Для регистрации на github НЕ используйте почту с российским доменом (например, yandex.ru), иначе после прохождения капчи вас вернет обратно на начальный этап регистрации.
Шаг 1: Генерация SSH-ключа (алгоритм ED25519)
- Откройте PowerShell.
- Сгенерируйте SSH-ключ:
ssh-keygen -t ed25519 -C "your_email@example.com"
Ключи по умолчанию будут сохранены в
C:\Users\YourUserName\.ssh\id_ed25519.
- Введите фразу-пароль (будет запрашиваться при попытке использования ключа, дополнительная гарантия безопасности на случай, если ваш ключ будет скомпроментирован) или пропустите этот шаг.
Шаг 2: Настройка файла known_hosts
- Создайте или откройте файл
known_hosts: Откройте файл known_hosts в текстовом редакторе, который поддерживает UTF-8, например, в Notepad++ или Visual Studio Code. По умолчанию файл должен находиться в директорииC:\Users\YourUserName\.ssh\. - Используйте ssh-keyscan с преобразованием кодировки: Выполните команду в PowerShell, чтобы добавить fingerprint в known_hosts с корректной кодировкой:
ssh-keyscan github.com | Out-File -Encoding utf8 ~/.ssh/known_hosts
Эта команда добавляет fingerprint для GitHub и сохраняет его в файл known_hosts в правильной кодировке UTF-8.
Примечание: Если вы хотите добавить несколько хостов, выполните команду для каждого из них:
ssh-keyscan host1.com | Out-File -Append -Encoding utf8 ~/.ssh/known_hosts ssh-keyscan host2.com | Out-File -Append -Encoding utf8 ~/.ssh/known_hosts
Шаг 3: Настройка файла config
- Создайте или отредактируйте файл
config: Откройте~/.ssh/config(обычноC:\Users\YourUserName\.ssh\config) и добавьте:
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_ed25519
Если добавляете другие хосты (например, для собственного git-сервера), создавайте отдельные секции Host для каждого из них.
Шаг 4: Добавление SSH-ключа в GitHub
- Скопируйте публичный ключ:
Get-Content ~/.ssh/id_ed25519.pub | Set-Clipboard
- Добавьте ключ на GitHub:
- Перейдите в настройки SSH-ключей.
- Нажмите "New SSH key", вставьте скопированный ключ и сохраните его.
Шаг 5: Тестирование подключения
- Проверьте подключение:
ssh -T git@github.com
Успешное подключение отобразит сообщение: Hi username! You've successfully authenticated, but GitHub does not provide shell access.
Рабочий план дисциплины
Часть 1: Введение в основы
Лабораторная работа 1: Основы HTML
- Тема: Создание веб-страницы визитки
- Задание: Создать личный сайт-визитку. Использовать HTML-теги для структуры страницы: заголовки, параграфы, изображения, списки и ссылки.
- Разделы сайта: "О себе", "Навыки", "Образование", "Контакты".
Требования:
- Применить теги:
<h1>,<p>,<ul>,<img>,<a>. - Использовать таблицу для раздела "Навыки" с категориями (например, технические и управленческие навыки).
- Включить атрибуты для выравнивания изображений и добавления ссылок на социальные сети.
Лабораторная работа 2: Введение в CSS и создание навигации
- Тема: Стилизация сайта-визитки и создание навигационной панели
- Задание: Стилизовать сайт-визитку с использованием CSS. Создать навигационное меню (navbar) для перехода между разделами.
Требования:
- Подключить внешний файл стилей.
- Использовать классы и идентификаторы для стилизации секций сайта.
- Реализовать навигационную панель с помощью тегов
<nav>,<ul>,<li>и настроить ссылки на внутренние разделы сайта.
Лабораторная работа 3: Введение в JavaScript и формы
- Тема: Добавление формы обратной связи и обработка данных с использованием JavaScript
- Задание: Реализовать форму обратной связи на сайте, где пользователь может ввести имя, email и сообщение.
Требования:
- Использовать JavaScript для валидации данных формы.
- Проверить наличие заполненных полей и корректность введённых данных.
- Реализовать реакцию на успешную или неуспешную отправку формы:
- Успешная отправка: сообщение "Спасибо за обратную связь, [имя]! С вами свяжутся в ближайшее время"
- Ошибка: предупреждение "Пожалуйста, введите корректный email"
Лабораторная работа 4: Расширенный CSS, Позиционирование
- Тема: Углубленное изучение CSS — позиционирование, контейнеры, медиазапросы
- Задание: Добавить к сайту сложные CSS-правила: позиционирование (relative, absolute), использование контейнеров (flex, grid, inline-block), медиазапросы для адаптивности.
Требования:
- Стилизовать сайт для разных разрешений экранов с помощью медиазапросов.
- Использовать flex и grid для создания адаптивных макетов.
- Позиционировать элементы с помощью свойств
relativeиabsolute. - Применить нововведения CSS3 и правила для вложенных селекторов.
Часть 2: Bootstrap 5 и повышение скорости загрузки страницы
Лабораторная работа 5: Введение в Bootstrap 5
- Тема: Основы Bootstrap 5 и сеточная система
- Задание: Создать страницу портфолио с использованием сеточной системы Bootstrap.
Требования:
- Применить сеточную систему Bootstrap для адаптации макета под разные экраны.
- Использовать контейнеры для организации контента.
- Добавить стилизованные кнопки, формы и элементы интерфейса с использованием Bootstrap-компонентов.
Лабораторная работа 6: Оптимизация сайта
- Тема: Адаптивная версия сайта для мобильных устройств и оптимизация загрузки ресурсов
- Задание: Оптимизировать сайт для мобильных устройств и планшетов.
Требования:
- Использовать медиазапросы для адаптации сайта под мобильные устройства.
- Применить формат изображений
.webpдля оптимизации загрузки. - Сравнить скорость загрузки шрифтов через CDN и локальное подключение с помощью
@font-face. - Ознакомиться с тегом
<link rel="preload">для предварительной загрузки ресурсов.
Проанализировать другие возможные оптимизации: minification CSS/JS, lazy-loading изображений, сжатие файлов.
Часть 3: Работа с DOM и поисковая оптимизация веб-страниц
Лабораторная работа 7: Работа с DOM и динамическое изменение контента
- Тема: Динамическое добавление изображений с использованием API
- Задание: Реализовать сайт с галереей изображений с использованием TheCatApiService.
Требования:
- Использовать API для получения изображений и добавления их на страницу.
- Реализовать панель управления для добавления картинок.
- При клике на изображение должен запускаться слайдер с полноразмерным просмотром.
Добавить скелетон-лоадинг для визуализации загрузки контента.
Лабораторная работа 8: Модальные окна
- Тема: Создание модальных окон двумя способами
- Задание: Реализовать два варианта создания модальных окон на сайте:
- С использованием классического CSS и JavaScript.
- С использованием тега
<dialog>.
Требования:
- Создать модальное окно с использованием стилей CSS и JavaScript для его управления.
- Реализовать второй вариант с помощью тега
<dialog>. - Оба окна должны поддерживать закрытие по кнопке или клику вне модального окна.
- Сравнить подходы и сделать выводы.
Лабораторная работа 9: Поисковая оптимизация и настройка отображения в соц. сетях
- Тема: Оптимизация страницы для поисковых систем и социальных сетей
- Задание: Настроить страницу для улучшения SEO и правильного отображения при отправке ссылки в соц. сети.
Требования:
- Добавить мета-теги, связанные с SEO и социальными сетями (например, Open Graph и Twitter Cards).
- Настроить заголовки, описания, ключевые слова и изображения для предпросмотра в социальных сетях.
- Настроить файл
robots.txtиsitemap.xmlдля правильной индексации сайта. - Добавить иконку для сайта.
- Настроить предпросмотр страницы с помощью Open Graph тегов.
Ознакомиться с Яндекс Метрикой и Google Search Console.
Часть 4: Закрепление знаний
Лабораторная работа 10: Закрепление изученного материала
- Тема: Создание полноценного проекта с использованием всех изученных технологий
- Задание: Разработать многостраничный веб-сайт на основе полученных знаний.
Требования:
- Сайт должен быть полностью адаптивным, с использованием Bootstrap 5.
- Реализовать динамическое добавление контента через API.
- Добавить форму обратной связи с валидацией и модальными окнами.
- Произвести оптимизацию загрузки ресурсов и проверить корректность отображения сайта на мобильных устройствах и планшетах.
📘 Установка и настройка Visual Studio Code для веб-разработки на Windows
1. 🛠 Скачивание и установка Visual Studio Code
- Перейдите на официальный сайт Visual Studio Code.
- Нажмите на кнопку Download for Windows.
- Откройте загруженный установочный файл и следуйте инструкциям на экране:
- Примите условия лицензии.
- Выберите папку для установки.
- Опционально: добавьте VS Code в контекстное меню Windows (рекомендуется).
- Нажмите Установить.
- После установки запустите VS Code.
2. 🧩 Установка рекомендуемых расширений
Чтобы сделать работу с VS Code еще более удобной для веб-разработки, рекомендуется установить следующие расширения (не обязательно, но сделает вашу жизнь проще, попробуйте):
2.1. 🛤 Path Intellisense
Это расширение от Christian Kohler автоматически подсказывает пути к файлам и папкам при их написании в вашем коде. Например, при написании пути к изображению оно предложит автозаполнение на основе структуры вашего проекта.
2.2. 🌐 Live Server
Live Server запускает локальный сервер прямо из вашего проекта и автоматически обновляет браузер при изменении файлов HTML, CSS или JavaScript. Это крайне удобно для быстрого тестирования и просмотра изменений в реальном времени.
2.3. 🎨 Catppuccin Theme
Catppuccin — приятная тема, созданная для разработчиков, c приятной палитру цветов, которая снижает нагрузку на глаза и помогает сосредоточиться на работе.
2.4. 🖼 Catppuccin Perfect Icons
Это расширение улучшает и расширяет список иконок для отображения раздичных типов файлов в VS Code, что помогает лучше ориентироваться в структуре файлов проекта.
Список расширений не окончательный, вы всегда можете сами зайти в магазин расширений и установить то, которое сделает вашу работу быстрее и удобнее. Например,
className Completion in CSS,formate: CSS/LESS/SCSS formatterи т.д.
3. 🖥 Настройка среды разработки
3.1. ⚙ Настройка Live Server
После установки Live Server:
- Откройте ваш HTML файл.
- Кликните правой кнопкой мыши по файлу и выберите опцию Open with Live Server.
- Ваш браузер автоматически откроется с локальной версией проекта. Все изменения в файлах будут моментально отображаться.
3.2. 🔄 Настройка автосохранения
Чтобы не терять изменения, активируйте функцию автосохранения:
- Откройте Settings (
Ctrl+,). - В поле поиска введите Auto Save.
- Выберите опцию After Delay или On Window Change для автоматического сохранения файлов.
4. 🎨 Персонализация интерфейса
- После установки Catppuccin Theme перейдите в Settings и выберите тему Catppuccin в разделе Color Theme.
- В разделе иконок выберите стиль иконок Catppuccin Perfect Icons.
5. 📦 Создание первого веб-проекта
Теперь, когда ваша среда настроена, создайте новый проект:
- Создайте папку на вашем компьютере и откройте ее в VS Code.
- Создайте файл index.html и напишите следующий базовый код:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Мой первый проект</title>
</head>
<body>
<h1>Привет, мир!</h1>
</body>
</html>
- Запустите Live Server и откройте проект в браузере.
🎯 Полезные советы
- Используйте сочетание клавиш
Ctrl + Pдля быстрого поиска и открытия файлов.- Для того, чтобы быстро закомментировать и раскомментировать строчку используйте сочетание клавиш
Ctrl + /.- Для глобального поиска текста во всех файлах проекта сразу можно использовать комбинацию
Ctrl + Shift + F.- Установите дополнительные плагины для поддержки Emmet и работы с Git.
- Регулярно обновляйте расширения для получения новых функций и исправлений.
Теоретическая справка
Основные теги, которые используются в HTML
<h1> - <h6>: Заголовки, где<h1>— это заголовок первого уровня (самый крупный), а<h6>— заголовок шестого уровня (самый мелкий).
<h1>Основной заголовок</h1>
<h2>Подзаголовок 1</h2>
<h3>Подзаголовок 2</h3>
<p>: Тег для создания абзацев текста.
<p>Это мой первый параграф.</p>
<p>Это второй параграф, который описывает больше деталей.</p>
<img>: Используется для вставки изображений. Основные атрибуты:src— путь к изображению.alt— альтернативный текст, который будет отображаться, если изображение не загрузилось.
<img src="images/photo.jpg" alt="Мое фото" width="200">
<ul>и<li>: Ненумерованный список (unordered list). Тег<ul>создаёт список, а<li>определяет элементы списка. Для создания нумерованного списка используется тег<ol>.
<ul>
<li>Первый пункт</li>
<li>Второй пункт</li>
<li>Третий пункт</li>
</ul>
<a>: Тег для создания гиперссылок. Основной атрибутhrefуказывает URL, куда будет направлен пользователь при нажатии на ссылку.
<a href="https://www.example.com" target="_blank">Посетить мой сайт</a>
<table>: Используется для создания таблиц. Содержит строки<tr>, а каждая строка — столбцы<td>.
