит ввода букв или 7-значных значений. - Дата рождения сотрудника не должна позволять указывать год, далёкий от разумных человеческих пределов (скажем, не меньше 1900 и не больше текущего дня). Стандартный тип
DATETIMEтакого ограничения сам по себе не накладывает, поэтому домен накладывает нужные проверки.
Домены помогают реализовать целостность доменов, когда значения в каждом поле не просто «формально соответствуют» типу (число или текст), но и «логически корректны» с точки зрения конкретной задачи.
В реляционной модели предусмотрен особый определитель NULL, который означает «неизвестно» или «не определено». Это может потребоваться, если:
- Студент поступил в вуз, но ему ещё не выдали зачётную книжку, и её номер неизвестен.
- Сотруднику пока неизвестен адрес (он сменил место жительства).
Связь между сущностями
После того, как мы определись с тем, какие сущности (объекты) нужно хранить, наступает черёд понять, как они взаимодействуют. Такой «вектор связи» между ними обычно выражается глаголом: «Автор написал книгу», «Заказчик оформил заказ», «Пассажир летит рейсом».
Типы связей:
- Один к одному (1:1). Встречается достаточно редко. Обычно говорит о том, что избыточно выделили отдельную сущность вместо атрибута.
- Один ко многим (1:N). Наиболее распространённая ситуация: один автор может написать много книг, один отдел — иметь много сотрудников.
- Многие ко многим (M:N). В классической реляционной модели не поддерживается напрямую. Решается путём ввода промежуточной таблицы: так связь M:N разбивается на две связи 1:N.
Если у вас возникла связь «1:1», вполне возможно, что это атрибут, а не отдельная сущность.
С точки зрения реляционной модели, вся информация представлена в виде двумерных таблиц, называемых отношениями. Каждая сущность из реального мира (например, «Книга», «Самолёт», «Сотрудник») имеет отдельную таблицу, где:
- Строка (кортеж) хранит информацию об одном экземпляре сущности: одной конкретной книге или одном сотруднике.
- Столбец (атрибут) соответствует определённой характеристике (название, автор, телефон, адрес и т. д.).
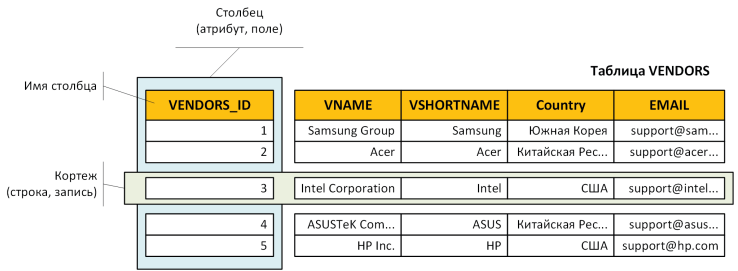
Требования к реляционной таблице:
- Уникальные имена столбцов. В пределах одной таблицы имя атрибута не должно повторяться.
- Каждая строка описывает одну сущность. Нельзя «мешать» сущности «Книга» и «Автор» в одной таблице, если это разные объекты.
- Отсутствие идентичных строк. Если две строки полностью совпадают, система не может однозначно понять, какую именно из них обновлять или удалять.
- Атомарные значения в ячейках. Запрещается хранить в одной ячейке «список» из нескольких элементов (например, три адреса сразу).
- Нет жёсткого порядка строк и столбцов. Можно выводить их в любом порядке при помощи SQL (ORDER BY, выбор столбцов и т. д.).
Замечание
Когда таблица удовлетворяет этим условиям, о ней говорят, что она приведена хотя бы к первой нормальной форме (1NF). В более развитых нормальных формах дополнительные требования ужесточают логику и уменьшают дублирование данных.
Для того чтобы однозначно найти нужную строку в таблице, в реляционной модели используют систему ключей.
Первичный ключ (Primary Key, PK) Это особое поле или набор полей, которые уникально идентифицируют каждую строку. Чаще всего создают искусственное целочисленное поле с автоинкрементом (ID), которое при добавлении новой записи получает очередное значение, исключая дубликаты.