<table border="1">
<tr>
<th>Категория</th>
<th>Описание</th>
</tr>
<tr>
<td>Технические навыки</td>
<td>HTML, CSS, JavaScript</td>
</tr>
<tr>
<td>Управленческие навыки</td>
<td>Коммуникация, тайм-менеджмент</td>
</tr>
</table>
Создание файла index.html
Основной файл HTML имеет следующую базовую структуру:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Сайт</title>
</head>
<body>
<!-- Код сайта -->
</body>
</html>
Описание основных тегов
<!DOCTYPE html>: Определяет тип документа как HTML5. Этот элемент нужен для того, чтобы браузер понял, что ему предстоит работать с HTML5.<html lang="ru">: Корневой элемент документа. Атрибутlang="en"определяет основной язык страницы как английский.<head>: Этот тег содержит метаданные о странице: информацию, которая не видна напрямую пользователю, но необходима для правильной работы страницы.
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Моя визитка</title>
</head>
<meta charset="UTF-8">: Устанавливает кодировку символов для страницы, чтобы поддерживать различные языки, в том числе кириллицу.<meta name="viewport" content="width=device-width, initial-scale=1.0">: Эта строка позволяет странице быть адаптивной, то есть корректно отображаться на мобильных устройствах.<title>: Устанавливает название страницы, которое отображается на вкладке браузера.<body>: Основное содержимое страницы, видимое пользователям, располагается между открывающим и закрывающим тегом<body>. Пример:
<body>
<h1>Привет! Это моя веб-страница.</h1>
<p>Здесь вы узнаете обо мне и моих навыках.</p>
</body>
Базовая структура проекта
Для организации файлов и ресурсов проекта рекомендуется использовать следующую структуру директорий и файлов: `
assets/
css/
js/
images/
fonts/
index.html
- Папка
assets/: Хранит ресурсы, используемые на сайте, такие как CSS, JavaScript, изображения и шрифты.- Папка
css/: Содержит файлы стилей, которые управляют внешним видом веб-страницы. - Папка
js/: Содержит JavaScript-файлы, которые добавляют интерактивность на страницу. - Папка
images/: Хранит изображения, используемые на веб-странице. - Папка
fonts/: Используется для шрифтов, если они загружаются локально.
- Папка
index.html: Главный файл веб-страницы, который содержит разметку страницы и ссылки на внешние ресурсы (CSS, JS).
Практическое задание: Создание веб-страницы визитки
Тема: Создание личного сайта-визитки. Цель: Освоить базовые HTML-теги и создать веб-страницу, которая будет представлять информацию о вас: ваши навыки, образование и контакты. Задание. Создайте личный сайт-визитку с разделами:
- О себе — краткое описание вашей личности или биографии.
- Навыки — перечень ваших ключевых навыков.
- Образование — список учебных заведений или курсов, которые вы окончили.
- Контакты — информация о ваших контактных данных и ссылки на социальные сети.
Требования:
- Использовать теги для организации страницы:
- Заголовки:
<h1>и<h2>для создания разделов. - Параграфы:
<p>для текста. - Изображения:
<img>для вставки фотографии или логотипа. - Списки:
<ul>и<li>для организации информации в виде списка. - Ссылки:
<a>для гиперссылок на внешние ресурсы.
- Заголовки:
- В разделе "Навыки" необходимо использовать таблицу для структурирования информации о ваших технических и управленческих навыках. Таблица должна иметь две колонки: "Категория" и "Навыки".
- Добавьте изображение на страницу с выравниванием по центру и альтернативным текстом, если изображение не загрузится.
- Добавьте ссылки на социальные сети.
Пример структуры HTML-документа
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Моя визитка</title>
</head>
<body>
<h1>О себе</h1>
<p>Привет! Я веб-разработчик с опытом работы в создании современных и адаптивных веб-сайтов.</p>
<h2>Навыки</h2>
<table border="1">
<tr>
<th>Категория</th>
<th>Навыки</th>
</tr>
<tr>
<td>Технические навыки</td>
<td>HTML, CSS, JavaScript</td>
</tr>
<tr>
<td>Управленческие навыки</td>
<td>Управление проектами, коммуникации</td>
</tr>
</table>
<h2>Образование</h2>
<ul>
<li>Университет XYZ, Бакалавр в области информатики</li>
<li>Курсы веб-разработки на платформе ABC</li>
</ul>
<h2>Контакты</h2>
<p>Email: myemail@example.com</p>
<p>Социальные сети:
<a href="https://www.linkedin.com" target="_blank">LinkedIn</a>,
<a href="https://www.github.com" target="_blank">GitHub</a>
</p>
</body>
</html>
Теоретическая справка
Основы CSS и его роль
Cascading Style Sheets (CSS) — это язык стилей, который используется для описания внешнего вида HTML-документов. С помощью CSS можно изменять цвет текста, фон, размеры элементов, отступы, рамки и многое другое. CSS помогает отделить визуальную часть сайта от его структуры.
Примечание: CSS поддерживает различные виды единиц измерения, переменные и медиа-запросы для адаптации сайта под разные экраны.
Где могут указываться стили?
Существует несколько способов добавления стилей на веб-страницу:
-
Внутри тегов с помощью атрибута
style: Этот метод позволяет добавлять стили напрямую к HTML-элементам. Пример:<p style="color: red; font-size: 20px;">Это текст с встроенными стилями</p> -
В секции
<head>с использованием тега<style>: Этот метод применяется для определения стилей в блоке<style>в HTML-документе.<head> ... <style> p { color: red; font-size: 20px; } </style> <head> -
Подключение внешнего файла стилей: Наиболее удобный и распространённый способ. Внешний файл подключается через тег
<link>в секции<head>.<link rel="stylesheet" href="styles.css">
Примечание: При одновременном применении нескольких источников стилей (встроенные, во внешнем файле) действует принцип каскадности: более специфичные стили или стили, указанные позже, переписывают предыдущие. Вложенность элементов также влияет на порядок применения стилей. Например, стили, указанные для родительских элементов, могут быть переписаны стилями для вложенных элементов.
Структура CSS-правил
Каждое правило в CSS состоит из двух частей: селектора и декларации. Селектор указывает элемент, а декларация описывает стилизацию.
Пример CSS-правила:
h1 {
color: blue;
font-size: 24px;
text-align: center;
}
Основные CSS-свойства
Цвет текста (color)
Атрибут color определяет цвет текста элемента. Цвет может быть задан несколькими способами:
- HEX (шестнадцатеричный код):
color: #ff5733; - RGB (Red, Green, Blue):
color: rgb(255, 87, 51); - RGBA (с прозрачностью):
color: rgba(255, 87, 51, 0.5); - Ключевые названия цветов:
color: blue;
Важно: Использование RGBA позволяет задать прозрачность элемента, что полезно для эффектов наложения.
Фон элемента (background)
Атрибут background позволяет задавать различные параметры фона для элемента: цвет, изображение, позиционирование и повторение изображения.
Пример использования:
background: url('background.jpg') no-repeat center center;
background-color: #f0f0f0; /* Цвет фона */
Примечание: С помощью свойства
backgroundможно установить фоновое изображение для элемента и контролировать его поведение, например, запрещая его повторение (no-repeat) или указывая его положение.
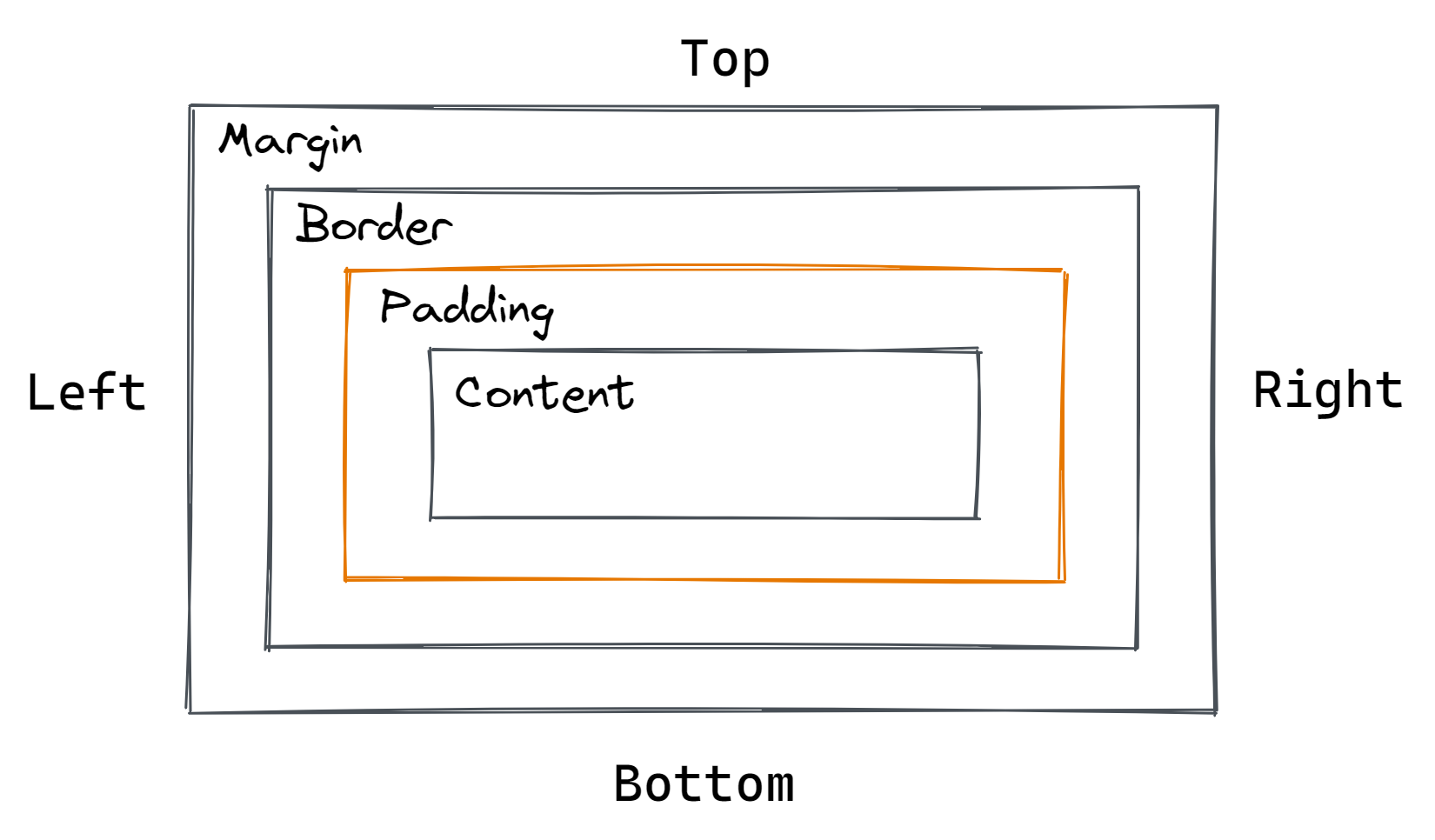
Отступы и поля
margin— внешний отступ:
h1 { margin: 20px; }
padding— внутренний отступ:
p { padding: 10px; }
Общий принцип расположения отступов относительно контента представлен на изображении ниже:
Шрифты и стили текста
font-family: задаёт семейство шрифтов.font-size: размер текста.font-weight: толщина текста.line-height: высота строки.
Пример:
body {
font-family: Arial, sans-serif;
font-size: 16px;
line-height: 1.6;
}
Состояния элементов и ссылки
Элементы могут находиться в различных состояниях. Наиболее часто используются состояния для ссылок:
hover— состояние при наведении курсора.visited— состояние после посещения.active— состояние при нажатии.focus— состояние при фокусировке на элементе.
Пример для ссылок:
a:hover { color: red; }
a:visited { color: purple; }
Примечание: Состояния элементов позволяют стилизовать их в зависимости от действий пользователя.
Типы единиц измерения в CSS
- Абсолютные (
px):
div { width: 200px; }
- Относительные (
em,rem):
p { font-size: 1.5em; }
Почему чаще используются относительные единицы измерения (em и rem)?
Относительные единицы измерения, такие как em и rem, становятся предпочтительными по нескольким причинам:
- Адаптивность: Относительные единицы масштабируются относительно родительских элементов (
em) или корневого элемента (rem), что делает их удобными для создания адаптивных макетов. - Поддержка доступности: Пользователи могут изменять размер текста в браузере, и относительные единицы лучше реагируют на такие изменения.
- Гибкость: С помощью относительных единиц можно легко изменить размеры элементов при масштабировании, сохраняя пропорции.
Пример использования:
p {
font-size: 1.5em; /* Размер текста относительно родителя */
}
h1 {
font-size: 2rem; /* Размер относительно корневого элемента */
}
Примечание:
remиспользуется чаще для определения глобальных размеров, аem— для локальной настройки шрифтов и отступов.
Навигационные панели
Навигация на веб-страницах создаётся для удобного перемещения между разделами сайта. Чаще всего для создания навигации используется список ссылок, стилизованный с помощью CSS.
Пример структуры навигации:
<nav>
<ul>
<li><a href="#about">О себе</a></li>
<li><a href="#skills">Навыки</a></li>
<li><a href="#education">Образование</a></li>
<li><a href="#contacts">Контакты</a></li>
</ul>
</nav>
Практическое задание: Стилизация сайта и создание навигации
Тема: Стилизация сайта с использованием CSS и создание навигационного меню Цель: Освоить основные свойства CSS для стилизации веб-страницы и создать удобное навигационное меню. Задание:
- Подключить внешний CSS-файл к HTML-документу.
- Стилизовать следующие элементы:
- Заголовки: изменить цвет и размер.
- Абзацы: задать отступы и изменить цвет текста.
- Применить
paddingиmarginдля улучшения визуального восприятия элементов.
Пример сайта с подключенными стилями и навигационной панелью:
Примечание: Ознакомтесь со способами изменения положения контента на странице. Например, один из способов центрировать контент - использовать
margin: 0 auto;. Таким образом мы установим внешний отступ сверху и снизу равным 0, а по бокам все доступное пространство поровну распределится между отступом слева и справа.
Теоретическая справка
Что такое JavaScript?
JavaScript (JS) — это язык программирования, исполняемый на стороне клиента (в браузере). Он позволяет добавлять интерактивность на веб-страницы, управлять поведением элементов, выполнять операции с данными, отправлять запросы на сервер и многое другое. JavaScript — интерпретируемый язык, то есть он не требует предварительной компиляции и исполняется непосредственно в браузере.
При изучении и поиске информации по JS рекомендую обращаться к этому онлайн-учебнику. У него довольно неплохие примеры и информация поддерживается в актуальном состоянии. Русский язык поддерживается.
Переменные и типы данных в JavaScript
В JavaScript можно объявлять переменные с помощью ключевых слов var, let и const. Типы данных, с которыми работают переменные, можно разделить на примитивные и сложные.
Примитивные типы данных:
- Числа (Number) — могут быть целыми или дробными:
let x = 10;
let pi = 3.14;
- Строки (String) — используются для хранения текста:
let greeting = "Привет, мир!";
- Булевы значения (Boolean) — логический тип данных с двумя возможными значениями:
trueилиfalse:
let isAdmin = false;
- Undefined — переменная, которой не было присвоено значение:
let user;
- Null — явное отсутствие значения:
let emptyValue = null;
- Symbol — уникальные и неизменяемые значения, полезные для создания уникальных идентификаторов.
Сложные типы данных:
- Объекты (Object) — структуры, которые могут хранить множество значений в виде пар "ключ-значение":
let person = {
name: "Иван",
age: 25
};
- Массивы (Array) — это упорядоченные коллекции данных:
let fruits = ["яблоко", "банан", "вишня"];
Пример работы с типами данных:
let number = 5;
let text = "Привет!";
let isValid = true;
let fruits = ["яблоко", "банан"];
number = number + 10; // Изменение значения переменной
text = text + " Как дела?"; // Конкатенация строк
console.log(number); // 15
console.log(text); // "Привет! Как дела?"
console.log(fruits[1]); // "банан"
Функции
Функции — это блоки кода, которые можно вызывать для выполнения определённой задачи. Они могут принимать параметры и возвращать значения.
Пример функции:
function calculateSum(a, b) {
return a + b;
}
let result = calculateSum(5, 3); // 8
С приходом ES6 функции можно создавать с помощью стрелочных функций:
Пример стрелочной функции:
const multiply = (a, b) => a * b;
console.log(multiply(2, 4)); // 8
Нововведения в ES6
С введением ECMAScript 6 (ES6) JavaScript получил множество новых удобных функций и возможностей:
- Шаблонные строки — позволяют использовать интерполяцию переменных:
let name = "Иван";
console.log(`Привет, ${name}!`);
- Деструктуризация — упрощает доступ к данным массивов и объектов:
let [a, b] = [1, 2];
let {name, age} = {name: "Иван", age: 25};
- Операторы "let" и "const" — для объявления переменных с блочной областью видимости:
let count = 10; // Переменная, которую можно изменить
const PI = 3.14; // Константа, значение которой изменить нельзя
- Модули — возможность разделять код на отдельные файлы и импортировать их:
export const greet = (name) => `Привет, ${name}!`;
import { greet } from './greet.js';
- Классы — синтаксический сахар для создания объектов:
class Animal {
constructor(name) {
this.name = name;
}
speak() {
console.log(`${this.name} издаёт звук.`);
}
}
let dog = new Animal("Собака");
dog.speak(); // "Собака издаёт звук."
Document Object Model (DOM)
DOM — это представление HTML-документа в виде дерева объектов, где каждый элемент страницы является узлом. JavaScript позволяет взаимодействовать с DOM для динамического изменения содержимого страницы, изменения стилей, добавления или удаления элементов.
Основные методы работы с DOM:
-
Поиск элементов:
document.getElementById("id")— поиск по идентификатору.document.querySelector(".class")— поиск по селектору.
Пример:
let element = document.getElementById("header"); -
Изменение содержимого:
element.innerText— изменяет текст внутри элемента.element.innerHTML— изменяет HTML внутри элемента.
Пример:
document.getElementById("header").innerText = "Новый заголовок"; -
Изменение стилей:
element.style.property— изменяет CSS-свойства элемента.
Пример:
document.getElementById("header").style.color = "red"; -
Добавление и удаление элементов:
document.createElement("div")— создание нового элемента.parent.appendChild(child)— добавление элемента в DOM.
Пример:
let newDiv = document.createElement("div"); newDiv.innerText = "Новый элемент"; document.body.appendChild(newDiv); -
Обработка событий:
Использование
addEventListener()для обработки событий (например, нажатие кнопки).Пример:
document.getElementById("button").addEventListener("click", function() { alert("Кнопка нажата!"); });
Формы в HTML
Форма — это элемент HTML, который позволяет пользователям вводить и отправлять данные на сервер для обработки. Основные элементы формы включают в себя текстовые поля, кнопки, переключатели и другие элементы управления.
Пример формы:
<form action="/submit" method="POST">
<label for="name">Имя:</label>
<input type="text" id="name" name="name"><br><br>
<label for="email">Email:</label>
<input type="email" id="email" name="email"><br><br>
<button type="submit">Отправить</button>
</form>
<form>— контейнер для элементов формы.<input>— элементы для ввода данных (текст, email, пароль и т.д.).<textarea>— многострочный текстовый ввод.<button>— кнопка для отправки формы.
Обработка данных формы
JavaScript позволяет перехватывать отправку формы и обрабатывать введённые данные до того, как они будут отправлены на сервер.
Пример валидации формы с JavaScript:
document.querySelector("form").addEventListener("submit", function(event) {
event.preventDefault(); // Отключаем стандартную отправку формы
let name = document.getElementById("name").value;
let email = document.getElementById("email").value;
if (name === "" || email === "") {
alert("Пожалуйста, заполните все поля!");
} else if (!email.includes("@")) {
alert("Введите корректный email!");
} else {
alert("Форма успешно отправлена!");
}
});
Практическое задание: Реализация формы обратной связи с валидацией
Цель: Научиться работать с формами и данными, введёнными пользователем. Освоить основные методы JavaScript для проверки данных формы.
Задание:
- Создайте форму с полями для ввода имени, email и сообщения.
- Используйте JavaScript для проверки, что все поля заполнены корректно:
- Имя не должно быть пустым.
- Email должен быть корректным.
- Сообщение должно содержать хотя бы 10 символов.
- При успешной отправке формы выведите сообщение об успешной отправке. При ошибке выведите предупреждение с указанием, что необходимо исправить.
Пример веб-страницы с валидацией формы при помощи JavaScript:
Самостоятельное задание
Часть 1: Расширенная форма с валидацией и динамическими элементами
Пользователь вводит данные в форму, видит подсказки о количестве символов в комментарии, может добавить новые интересы через динамические поля, и после валидации данные выводятся на экран.
Форма опроса
Создайте HTML-форму для опроса, которая включает следующие элементы:
- Поле для ввода имени.
- Поле для ввода возраста.
- Переключатели (radio buttons) для выбора пола.
- Чекбоксы для указания интересов (например, спорт, музыка, кино).
- Многострочное текстовое поле для комментариев с отображением текущего количества введённых символов и лимитом в 200 символов.
- Кнопка для динамического добавления новых полей для ввода интересов.
Валидация формы
- Имя не должно быть пустым.
- Возраст должен быть числом больше 0 и не старше 120.
- Пользователь должен выбрать хотя бы один интерес.
- Комментарий не должен превышать 200 символов.
- Валидация новых полей, добавленных динамически.
Вывод данных формы
После успешной валидации формы выведите введённые данные на экран в структурированном виде:
- Имя
- Возраст
- Пол
- Интересы
- Комментарии
Добавьте кнопку для динамического добавления полей для ввода новых интересов без перезагрузки страницы.
Один из вариантов реализации:
document.getElementById("addInterest").addEventListener("click", function() {
let newInterest = document.createElement("input");
newInterest.setAttribute("type", "text");
newInterest.setAttribute("name", "interest");
newInterest.setAttribute("placeholder", "Новый интерес");
let interestList = document.getElementById("interestList");
interestList.appendChild(newInterest);
});
Подсчёт символов
Реализуйте подсчёт символов в реальном времени для текстового поля комментариев и покажите пользователю, сколько символов осталось до лимита.
Часть 2: Работа с элементами страницы и манипуляция DOM
Создание интерфейса для управления списком задач (to-do list), который позволяет добавлять, удалять и отмечать задачи.
Создание списка задач
Создайте интерфейс для управления задачами (to-do list). На странице должно быть:
- Поле для ввода новой задачи.
- Кнопка для добавления задачи в список.
- Динамически обновляющийся список задач.
Перечень взаимодействий, которые необходимо реализовать:
- Удаление задачи из списка.
- Отметки задачи как выполненной. При этом стиль задачи должен меняться (например, зачеркивание текста или изменение фона).
- Кнопка для фильтрации задач, чтобы пользователь мог скрывать выполненные задачи и показывать только оставшиеся.
Вариант JS кода для создания списка задач
document.getElementById("addTask").addEventListener("click", function() {
let taskInput = document.getElementById("taskInput").value;
if (taskInput === "") return;
let taskList = document.getElementById("taskList");
let taskItem = document.createElement("li");
taskItem.innerText = taskInput;
// Добавление кнопки удаления задачи
let deleteButton = document.createElement("button");
deleteButton.innerText = "Удалить";
deleteButton.addEventListener("click", function() {
taskList.removeChild(taskItem);
});
taskItem.appendChild(deleteButton);
taskList.appendChild(taskItem);
// Очистка поля ввода
document.getElementById("taskInput").value = "";
});
Визуализация логики работы:
Анимация
Добавьте анимацию при добавлении и удалении задач, чтобы элементы плавно появлялись и исчезали. Ознакомиться с простым гайдом по созданию переходов и анимаций можно в этом видеоролике.
Задачи на дополнительные баллы
- Создайте выпадающее меню. Реализуйте выпадающее меню с использованием JavaScript, которое отображается при наведении на элемент и исчезает при отведении курсора.
- Подключите локальное хранилище. Добавьте сохранение списка задач в LocalStorage, чтобы после перезагрузки страницы задачи оставались на месте.
Теоретическая справка
С тем что такое CSS и с примитивными принципами его работы мы знакомились в Лабороторной №2
Позиционирование элементов
Позиционирование в CSS — это механизм, который позволяет точно указывать, где элементы будут располагаться на странице.
В CSS позиционирование управляет расположением элементов относительно других элементов или родительских контейнеров. Свойство position задаёт способ позиционирования элемента на странице, а свойства top, right, bottom и left определяют точное смещение элементов на странице.
Синтаксис
position: static;
position: relative;
position: absolute;
position: fixed;
position: sticky;
/* Глобальные значения */
position: inherit;
position: initial;
position: revert;
position: unset;
Каждое значение свойства position имеет свои особенности, которые определяют, как элемент будет взаимодействовать с другими элементами на странице.
Static (Статическое позиционирование)
Значение по умолчанию. Элементы, у которых установлено это значение, располагаются в потоке документа по мере их появления в HTML-разметке. Свойства top, left, right, и bottom не применяются.
Особенности:
- Элемент находится в нормальном потоке документа.
- Свойства смещения не оказывают влияния.
- Не создаёт новый контекст наложения (stacking context).
Пример:
В данном примере блок с классом
.staticбудет располагаться в потоке документа на своём обычном месте.
Relative (Относительное позиционирование)
Относительное позиционирование позволяет смещать элемент относительно его исходного положения в нормальном потоке документа. Элемент остаётся в потоке, и место под него сохраняется, но визуально он может быть смещён.
Особенности:
- Элемент остаётся на своём месте в потоке.
- Свойства
top,right,bottom, иleftсмещают элемент относительно его исходного положения. - Создаёт новый контекст наложения, если установлен
z-index.
Пример:
В этом примере блок с классом
.relativeсмещён вниз на 20px и вправо на 30px, при этом место под ним остаётся неизменным.
Absolute (Абсолютное позиционирование)
Абсолютное позиционирование позволяет полностью удалить элемент из нормального потока документа. Элемент позиционируется относительно ближайшего родителя, у которого установлено значение position, отличное от static. Если такого родителя нет, элемент будет позиционироваться относительно окна браузера.
Особенности:
- Элемент удаляется из нормального потока.
- Позиционируется относительно ближайшего позиционированного родителя.
- Создаёт новый контекст наложения, если установлен
z-index.