- Естественный ключ (номер паспорта, VIN автомобиля) тоже можно использовать, но тогда изменение этого реального номера (например, при замене документа) приводит к сложностям в БД.
- Автоинкрементный ключ остаётся неизменным, не зависит от внешних обстоятельств и упрощает администрирование.
Внешний ключ (Foreign Key, FK)
Позволяет связать одну таблицу с другой. Значение во внешнем ключе указывает на первичный ключ «родительской» таблицы. Допустим, если у «Сотрудника» есть поле ID_Отдела, то в нём хранятся значения ID из таблицы «Отделы». Если запись «Отдел кадров» имеет ID=3, а у сотрудника Арбузова ID_Отдела=3, то мы знаем, что он работает именно в этом отделе.
Целостность данных
В реляционной модели важно не только сохранить нужные строки и столбцы, но и убедиться, что данные отражают объекты реального мира без противоречий. Для этого существуют несколько уровней целостности.
Целостность доменов Каждое поле обязано соответствовать описанному домену. Если мы утвердили, что «Дата рождения» не может быть старше 150 лет или позже текущей даты, БД должна блокировать любые неуместные значения. Аналогично с другими полями: почтовый индекс, код города и т. д.
Целостность сущностей Требует, чтобы каждая строка была уникальной и имела корректный первичный ключ. Если ключ состоит из нескольких атрибутов (составной ключ), ни один из этих атрибутов не может быть NULL. Кроме того, можно закладывать дополнительные проверки (например, студент не может одновременно числиться на двух дневных факультетах, если это нарушает логику вуза).
Ссылочная целостность Если таблицы связаны внешними ключами, нельзя допускать «осиротевших» ссылок. Если родительская запись удаляется, дочерняя или корректно обрабатывается (удаляется, обнуляется, запрещается удаление), или обновляется так, чтобы ссылки оставались непротиворечивыми.
Корпоративная целостность Вся специфика конкретных бизнес-правил, присущих организации. Например, если читатель взял книгу в библиотеке и не вернул её в срок, нельзя выдавать ему новую; если кладовщик разместил молоко в несоответствующем месте, БД должна это блокировать. Эти правила обычно внедряют с помощью триггеров и хранимых процедур, которые автоматически проверяют нужную логику при вставке, обновлении или удалении данных.
Соблюдение целостности данных напрямую влияет на качество работы базы и точность отражения реальности. Даже если формально есть правильные таблицы, но нет защиты от нелепых значений и нарушений связей, результаты будут далеки от истины.
Реляционная алгебра
Реляционная алгебра — это теоретический язык для манипулирования данными, основанный на теории множеств. Она вводит операции, которые создают новые «отношения» (таблицы) из уже имеющихся, что дало основу для языка SQL.
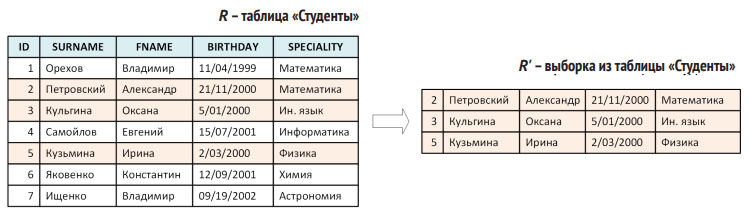
- Выборка (selection, σ). Забирает из исходной таблицы только те строки, которые удовлетворяют заданному условию (например, «Студенты, родившиеся в 2000 году»).