Пример:
Здесь элемент с классом
.absoluteбудет позиционироваться относительно его родителя с классом.relativeи смещён на 50px вниз и на 20px вправо. Родитель остаётся в потоке, но дочерний элемент — нет.
Fixed (Фиксированное позиционирование)
Фиксированное позиционирование удаляет элемент из потока и закрепляет его относительно окна браузера. Элемент остаётся на одном месте на экране при прокрутке страницы.
Особенности:
- Элемент позиционируется относительно окна браузера.
- Не изменяет своё положение при прокрутке.
- Создаёт новый контекст наложения, если установлен
z-index.
Пример:
Элемент с классом
.fixedбудет закреплён в правом верхнем углу и останется на одном месте при прокрутке страницы.
Sticky (Липкое позиционирование)
Липкое позиционирование совмещает поведение статического и фиксированного позиционирования. Элемент сначала ведёт себя как обычный, но при прокрутке "залипает" на экране, если достигается определённая точка.
Особенности:
- Элемент ведёт себя как обычный, пока не достигнет порога прокрутки.
- После достижения порога элемент фиксируется в пределах родителя или экрана.
- Создаёт новый контекст наложения, если установлен
z-index.
Пример:
В этом примере элемент с классом
.stickyбудет оставаться на месте, пока не достигнет верхней границы окна браузера, а затем "прилипнет" к ней при дальнейшей прокрутке.
Глобальные значения
inherit (Наследование)
Элемент наследует значение свойства position от своего родителя.
.child {
position: inherit;
}
initial (Инициализация)
Элемент возвращается к начальному значению свойства, как если бы оно не было установлено.
.child {
position: initial;
}
revert (Отмена изменений)
Элемент возвращает значение свойства к тому, что оно было бы, если бы не было изменений.
.child {
position: revert;
}
unset (Сброс)
Элемент получает либо наследуемое значение, если оно наследуемое, либо начальное значение.
.child {
position: unset;
}
Контейнеры: Flexbox и Grid
Flexbox
Flexbox используется для создания одномерных макетов, где элементы располагаются в строке или столбце. Основное преимущество Flexbox состоит в его способности адаптировать содержимое контейнера к доступному пространству.
Синтаксис
.container {
display: flex;
justify-content: space-between;
align-items: center;
}
Основные свойства Flexbox:
display: flex— активирует flex-контейнер.flex-direction— задает направление главной оси (строка или столбец).justify-content— управляет выравниванием элементов по главной оси.align-items— выравнивает элементы вдоль поперечной оси.
Пример использования Flexbox:
Перед тем как приступить к практической части настоятельно рекомендую всем ознакомиться с интерактивной шпаргалкой, в которой представлены все основные свойства использующиеся в Flexbox. Ссылка на шпаргалку: Типичный верстальщик: Шпаргалка по Flexbox CSS.
Для более подробного ознакомления с контейнерами рекомендуется на выбор пройти одну из интерактивных игр:
- Более интрересное визуальное оформление, больше информации. Единственный нюанс, что поддерживается только английский язык. Ссылка: Flex Box Adventure.
- Чуть более упрощенный вариант. Есть поддержка русского языка. Ссылка: Flexbox Froggy.
Grid
CSS Grid — это мощная система для создания двухмерных макетов. В отличие от Flexbox, Grid позволяет работать как с рядами, так и с колонками одновременно, создавая сложные макеты.
Синтаксис
.container {
display: grid;
grid-template-columns: repeat(3, 1fr);
gap: 10px;
}
Основные свойства Grid:
display: grid— активирует Grid-контейнер.grid-template-columns— определяет количество и ширину колонок.grid-template-rows— определяет количество и высоту строк.gap— управляет расстоянием между элементами Grid.
Пример использования Grid:
Интерактивная шпаргалка от тех же авторов, что и по Flexbox: Типичный верстальщик: Шпаргалка по Grid CSS.
Для изучения Grid также есть интерактивные игры, которые позволяют глубже понять и закрепить принципы позиционирования контента с её использованием:
- Ссылка на более интересный и обширный вариант на английском языке: Grid Attack.
- Вариант на русском языке от создателей Flexbox Froggy: Grid Garden.
Анимации в CSS
CSS предлагает мощные инструменты для создания анимаций, и самым базовым из них является CSS-transition. При помощи переходов, которые они создают, можно постепенно изменять свойства элементов.
Внизу представлена только краткая выдержка и справка, которая была сформирована на основе этой статьи. Дома рекомендую вам ознакомиться с ней целиком, материал хорошо структурирован и присутствуют интерактивные примеры.
Основы CSS-transition
Транзишны позволяют анимировать изменение свойств элементов, например, перемещение или изменение цвета.
Пример
При наведении курсора кнопка плавно смещается вверх за 250 миллисекунд.
Синтаксис
transition: <свойство> <длительность> <функция-времени> <задержка>;
- Свойство – свойство, которое изменяется.
- Длительность – время выполнения анимации (в мс).
- Функция-времени – характер анимации (например,
linear,ease-in). - Задержка – время до начала анимации.
Функции времени
Функции времени управляют тем, как изменяется свойство:
-
linear– равномерное изменение.transition-timing-function: linear; -
ease– плавное ускорение в начале и замедление в конце (по умолчанию). -
ease-in– медленное начало, быстрое завершение.transition-timing-function: ease-in; -
ease-out– быстрое начало, медленное завершение.transition-timing-function: ease-out; -
ease-in-out– комбинацияease-inиease-out.transition-timing-function: ease-in-out; -
Кастомная кривая Безье для создания уникальных анимаций:
transition-timing-function: cubic-bezier(0.25, 0.1, 0.25, 1);
Производительность анимаций
Важно следить за производительностью, особенно при анимации свойств, влияющих на расположение элементов (height, width). Они могут замедлять работу интерфейса.
Советы:
- Анимируйте свойства, которые минимально влияют на другие элементы, например,
transformилиopacity. - Тестируйте анимации на слабых устройствах.
Можно анимировать сразу несколько свойств:
.btn { transition: transform 250ms, opacity 400ms; }
Учет предпочтений пользователей
Для пользователей с чувствительностью к движениям рекомендуется учитывать системные настройки и отключать анимации, если включен режим prefers-reduced-motion:
@media (prefers-reduced-motion: reduce) {
.btn {
transition: none;
}
}
Пример комплексной анимации
В данном примере при наведении курсора элемент быстро поднимается, а при уходе медленно опускается, что создает более естественное ощущение.
Более сложные и комплексные анимации можно создавать при помощи keyframes. Ознакомиться с тем что это такое можно в руководстве по ссылке.
Закрепление
В качестве повторения рассмотренного материала с анимациями предлагаю ознакомиться с со справкой на сайте Javascript.ru и решить 4 тестовых задачи, которые находятся внизу страницы. Ссылка: CSS-анимации.
Медиазапросы
Медиазапросы позволяют задавать разные стили для разных устройств.
@media (max-width: 768px) {
.container {
flex-direction: column;
}
}
Пример веб-страницы с позиционированием и контейнерами
Практическое задание: Верстка веб-страницы по шаблону
Цель: Закрепить навыки по верстке, адаптивному дизайну и работе с компонентами на примере личного сайта разработчика. Студенты научатся создавать адаптивные страницы для различных устройств и использовать компоненты с разными состояниями.
Задание. Создайте веб-страницу личного сайта разработчика по предоставленным макетам. Требования к верстке:
- Корректное отображение на разных экранах (десктопная и мобильная версия).
- Должны быть отображены рзличные состояния компонентов (нажатие, ввод, ошибки).
- Убедитесь, что все интерактивные элементы, такие как ссылки и кнопки, работают корректно. Примеры:
- Поля ввода для имени и сообщения.
- Кнопки для отправки сообщений и ссылки на социальные сети.
- Не забываем подключать нужный шрифт и следить за отступами.
Шрифт, который используется на сайте, можно загрузить по ссылке.
Макеты для верстки: используется Фигма, с проектом можно ознакомиться по ссылке.
Пример того что у вас должно получиться:

Введение в Bootstrap 5
Bootstrap 5 — это мощный CSS-фреймворк, который облегчает создание адаптивных и мобильных веб-сайтов. Он включает различные компоненты, утилиты и шаблоны, которые помогают разработчикам быстро создавать интерфейсы.
Подключение Bootstrap к проекту
Чтобы использовать Bootstrap в вашем проекте, необходимо подключить CSS и JS-файлы. Это можно сделать через CDN или локально, скачав файлы с официального сайта.
Подключение через CDN
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap Example</title>
<!-- Bootstrap CSS -->
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.3/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-QWTKZyjpPEjISv5WaRU9OFeRpok6YctnYmDr5pNlyT2bRjXh0JMhjY6hW+ALEwIH" crossorigin="anonymous">
</head>
<body>
<!-- Ваш контент -->
<!-- Bootstrap JS -->
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.3/dist/js/bootstrap.bundle.min.js" integrity="sha384-YvpcrYf0tY3lHB60NNkmXc5s9fDVZLESaAA55NDzOxhy9GkcIdslK1eN7N6jIeHz" crossorigin="anonymous"></script>
</body>
</html>
Для подробного ознакомления с другими элементами и возможностями Bootstrap можно посетить официальный сайт здесь.
Сеточная система Bootstrap
Сеточная система Bootstrap состоит из контейнеров, строк и колонок. Она поддерживает адаптивные макеты с использованием брейкпоинтов, которые автоматически подстраиваются под размер экрана. Это позволяет создавать как фиксированные, так и гибкие макеты.
Колонки и брейкпоинты
Колонки в Bootstrap работают на основе 12-колоночной сетки. Они адаптируются к разным брейкпоинтам, что позволяет легко управлять адаптивностью макетов.
Пример использования брейкпоинтов:
<div class="container">
<div class="row">
<div class="col-sm-6 col-md-4 col-lg-3">Контент</div>
<div class="col-sm-6 col-md-4 col-lg-3">Контент</div>
</div>
</div>
Таблица брейкпоинтов:
| Размер экрана | Минимальная ширина | Класс |
|---|---|---|
| Extra small (xs) | < 576px | .col- |
| Small (sm) | ≥ 576px | .col-sm- |
| Medium (md) | ≥ 768px | .col-md- |
| Large (lg) | ≥ 992px | .col-lg- |
| Extra large (xl) | ≥ 1200px | .col-xl- |
| Extra extra large | ≥ 1400px | .col-xxl- |
Типы контейнеров
В Bootstrap есть несколько типов контейнеров:
.container: имеет фиксированную ширину для каждого брейкпоинта..container-fluid: занимает 100% ширины экрана на любом устройстве..container-{breakpoint}: фиксированная ширина, адаптируемая к определенному брейкпоинту, например,.container-md.
Пример:
<div class="container">
<div class="row">
<div class="col">Колонка 1</div>
<div class="col">Колонка 2</div>
</div>
</div>
Компоненты Bootstrap
Bootstrap предоставляет большой набор готовых компонентов для создания современных интерфейсов. Рассмотрим некоторые из них более подробно.
Кнопки и их состояния
Кнопки в Bootstrap — это один из самых популярных элементов. Они легко стилизуются и могут принимать различные состояния. Стилизация кнопок достигается добавлением различных классов.
Основные стили кнопок:
<button type="button" class="btn btn-primary">Primary</button>
<button type="button" class="btn btn-secondary">Secondary</button>
<button type="button" class="btn btn-success">Success</button>
<button type="button" class="btn btn-danger">Danger</button>
...
Кроме основных стилей, кнопки могут находиться в различных состояниях:
- Active: делает кнопку активной. Пример:
class="btn btn-primary active". - Disabled: делает кнопку неактивной (недоступной). Пример:
class="btn btn-primary" disabled. - Outline: кнопки с рамкой и прозрачным фоном. Пример:
class="btn btn-outline-primary".
Пример с активной и неактивной кнопками:
<button type="button" class="btn btn-primary active" aria-pressed="true">Активная</button>
<button type="button" class="btn btn-secondary" disabled>Неактивная</button>
Модальные окна
Модальные окна — это всплывающие диалоговые окна, которые позволяют взаимодействовать с пользователем. Их можно использовать для подтверждений, ввода данных или показа дополнительной информации.
Пример модального окна:
Другие компоненты
Bootstrap также предоставляет множество других полезных компонентов, таких как навигационные панели, карточки, формы, уведомления и многое другое.
Для более подробного изучения всех компонентов и их возможностей посетите официальную документацию Bootstrap
Практическое задание: Адаптивный лендинг с использованием Bootstrap
Цель этого задания — познакомиться с возможностями Bootstrap и научиться использовать его для создания адаптивных веб-сайтов. Задание разделено на две части: первая для знакомства с основными возможностями Bootstrap, вторая — для создания более сложного проекта.
Часть 1: Знакомство с Bootstrap
Ваша задача — восстановить внешний вид и функционал сайта на основе предоставленной DOM модели, используя Bootstrap. Это задание поможет вам освоить стилизацию и компоненты Bootstrap для создания современных и адаптивных веб-страниц.
Файл с DOM моделью можно загузить по ссылке
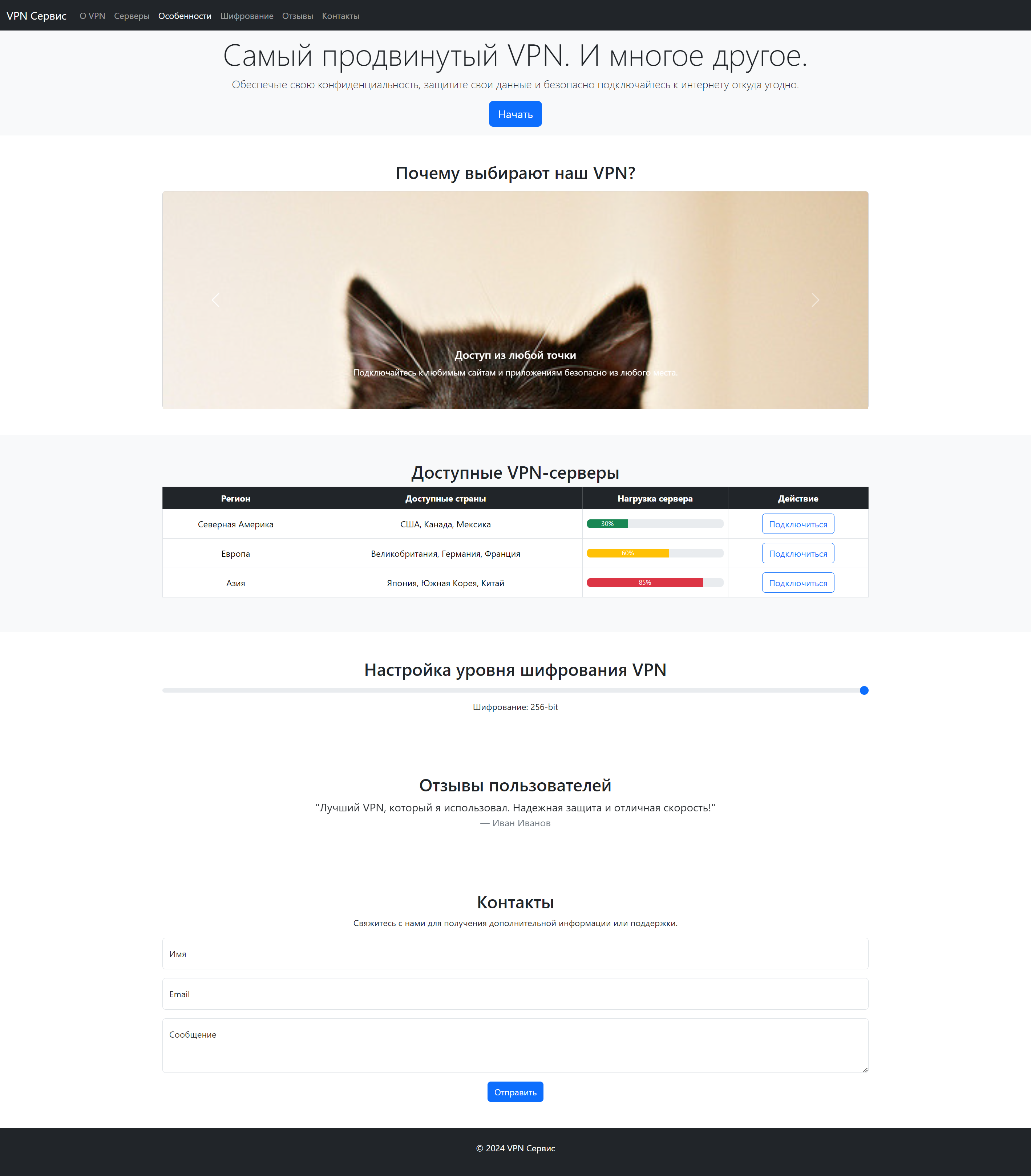
На что нужно обратить внимание:
- Навигация
- Добавьте классы Bootstrap для панели навигации.
- Используйте navbar с темной темой и классами
navbar-expand-lg,bg-darkиfixed-top. - Обеспечьте адаптивность меню с помощью collapse и toggler элементов.
- Главная секция
- Примените классы для выравнивания текста в центре (например,
text-center). - Добавьте отступы с помощью классов py-3 и mt-5 для соответствия исходной верстке.
- Используйте стили для кнопки btn, btn-primary, btn-lg.
- Карусель с изображениями
- Используйте компонент Carousel для создания слайд-шоу.
- Убедитесь, что изображения занимают полную ширину и высоту с помощью классов card, card-img-top.
- Добавьте кнопки prev и next для управления каруселью, используя классы carousel-control-prev и carousel-control-next.
- Таблица с VPN серверами
- Используйте таблицу с классами Bootstrap
tableиtable-bordered. - Включите стили progress bar для отображения нагрузки на серверы.
- Для выравнивания текста используйте классы align-middle.
- Настройка шифрования VPN
- Добавьте компонент range input с использованием стиля form-range для настройки уровня шифрования.
- Обновляйте отображение выбранного значения с помощью JavaScript.
- Отзывы пользователей
- Воспользуйтесь компонентом Carousel для переключения отзывов пользователей.
- Используйте стили blockquote и blockquote-footer для создания отзывов.
- Убедитесь, что слайдер работает плавно, и отзывы не накладываются друг на друга.
- Форма контактов
- Примените floating labels для полей ввода формы.
- Добавьте валидацию формы с использованием Bootstrap классов was-validated, is-invalid и is-valid.
- Поля формы должны быть адаптивными и удобными для ввода.
Дополнительные требования
- Валидация формы
- Реализуйте клиентскую валидацию формы, используя встроенные стили Bootstrap для валидации (
.was-validated,.invalid-feedback).
- Scrollspy
- Добавьте функциональность scrollspy, чтобы подсвечивать активные ссылки навигации в зависимости от прокручиваемой секции.
Часть 2: Создание проекта (доп. задание)
У вас есть два варианта для выполнения этой части задания:
-
Создание сайта на выбранную вами тематику: Например, вы можете выбрать тему любимой музыкальной группы, фильма или другого хобби. Необходимо разработать уникальное наполнение для своего сайта, чтобы результат отличался у всех.
-
Верстка сайта по шаблону: Используйте следующий шаблон с Figma: ссылка на шаблон. Если вы решите верстать по шаблону, обратите внимание, что если просто скопировать код, это будет сразу выделяться, так как вы ещё не изучили все технологии, использованные в оригинальной верстке.
Дополнительные требования:
- Проверьте работу сайта на всех популярных размерах экрана, начиная от мобильных телефонов до больших мониторов.
- При успешной отправке формы должно появляться сообщение об успехе, при ошибке — предупреждение.
- Обратите внимание на использование иконок и кнопок, применяйте их стилизацию с помощью Bootstrap.
Теоретическая справка
1. Адаптивный дизайн и медиазапросы (повторение)
Адаптивный дизайн позволяет контенту сайта автоматически подстраиваться под различные устройства. Медиазапросы применяются для изменения стилей в зависимости от характеристик устройства.
Пример базового медиазапроса:
@media (max-width: 600px) {
.menu {
display: none;
}
}
2. Специальные медиазапросы
2.1. @media (hover: hover) and (pointer: fine)
Этот медиазапрос используется для определения устройств, которые поддерживают указатель с высокой точностью (например, мышь) и могут обрабатывать события наведения.
Пример:
@media (hover: hover) and (pointer: fine) {
.button:hover {
background-color: lightblue;
}
}
2.2. @media (prefers-color-scheme: dark)
Этот медиазапрос позволяет определить, предпочитает ли пользователь темную или светлую тему интерфейса. Совместно с использованием CSS переменных и атрибута color-scheme можно легко переключать темы.
Пример использования темной и светлой темы с CSS переменными:
/* Определение CSS переменных для светлой темы */
:root {
--background-color: white;
--text-color: black;
}
/* Определение CSS переменных для темной темы */
@media (prefers-color-scheme: dark) {
:root {
--background-color: black;
--text-color: white;
}
}
/* Применение цветов через CSS переменные */
body {
background-color: var(--background-color);
color: var(--text-color);
color-scheme: light dark; /* Поддержка встроенной темной и светлой схемы */
}
3. Оптимизация изображений
Оптимизация изображений помогает сократить объем передаваемых данных, что ускоряет загрузку веб-страниц и снижает нагрузку на сервер.
Методы оптимизации изображений:
-
Использование формата WebP: Формат WebP, разработанный Google, позволяет сжимать изображения с потерями и без потерь, сохраняя высокое качество при меньшем размере файлов.
Пример кода с использованием WebP:
<picture> <source srcset="image.webp" type="image/webp"> <img src="image.jpg" alt="Описание изображения"> </picture> -
Lazy-loading: Отложенная загрузка изображений помогает загружать только те изображения, которые пользователь видит на экране, снижая нагрузку на сеть и ускоряя загрузку страницы.
Пример использования lazy-loading:
<img src="image.webp" loading="lazy" alt="Описание изображения"> -
Адаптивные изображения (
srcsetиsizes): Использование атрибутовsrcsetиsizesпозволяет браузеру выбирать наиболее подходящее изображение в зависимости от устройства и разрешения экрана.Пример адаптивных изображений:
<img src="image-small.jpg" srcset="image-large.jpg 1024w, image-medium.jpg 640w, image-small.jpg 320w" sizes="(max-width: 600px) 100vw, 50vw" alt="Адаптивное изображение">
4. Подключение шрифтов: CDN vs. локальное подключение
Шрифты могут оказывать значительное влияние на скорость загрузки сайта, поэтому важно выбирать правильный метод подключения.
1. Подключение через CDN:
- Преимущества:
- Кэширование: Пользователи могут загружать шрифты быстрее, если они уже закэшированы у них из-за посещения других сайтов, использующих тот же CDN.
- Глобальная доступность: CDN размещают ресурсы на серверах по всему миру, обеспечивая быструю загрузку независимо от местоположения пользователя.
- Недостатки:
- Зависимость от сторонних сервисов: Если CDN выходит из строя, шрифты могут не загрузиться.
- Конфиденциальность: Загрузка шрифтов с внешних источников может отслеживаться третьими сторонами.
Пример подключения шрифта через CDN:
<link href="https://fonts.googleapis.com/css2?family=Roboto&display=swap" rel="stylesheet">
2. Локальное подключение шрифтов:
- Преимущества:
- Контроль: Шрифты загружаются с вашего сервера, что снижает зависимость от внешних сервисов.
- Гибкость: Вы можете оптимизировать и изменять шрифты по своему усмотрению.
- Недостатки:
- Требует оптимизации: Без сжатия и подгонки подмножества символов размер файлов шрифтов может быть значительным.
Пример подключения локального шрифта с использованием @font-face:
@font-face {
font-family: 'MyFont';
src: url('fonts/MyFont.woff2') format('woff2');
font-weight: normal;
font-style: normal;
}
body {
font-family: 'MyFont', sans-serif;
}
Оптимизация шрифтов:
- Подмножества шрифтов: Создание шрифтов, содержащих только необходимые символы, уменьшает размер файла.
- Атрибут
font-display: Использование значенияswapобеспечивает немедленное отображение текста с системным шрифтом, пока загружается основной шрифт.
5. Использование <link rel="preload">
Тег <link rel="preload"> помогает браузеру заранее загружать важные ресурсы, улучшая время рендеринга страницы.
Как работает preload:
- Ресурсы, загруженные с использованием
preload, загружаются параллельно с основным контентом страницы, что ускоряет их доступность. - Атрибут
asуказывает тип ресурса (например,font,image,script), чтобы браузер мог правильно приоритизировать загрузку.
Пример предварительной загрузки шрифта:
<link rel="preload" href="fonts/MyFont.woff2" as="font" type="font/woff2" crossorigin>
Примеры использования:
- Изображения: Ускоряет отображение изображений, которые должны быть загружены сразу (логотип).
- Скрипты: Использование
preloadдля JavaScript помогает избежать задержек выполнения критических скриптов.
Практическое задание
Создать адаптивный сайт на тему "Виртуальный музей искусства". Сайт должен представлять коллекцию художественных произведений с различными секциями, такими как "Картины", "Скульптуры", "Современное искусство" и "Интерактивные выставки".
Задание: Оптимизация сайта на тему "Виртуальный музей искусства"
- Адаптировать макет сайта для мобильных устройств и планшетов, используя медиазапросы.
- Оптимизировать изображения, заменив их на
.webpи добавив резервные версии. - Сравнить время загрузки шрифтов через CDN и локально, привести результаты.
- Реализовать темную и светлую тему сайта с использованием медиазапросов, CSS переменных и атрибута
color-scheme.
Групповые доклады
Доклад 1: Современные методы сжатия изображений
- Сравнение форматов изображений (JPEG, PNG, WebP, AVIF).
- Инструменты и методы сжатия изображений без потери качества.
- Примеры улучшения производительности.
Доклад 2: Оптимизация загрузки шрифтов
- Влияние шрифтов на производительность сайта.
- Подмножество шрифтов, формат WOFF2, задержка загрузки.
- Использование
font-displayдля управления отображением шрифтов.
Доклад 3: Анализ и улучшение критического пути рендеринга
- Понятие критического пути рендеринга и его влияние на загрузку.
- Стратегии уменьшения количества критических ресурсов.
- Инструменты для анализа и улучшения производительности.
Доклад 4: Content Delivery Networks (CDN) и их роль в производительности
- Принцип работы CDN и их использование для ускорения загрузки.
- Примеры популярных CDN и интеграция в проекты.
- Как выбрать CDN для оптимизации производительности.