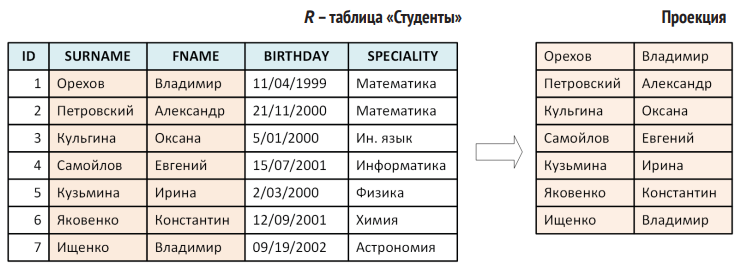
- Проекция (projection, ↓). Формирует новую «таблицу», в которой остаются только нужные столбцы. Все строки сохраняются, но отбрасываются ненужные поля.
- Декартово произведение (×). Каждая строка одной таблицы совмещается со всей совокупностью строк другой. Получается множество пар (или троек, если продолжать), что служит основой для будущих соединений. На практике используется достаточно редко.
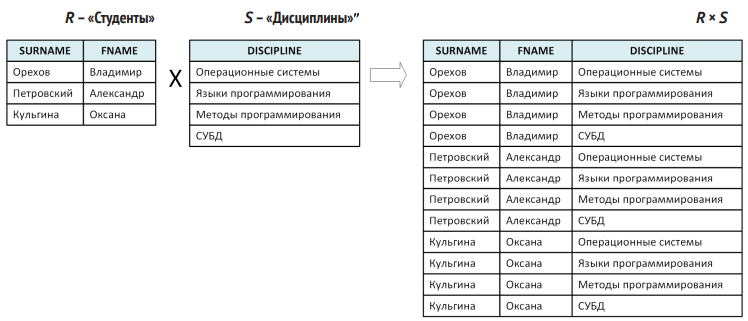
- Объединение (union, ∪). Складывает вместе совместимые по структуре таблицы, объединяя их строки и удаляя дубликаты.
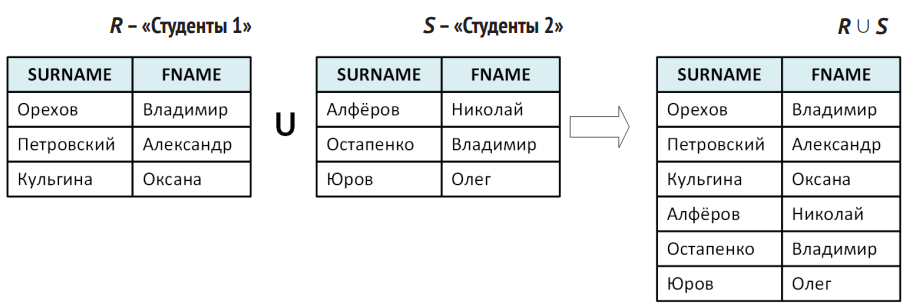
- Разность (set difference, –). Выбирает строки, которые присутствуют в одной таблице и отсутствуют в другой (подобно вычислению, кто не сдал экзамен, если сравнить «список студентов группы» минус «студенты, сдавшие экзамен»).
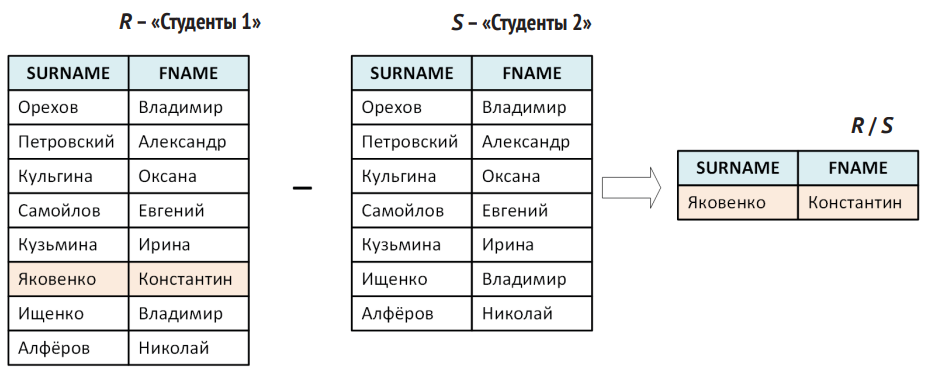
- Пересечение (intersection, ∩). Выбирает строки, которые встречаются в обеих таблицах.