Доклад 5: Минификация файлов CSS и JavaScript
- Принцип минификации и ее влияние на производительность.
- Популярные инструменты для минификации.
- Примеры использования и влияние на размер файлов.
Развертывание WordPress с помощью Docker на Linux
При выполнении скриптов ниже не забываем использовать sudo, если работаете не из под пользователя root.
Шаг 1: Установка Docker и Docker Compose
Перед тем как приступить к развертыванию, вам необходимо установить Docker и Docker Compose на ваш компьютер. Выполните следующие команды в терминале:
curl -sSL https://get.docker.com | sh
sudo usermod -aG docker $(whoami)
exit
Если в результате выполнения команды у вас появится сообщение, что указанный дистрибутив не поддерживается (например, Alt Linux), тогда необходимо перейти на страницу с перечнем пакетов для выбранного дистрибутива и найти, как устанавливаются необходимые в ходе работы пакеты: docker и docker-compose.
После этого убедитесь, что Docker запущен:
sudo systemctl start docker
sudo systemctl enable docker
Для проверки правильности установки выполните команду:
docker --version
Шаг 2: Создание проекта WordPress с Docker
Теперь, когда Docker и Docker Compose установлены, мы можем создать проект для развертывания WordPress.
2.1 Создание директории проекта
Создайте директорию для вашего проекта и перейдите в нее:
mkdir wordpress-docker
cd wordpress-docker
2.2 Создание файла docker-compose.yml
В этой директории создайте файл docker-compose.yml с таким содержимым:
version: '3.7'
services:
wordpress:
image: wordpress:latest
container_name: wordpress
ports:
- "3000:80"
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_NAME: wordpress
WORDPRESS_DB_USER: wordpressuser
WORDPRESS_DB_PASSWORD: P@s*w0rd
volumes:
- wordpress_data:/var/www/html
depends_on:
- db
db:
image: mysql:5.7
container_name: mysql
environment:
MYSQL_ROOT_PASSWORD: P@s*w0rd
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpressuser
MYSQL_PASSWORD: P@s*w0rd
volumes:
- db_data:/var/lib/mysql
volumes:
wordpress_data:
db_data:
2.3 Запуск контейнеров
Запустите контейнеры с помощью команды:
docker-compose up -d
Если первый вариант команды не сработает, попробуйте написать команды без использования -: docker compose up -d.
Эта команда скачает нужные образы (если они еще не загружены) и запустит контейнеры в фоновом режиме.
2.4 Проверка работы
Откройте браузер и перейдите по адресу:
Следуйте инструкциям на экране для завершения установки WordPress.
Шаг 3: Остановка и удаление контейнеров
Чтобы остановить контейнеры, выполните команду:
docker-compose down
Эта команда остановит контейнеры и удалит их. Если вы хотите сохранить данные, контейнеры можно перезапускать без потери информации, так как для хранения данных используются тома Docker.
Шаг 3: Создание проекта WordPress с Docker
Далее, следуя руководству с официального сайта Wordpress, создайте сайт на произвольную тематику и покажите его в конце занятия. Удачи!
Контрольное задание по итогам курса
Общие указания
- Всего вариантов задания: 15. Ваш номер варианта определяется по формуле:
номер зачетки % 15 + 1. - Максимальная оценка за работу: 5 баллов.
- Усовершенствования, такие как адаптивность, качественные анимации и т.д., повышают итоговую оценку.
При желании можно подойти и согласовать собственную тему.
Задания
-
Сайт для выбора тура. Создайте веб-сайт, который позволяет пользователям выбирать туры на основании заданных параметров (например, страна, бюджет, продолжительность поездки). Реализуйте форму для фильтрации туров, карточки с описанием и ценой туров, а также адаптивный интерфейс.
-
Онлайн-магазин. Разработайте веб-сайт для демонстрации товаров с возможностью поиска и фильтрации по категориям. Создайте карточки товаров с изображением, названием и ценой. Реализуйте корзину покупок с подсчетом общей стоимости.
-
Сайт ресторана. Создайте веб-сайт для ресторана с разделами: "Меню", "О нас", "Контакты". Раздел меню должен содержать карточки с изображением блюд, описанием и ценой. Реализуйте форму бронирования столиков.
-
Сайт для бронирования авиабилетов. Разработайте веб-сайт, позволяющий пользователям бронировать авиабилеты. Добавьте форму поиска билетов по дате, пункту вылета и прилета. Реализуйте страницу с информацией о рейсах.
-
Образовательная платформа. Создайте сайт для онлайн-курсов. Добавьте разделы "Курсы", "Учебные материалы", "Отзывы". Реализуйте карточки курсов с описанием и кнопкой для записи.
-
Кинотеатр онлайн. Разработайте сайт для демонстрации фильмов. Добавьте разделы "Каталог фильмов", "Рейтинги", "О нас". Реализуйте систему фильтрации фильмов по жанру и году выпуска.
-
Сайт фитнес-клуба. Создайте веб-сайт для фитнес-клуба с разделами: "Услуги", "Тренеры", "Расписание". Реализуйте форму записи на тренировку и фильтрацию по времени и тренерам.
-
Сайт по подбору рецептов. Создайте веб-сайт, где пользователи могут подбирать рецепты по ингредиентам. Реализуйте форму выбора продуктов, карточки с описанием рецептов и инструкцией по приготовлению.
-
Музыкальный сайт. Разработайте веб-сайт для демонстрации музыкальных альбомов и треков. Добавьте возможность фильтрации треков по жанру и исполнителю, а также реализуйте плеер для прослушивания.
-
Сайт о книгах. Создайте веб-сайт для демонстрации книг. Разделите книги по жанрам. Реализуйте карточки книг с изображением обложки, описанием и кнопкой "Подробнее".
-
Путеводитель по городу. Разработайте веб-сайт, содержащий информацию о городе: достопримечательности, кафе, маршруты. Реализуйте карту с отмеченными точками интереса.
-
Сайт кулинарных рецептов. Создайте сайт с каталогом рецептов. Добавьте фильтрацию по типу блюда и ингредиентам. Реализуйте карточки с изображением и пошаговой инструкцией.
-
Сайт для спортивных мероприятий. Разработайте сайт для представления информации о спортивных событиях. Реализуйте календарь мероприятий, а также форму для регистрации участников.
-
Сайт для бронирования отелей. Создайте сайт для поиска и бронирования отелей. Реализуйте фильтрацию по цене, рейтингу и расположению. Добавьте страницу с подробным описанием отеля.
-
Сайт для мероприятий. Разработайте веб-сайт, представляющий афишу мероприятий (концерты, выставки, лекции). Реализуйте разделы с подробной информацией и формой покупки билетов.
Удачи!
Переход от файловых систем к базам данных
Электронные картотеки и системы файлов
Чтобы понять, почему классические электронные картотеки и различные формы систем, основанных на отдельных файлах, рано или поздно становятся неудобными и вынуждают переходить к централизованной базе данных, полезно мысленно перенестись в эпоху 50–60-х годов XX века, когда появлялись первые электронно-вычислительные машины (ЭВМ).
Тогда любой расчёт или учёт данных сводился к тому, что инженеры и математики писали специальные программы, а программисты «зашивали» логику работы с информацией непосредственно внутрь этих программ. Для хранения сведений (например, списков сотрудников, сводок о заказах, научных расчётов) чаще всего заводились отдельные файлы. Если возникала потребность в дополнительном поле (скажем, увеличить длину фамилии с 20 до 25 символов), программисту приходилось:
- Модифицировать структуру этих файлов в коде.
- Придумывать программу-конвертор, которая бы преобразовала уже накопленные данные к новому формату.
- Изменять процедуры чтения, записи, поиска и т. д.
Такой подход со временем показал множество узких мест. Если разные отделы в одной организации создавали «свои» картотеки, неизбежно возникала избыточность данных: у одной машины или подразделения хранился некий старый файл (например, с устаревшим телефоном клиента), у другой — более новая версия. В итоге данные о контрагенте могли расползаться на несколько десятков копий, а их синхронизация превращалась в достаточно сложную и трудоемкую задачу.
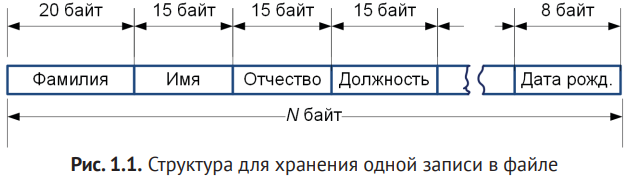
Кроме того, файлы на разных машинах часто оказывались структурно несовместимы: где-то фамилия занимала 20 байт, а где-то 15; в одном отделе разработчики писали на одном языке программирования, а в другом — на другом, с совершенно иной системой записи данных. Чтобы собрать единый отчёт или агрегировать информацию «из нескольких мест», требовалось изобретать громоздкие способы синхронного чтения разных файлов, что становилось затруднительно и для программиста, и для самой машины.
Всё это можно назвать эволюционно понятным этапом — разработчики поначалу пытались “машинным” способом воспроизвести принцип бумажной картотеки: каждая запись в своей карточке, карточки лежат в ящиках, а чтобы найти информацию, нужно найти нужный «ящик». Но в условиях быстро растущих объёмов информации и числа пользователей такой подход начал явно буксовать. Именно тогда постепенно сформировалось убеждение, что для хранения больших массивов данных и многопользовательского доступа необходимо придумывать более гибкие и централизованные решения.
Что такое база данных и зачем она нужна
Когда объём данных стал слишком велик, а требования пользователей стали включать одновременный доступ, быстрый поиск и гибкую выборку, появился новый подход: база данных (БД). Согласно ГОСТ 34.321–96, под БД понимают совокупность взаимосвязанных данных, организованных по определённой схеме для совместного использования.
Однако, справедливым будет и более расширенное определение:
База данных (database) — это организованная совокупность совместно используемых логически связанных данных и их описаний (метаданных), относящаяся к определённой предметной области и предназначенная для удовлетворения информационных потребностей организации.
Обращаясь к сути, зачем нужна база данных:
- Снижение избыточности и предотвращение конфликтов версий. Если раньше приходилось хранить телефон клиента в десятках файлов, то теперь в централизованной БД мы ведём его только в одном месте.
- Совместный доступ. Разные пользователи могут не просто просматривать, но и одновременно обновлять сведения, не рискуя затереть изменения друг друга.
- Централизованное управление. Существует единая «точка входа» — специальная программа (СУБД), которая следит, чтобы данные оставались непротиворечивыми, и выдаёт доступ только тем, кто имеет на это право.
- Надёжность и безопасность. Благодаря механизмам резервного копирования и контроля транзакций (в более поздних моделях) база данных сможет восстанавливаться после сбоев и защищать сведения от несанкционированных действий.
Таким образом, появление БД стало решающим шагом, благодаря которому человечество смогло постепенно уйти от нагромождения файловых архивов и бумажных картотек к более стройной системе хранения, где есть понятия структуры, подчинённости, связей, прав доступа и многого другого.
Эволюция моделей БД
Переход к базе данных не сразу дал идеальную концепцию хранения. В книге приводятся исторические примеры: когда в 50-х и 60-х годах появились первые промышленные ЭВМ, вычислительные мощности начали расти, а вместе с ними рос и спрос на способы организации больших объёмов данных. Можно сказать, что «спусковым крючком» к массовому развитию БД послужили грандиозные технические проекты (например, космическая программа Apollo в США), где требовалось в реальном времени обрабатывать горы информации: от расчёта траектории полёта до хранения детализации заказов, выставляемых подрядчикам.
Стандартов и согласованного понимания, как именно строить базы данных, поначалу не было, поэтому появлялись разные модели БД:
-
Иерархическая модель
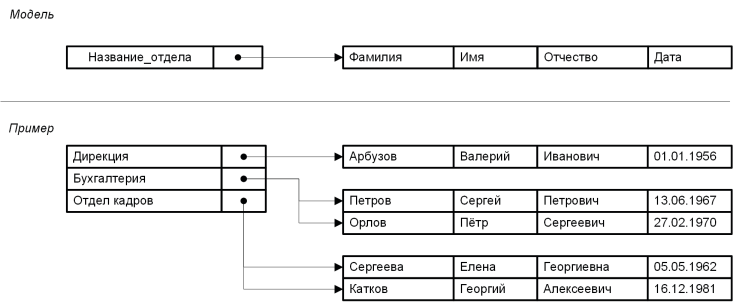
В данной модели данные представляются в виде перевёрнутого дерева: в корне (самом верхнем уровне) лежит «главный» объект, а от него отходят ветви к подчинённым объектам, у которых, в свою очередь, могут быть свои «потомки». Это было проще, чем хаотичные файлы, поскольку достаточно очевидно — один родитель, много потомков. Так было организовано, например, хранение структур «компания → отделы → сотрудники». Однако модель слишком жёстко требовала, чтобы у каждого дочернего узла был только один родитель. Если реальная жизнь требовала иначе (связи «многие ко многим»), в иерархической структуре это становилось затруднительным.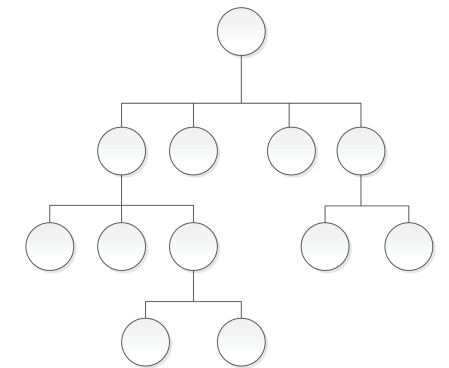
-
Сетевая модель
Попытка придать данным большую гибкость: вместо деревьев используется «граф»; любая запись (узел) может иметь несколько родительских элементов. Это давало более богатые возможности, однако усложняло логику администрирования и навигации по данным. Программисту всё ещё приходилось «знать», в каких именно узлах и как связаны записи, чтобы «дойти» до нужной информации.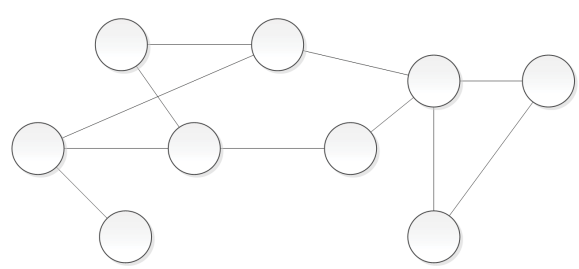
-
Реляционная модель
Принципиальный прорыв произошёл в 70-х, когда Эдгар Кодд предложил описывать данные в виде таблиц (отношений), связанных между собой с помощью общих полей (ключей). Математическая база реляционной модели (теория множеств, логика) позволила формализовать многие вопросы работы с данными. Реляционные СУБД приняли во внимание опыт предыдущих подходов и свели взаимодействие к понятным операциям: добавить запись, убрать, изменить, выбрать по условию. Были разработаны первые версии языка SQL (в то время SEQUEL), позволяющие довольно просто «запрашивать» данные. Со временем реляционные СУБД, такие как IBM DB2, Oracle, MySQL и другие, заняли доминирующую позицию в мире. -
Объектно-ориентированная модель
Когда в середине 80-х объектно-ориентированное программирование стало основой софта, стали появляться идеи хранить данные в виде объектов с методами, атрибутами и наследованием. Однако «чистые» объектные БД оказались слишком сложны в стандартизации. Наиболее удачные решения — это объектно-реляционные СУБД, где к реляционной основе добавлены механизмы, напоминающие объекты. -
Слабо структурированные и документ-ориентированные БД (NoSQL)
С появлением больших интернет-проектов и сменой характера данных (часто меняющиеся, не всегда фиксированной структуры) стали набирать популярность документо-ориентированные и другие нереляционные БД, способные хранить информацию, к примеру, в формате JSON. Они отлично справляются со сколь угодно «разношерстными» документами, поддерживают горизонтальное масштабирование и высокую скорость вставки. Однако для традиционных корпоративных задач зачастую всё-таки используется классическая реляционная модель, поскольку она обладает более жёсткими и отработанными механизмами целостности.
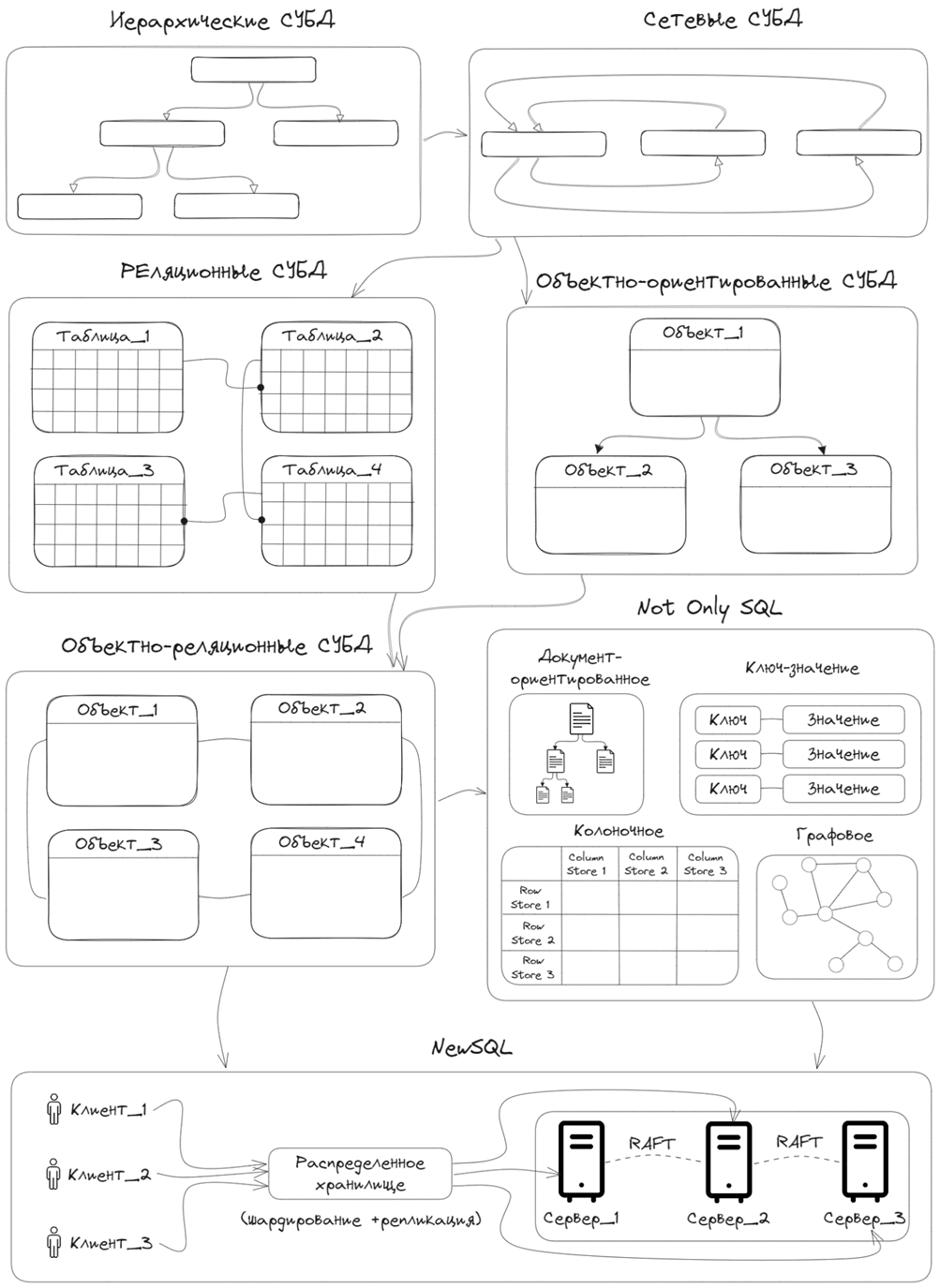
Прим.: Тот факт, что реляционные базы уже несколько десятилетий занимают лидирующие позиции, не отменяет существования и развития других моделей. Потребности современного мира (социальные сети, Big Data, аналитические хранилища) расширили область применения NoSQL и гибридных СУБД. Но почти все учебные курсы и классические проекты по-прежнему опираются на реляционную парадигму.
Практическое задание
Ниже приведены два текстовых файла (Klienty.txt и Zakazy.txt) с 100 записями каждый.
Сделайте выводы и о проделанной работе в формате мини-отчета.
Файл «Klienty.txt». Каждая строка содержит 8 полей, разделённых точкой с запятой (;). Формат:
ID_Клиента;ФИО;Телефон;Город;Адрес;Email;Дата_Регистрации;Статус
- ID_Клиента: уникальный числовой идентификатор (1 до 100).
- ФИО: фамилия, имя и отчество.
- Телефон: в условном формате
+7-9xx-xxx-xx-xx. - Город: выбрано несколько крупнейших городов (повторяются).
- Адрес: абстрактная уличная запись.
- Email: формальный почтовый ящик.
- Дата_Регистрации: в интервале примерно от
2024-05-01до2024-12-30. - Статус: например, «Обычный», «VIP» или «Заблокирован».
1;Иванов Иван Петрович;+7-900-111-11-11;Москва;ул. Лесная, д. 5;ivanov1@mail.ru;2024-05-02;Обычный
2;Сидорова Анна Викторовна;+7-901-222-22-22;Санкт-Петербург;пр. Невский, д. 10;anna_sidorova@mail.ru;2024-06-11;VIP
3;Петров Пётр Ильич;+7-902-333-33-33;Новосибирск;ул. Дачная, д. 45;p.petrov@mail.ru;2024-07-01;Обычный
4;Васильев Никита Олегович;+7-903-444-44-44;Казань;ул. Университетская, д. 7;nikita_vas@mail.ru;2024-08-15;Обычный
5;Жукова Елена Андреевна;+7-904-555-55-55;Екатеринбург;ул. Сибирская, д. 30;e.zhukova@mail.ru;2024-08-20;Заблокирован
6;Кузнецов Сергей Игоревич;+7-905-666-66-66;Самара;ул. Гагарина, д. 19;sergey_kuz@mail.ru;2024-09-05;VIP
7;Орлова Мария Павловна;+7-906-777-77-77;Уфа;ул. Солнечная, д. 12;mar_orlova@mail.ru;2024-05-22;Обычный
8;Виноградов Олег Семёнович;+7-907-888-88-88;Омск;ул. Садовая, д. 56;oleg_vino@mail.ru;2024-06-10;Обычный
9;Фёдоров Василий Аркадьевич;+7-908-999-99-99;Москва;ул. Центральная, д. 9;vasja-f@mail.ru;2024-05-25;VIP
10;Миронова Дарья Егоровна;+7-909-101-10-10;Санкт-Петербург;пр. Ленина, д. 100;dar_mironova@mail.ru;2024-07-03;Обычный
11;Алексеева Нина Дмитриевна;+7-910-202-20-20;Новосибирск;ул. Труда, д. 15;nina.alex@mail.ru;2024-06-28;VIP
12;Борисов Леонид Викторович;+7-911-303-30-30;Казань;ул. Лесная, д. 100;leonid_bor@mail.ru;2024-05-17;Обычный
13;Титова Ольга Владимировна;+7-912-404-40-40;Екатеринбург;ул. Космонавтов, д. 12;olga_titova@mail.ru;2024-09-01;VIP
14;Соколова Ирина Андреевна;+7-913-505-50-50;Самара;ул. Комсомольская, д. 3;i.sokolova@mail.ru;2024-06-11;Обычный
15;Павлов Дмитрий Артемьевич;+7-914-606-60-60;Уфа;пр. Победы, д. 77;d_pavlov@mail.ru;2024-07-22;Обычный
16;Королёв Андрей Сергеевич;+7-915-707-70-70;Москва;ул. Парковая, д. 5;korolev_and@mail.ru;2024-08-03;VIP
17;Медведева Екатерина Павловна;+7-916-111-11-77;Санкт-Петербург;ул. Маяковского, д. 19;ekat_med@mail.ru;2024-12-01;Обычный
18;Дмитриев Михаил Леонидович;+7-917-222-22-88;Новосибирск;ул. Сельская, д. 11;m_dmitriev@mail.ru;2024-05-09;Заблокирован
19;Белова Анастасия Андреевна;+7-918-333-33-99;Екатеринбург;ул. Победы, д. 8;nastya_bel@mail.ru;2024-07-05;Обычный
20;Николаева Оксана Дмитриевна;+7-919-444-44-10;Казань;ул. Кооперативная, д. 6;oks_nik@mail.ru;2024-10-01;Обычный
21;Гордеев Павел Олегович;+7-920-555-55-11;Самара;ул. Пушкина, д. 31;gordeey_p@mail.ru;2024-05-30;VIP
22;Ермаков Игорь Геннадьевич;+7-921-111-11-12;Уфа;ул. Дмитрова, д. 67;ermak_igor@mail.ru;2024-09-09;Обычный
23;Тарасов Виктор Анатольевич;+7-922-222-22-23;Омск;пр. Вокзальный, д. 2;viktor_tara@mail.ru;2024-05-16;Обычный
24;Шестаков Артём Витальевич;+7-923-333-33-34;Москва;ул. Большая, д. 99;art_shes@mail.ru;2024-12-15;VIP
25;Кожина Светлана Сергеевна;+7-924-444-44-45;Санкт-Петербург;ул. Мира, д. 20;s.kozhina@mail.ru;2024-08-08;Обычный
26;Попов Иван Владимирович;+7-925-111-12-12;Новосибирск;ул. Уютная, д. 3;ivan_pop@mail.ru;2024-09-22;Обычный
27;Фролова Мария Дмитриевна;+7-926-222-23-23;Казань;ул. Луговая, д. 4;frolova.m@mail.ru;2024-10-03;VIP
28;Денисов Юрий Константинович;+7-927-333-34-34;Екатеринбург;ул. Северная, д. 12;denisov_y@mail.ru;2024-05-19;Обычный
29;Романова Лидия Викторовна;+7-928-444-45-45;Самара;ул. Петра, д. 10;l.romanova@mail.ru;2024-07-30;Обычный
30;Гришин Антон Евгеньевич;+7-929-555-56-56;Уфа;ул. Тополиная, д. 1;anton_gr@mail.ru;2024-05-13;Заблокирован
31;Воробьёв Алексей Максимович;+7-930-666-67-67;Омск;ул. Ленина, д. 47;alex_vor@mail.ru;2024-05-28;VIP
32;Кириллова Светлана Ивановна;+7-931-777-78-78;Москва;ул. Речная, д. 15;kir_svet@mail.ru;2024-10-14;Обычный
33;Зуев Олег Вадимович;+7-932-888-79-79;Санкт-Петербург;ул. Профсоюзная, д. 70;oleg_zu@mail.ru;2024-06-16;Обычный
34;Морозова Татьяна Андреевна;+7-933-999-80-80;Новосибирск;ул. Молодёжная, д. 22;moro_tan@mail.ru;2024-07-18;VIP
35;Дорофеев Сергей Алексеевич;+7-934-101-81-81;Казань;ул. Красная, д. 3;s.doro@mail.ru;2024-09-12;Обычный