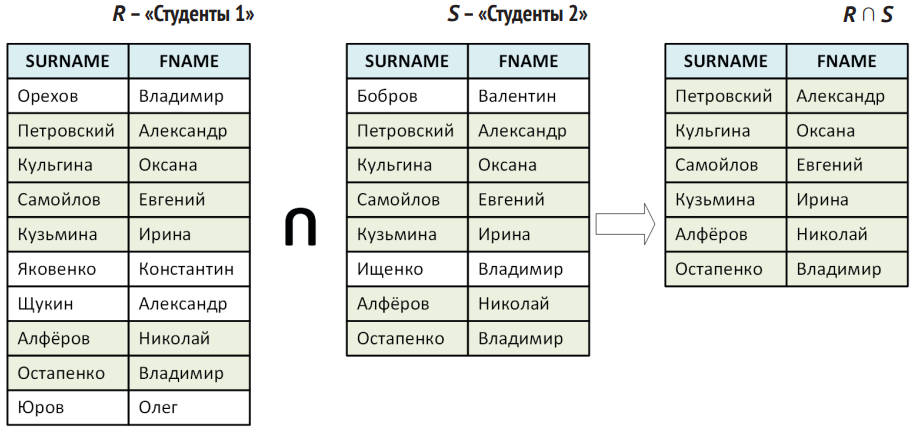
- Деление (division, ÷). Полезная, но менее очевидная операция. Даёт возможность понять, какие объекты «выполнили весь набор» заданных условий. Нужно учитывать две вещи:
- Результат деления исходной таблицы R на таблицу-делитель S будет содержать столбцы, отсутствующие в делителе;
- В качестве строк в результат P войдут только те записи из делителя S, что при декартовом произведении результата на делитель P × S содержатся в делимом R.
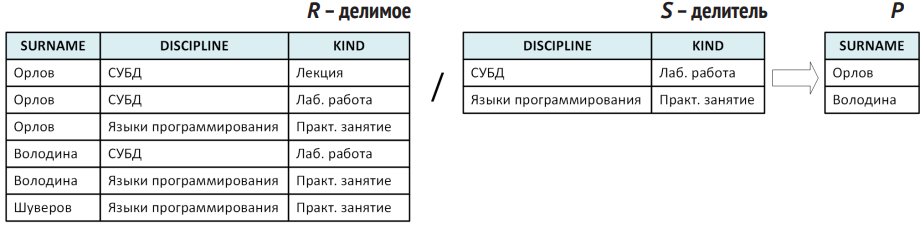
- Соединение (join, ⨝). Главный инструмент для связывания информации в реляционных системах. Обычно комбинация «декартово произведение + условие равенства по ключевым полям» (естественное соединение). Также бывают внешние соединения (left join, right join), при которых «недостающие» строки одной из таблиц тоже сохраняются.
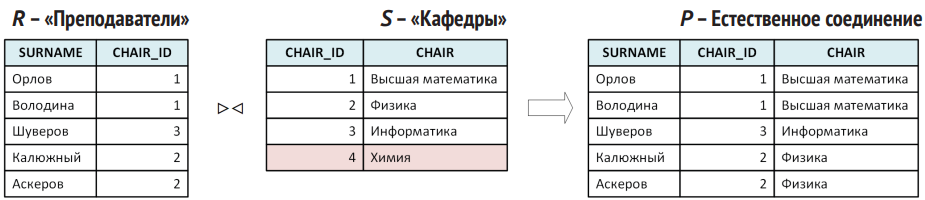
Естественное соединение складывает строки, у которых совпадают значения связующих полей (первичных и внешних ключей), и не включает те, где соответствий нет. Внешнее соединение (outer join) может добавить ещё и «брошенные» строки, проставляя в пустых местах
NULL.
Практическое задание
На сайте aermolenko.ru выполнить задания в модулях 1-3 по дисциплине Базы данных.