36;Захарова Елена Витальевна;+7-935-202-82-82;Екатеринбург;ул. Уральская, д. 55;zahar.elena@mail.ru;2024-06-02;Обычный
37;Рыбаков Павел Кириллович;+7-936-303-83-83;Самара;ул. Заречная, д. 6;rybakov_p@mail.ru;2024-07-14;VIP
38;Крылова Дарья Васильевна;+7-937-404-84-84;Уфа;ул. Летняя, д. 2;dasha_kryl@mail.ru;2024-08-06;Обычный
39;Калинин Олег Георгиевич;+7-938-505-85-85;Омск;ул. Новая, д. 10;oleg_kal@mail.ru;2024-09-07;VIP
40;Максимова Оксана Петровна;+7-939-606-86-86;Москва;ул. Арбат, д. 44;oks_max@mail.ru;2024-12-28;Обычный
41;Комаров Игорь Александрович;+7-940-111-11-41;Санкт-Петербург;ул. Заречная, д. 14;komar_igor@mail.ru;2024-10-11;VIP
42;Агапова Дарья Артёмовна;+7-941-222-22-42;Новосибирск;ул. Полевая, д. 1;agapova_d@mail.ru;2024-06-25;Обычный
43;Щербаков Алексей Степанович;+7-942-333-33-43;Казань;ул. Лазарева, д. 9;al_shcherb@mail.ru;2024-07-02;Заблокирован
44;Игнатьева Ирина Николаевна;+7-943-444-44-44;Екатеринбург;ул. Средняя, д. 27;ignat_ir@mail.ru;2024-08-12;Обычный
45;Быков Николай Дмитриевич;+7-944-555-55-45;Самара;ул. Парковая, д. 18;bykov_nd@mail.ru;2024-12-02;VIP
46;Фомина Вера Андреевна;+7-945-666-66-46;Уфа;ул. Студенческая, д. 10;fomina_v@mail.ru;2024-06-09;Обычный
47;Копылов Денис Павлович;+7-946-777-77-47;Омск;ул. Вокзальная, д. 33;d.kopylov@mail.ru;2024-10-28;Обычный
48;Карпова Лилия Романовна;+7-947-888-88-48;Москва;ул. Болотная, д. 19;lilia_karp@mail.ru;2024-08-22;VIP
49;Мальцев Григорий Станиславович;+7-948-999-99-49;Санкт-Петербург;ул. Академическая, д. 1;gri_mal@mail.ru;2024-05-15;Обычный
50;Лазарева Диана Львовна;+7-949-101-10-50;Новосибирск;ул. Титова, д. 8;diana_laz@mail.ru;2024-06-26;Обычный
51;Беляев Артём Дмитриевич;+7-950-111-11-51;Казань;ул. Славная, д. 14;bel.art@mail.ru;2024-07-09;VIP
52;Сафонова Ирина Петровна;+7-951-222-22-52;Екатеринбург;ул. Радищева, д. 11;safonovai@mail.ru;2024-09-06;Обычный
53;Рогова Анастасия Владимировна;+7-952-333-33-53;Самара;ул. Торговая, д. 2;rogova_nastya@mail.ru;2024-08-01;Обычный
54;Суханов Пётр Артёмович;+7-953-444-44-54;Уфа;ул. Заводская, д. 7;psuhanov@mail.ru;2024-05-27;VIP
55;Мартынова Зоя Фёдоровна;+7-954-555-55-55;Омск;ул. Нагорная, д. 5;zoya_mart@mail.ru;2024-10-17;Заблокирован
56;Лебедев Василий Олегович;+7-955-666-66-56;Москва;ул. Полянка, д. 80;leb_oleg@mail.ru;2024-05-05;Обычный
57;Антонова Вита Кирилловна;+7-956-777-77-57;Санкт-Петербург;ул. Малая, д. 20;antonova_v@mail.ru;2024-11-02;VIP
58;Кудрявцев Павел Юрьевич;+7-957-888-88-58;Новосибирск;ул. Учительская, д. 23;p.kudryavtsev@mail.ru;2024-07-21;Обычный
59;Шилова Алиса Петровна;+7-958-999-99-59;Казань;ул. Рабочая, д. 12;alisha@mail.ru;2024-10-11;Обычный
60;Куликов Иван Сергеевич;+7-959-101-10-60;Екатеринбург;ул. Восточная, д. 99;ivan_kulikov@mail.ru;2024-12-05;Обычный
61;Гусев Олег Артёмович;+7-960-111-11-61;Самара;ул. Первомайская, д. 4;oleg_gus@mail.ru;2024-05-06;VIP
62;Кравцова Полина Дмитриевна;+7-961-222-22-62;Уфа;ул. Мирная, д. 40;polina.krav@mail.ru;2024-06-13;Обычный
63;Ефимов Данил Николаевич;+7-962-333-33-63;Омск;ул. Лесная, д. 88;dan_efimov@mail.ru;2024-07-24;Обычный
64;Суворова Алина Владимировна;+7-963-444-44-64;Москва;ул. Гоголя, д. 8;alina_su@mail.ru;2024-08-30;VIP
65;Логинов Никита Сергеевич;+7-964-555-55-65;Санкт-Петербург;ул. Коммунальная, д. 3;nik.log@mail.ru;2024-10-09;Обычный
66;Устинова Татьяна Дмитриевна;+7-965-666-66-66;Новосибирск;ул. Южная, д. 19;tustinova@mail.ru;2024-06-04;Обычный
67;Пахомова Марина Витальевна;+7-966-777-77-67;Казань;ул. Правды, д. 11;marina_pakh@mail.ru;2024-05-21;Обычный
68;Мамонтов Олег Анатольевич;+7-967-888-88-68;Екатеринбург;ул. Горная, д. 77;oleg_mam@mail.ru;2024-07-19;VIP
69;Котова Оксана Игоревна;+7-968-999-99-69;Самара;ул. Тихая, д. 51;oks_kot@mail.ru;2024-08-09;Обычный
70;Макаров Игорь Викторович;+7-969-101-10-70;Уфа;пер. Садовый, д. 2;mak_igor@mail.ru;2024-09-03;Заблокирован
71;Гришина Ольга Леонидовна;+7-970-111-11-71;Омск;ул. Кооперативная, д. 14;gri_olga@mail.ru;2024-05-12;VIP
72;Третьяков Павел Максимович;+7-971-222-22-72;Москва;ул. Суворова, д. 7;p_tret@mail.ru;2024-06-29;Обычный
73;Швецова Дарья Фёдоровна;+7-972-333-33-73;Санкт-Петербург;ул. 3-я Линия, д. 1;dasha_shv@mail.ru;2024-07-16;Обычный
74;Горшков Илья Аркадьевич;+7-973-444-44-74;Новосибирск;ул. Железнодорожная, д. 90;gorshkov_i@mail.ru;2024-09-11;VIP
75;Авдеева Марина Андреевна;+7-974-555-55-75;Казань;ул. Фестивальная, д. 99;avdeeva_m@mail.ru;2024-10-10;Обычный
76;Зотов Пётр Михайлович;+7-975-666-66-76;Екатеринбург;ул. Солнечная, д. 4;p_zotov@mail.ru;2024-08-25;Обычный
77;Карева Лариса Павловна;+7-976-777-77-77;Самара;ул. Ломоносова, д. 2;lkareva@mail.ru;2024-05-18;VIP
78;Пластов Семён Андреевич;+7-977-888-88-78;Уфа;ул. Зеленая, д. 24;plastov_s@mail.ru;2024-07-29;Обычный
79;Руднева Алена Денисовна;+7-978-999-99-79;Омск;ул. Колхозная, д. 7;alena_rud@mail.ru;2024-09-16;Обычный
80;Овчинников Евгений Глебович;+7-979-101-10-80;Москва;ул. Успенская, д. 10;evg_ovch@mail.ru;2024-12-22;VIP
81;Князева Анастасия Витальевна;+7-980-111-11-81;Санкт-Петербург;ул. Дружбы, д. 8;knyaz_a@mail.ru;2024-05-10;Обычный
82;Зубов Антон Михайлович;+7-981-222-22-82;Новосибирск;ул. Волжская, д. 3;anton_zub@mail.ru;2024-07-07;Обычный
83;Калашников Андрей Владимирович;+7-982-333-33-83;Казань;ул. Песочная, д. 16;kalash@mail.ru;2024-10-12;Обычный
84;Пугачёва Ирина Артемьевна;+7-983-444-44-84;Екатеринбург;ул. Заповедная, д. 20;irina_puga@mail.ru;2024-06-07;VIP
85;Зайцев Игорь Фёдорович;+7-984-555-55-85;Самара;ул. Литейная, д. 9;zaycev_if@mail.ru;2024-07-13;Обычный
86;Кузина Вера Валерьевна;+7-985-666-66-86;Уфа;пер. Северный, д. 11;kuzina_v@mail.ru;2024-10-02;Обычный
87;Гаврилов Роман Витальевич;+7-986-777-77-87;Омск;ул. Тихвинская, д. 30;roman_gav@mail.ru;2024-11-01;VIP
88;Златова Анастасия Васильевна;+7-987-888-88-88;Москва;ул. Ломанная, д. 4;nastya_zl@mail.ru;2024-05-26;Обычный
89;Котов Евгений Владиславович;+7-988-999-99-89;Санкт-Петербург;пр. Светлый, д. 5;kotov_ev@mail.ru;2024-08-23;Обычный
90;Кукушкин Денис Кириллович;+7-989-101-10-90;Новосибирск;ул. Большая, д. 7;d.kukush@mail.ru;2024-06-15;Заблокирован
91;Прохорова Диана Егоровна;+7-990-111-11-91;Казань;ул. Сельсоветская, д. 48;diana_proh@mail.ru;2024-10-27;Обычный
92;Громова Лилия Андреевна;+7-991-222-22-92;Екатеринбург;ул. Арматурная, д. 7;lilia_grom@mail.ru;2024-05-09;VIP
93;Семёнов Михаил Петрович;+7-992-333-33-93;Самара;ул. Казачья, д. 3;semiha@mail.ru;2024-07-28;Обычный
94;Литвинова Карина Денисовна;+7-993-444-44-94;Уфа;ул. Достоевского, д. 15;kar_lit@mail.ru;2024-09-18;Обычный
95;Сергеев Руслан Павлович;+7-994-555-55-95;Омск;ул. Садовая, д. 90;serg_rus@mail.ru;2024-06-08;Обычный
96;Акимова Вера Георгиевна;+7-995-666-66-96;Москва;ул. Технологов, д. 2;vera_akim@mail.ru;2024-12-26;VIP
97;Корнеева Дарья Владиславовна;+7-996-777-77-97;Санкт-Петербург;ул. 1-я Советская, д. 9;darya_korn@mail.ru;2024-08-11;Обычный
98;Шаляпин Глеб Петрович;+7-997-888-88-98;Новосибирск;ул. Московская, д. 11;gleb_sha@mail.ru;2024-11-30;VIP
99;Фомичёв Лев Александрович;+7-998-999-99-99;Казань;ул. Депутатская, д. 6;lev_fom@mail.ru;2024-05-29;Обычный
100;Воронова Кристина Андреевна;+7-999-101-10-00;Екатеринбург;ул. Станционная, д. 1;voronova_k@mail.ru;2024-06-20;Обычный
Файл «Zakazy.txt». Каждая строка содержит 7 полей, разделённых точкой с запятой (;). Формат:
ID_Заказа;ID_Клиента;Дата;Сумма;Способ_Оплаты;Способ_Доставки;Дата_Доставки
- ID_Заказа: уникальный номер заказа (1..100).
- ID_Клиента: номер клиента (должен быть в диапазоне 1..100).
- Дата: дата оформления (в 2025 году).
- Сумма: целое число (в районе от 300 до ~25000).
- Способ_Оплаты: «Наличные», «Карта», «Онлайн».
- Способ_Доставки: «Курьер» или «Самовывоз».
- Дата_Доставки: дата, на 1–7 дней позже даты оформления (или приблизительно).
1;1;2025-01-01;400;Наличные;Самовывоз;2025-01-02
2;3;2025-01-02;7500;Карта;Курьер;2025-01-05
3;6;2025-01-03;13000;Онлайн;Курьер;2025-01-06
4;2;2025-01-03;450;Наличные;Самовывоз;2025-01-05
5;5;2025-01-04;6000;Карта;Курьер;2025-01-06
6;7;2025-01-05;9500;Онлайн;Курьер;2025-01-07
7;1;2025-01-06;2300;Наличные;Самовывоз;2025-01-09
8;10;2025-01-07;7400;Карта;Самовывоз;2025-01-10
9;13;2025-01-07;12100;Карта;Курьер;2025-01-11
10;2;2025-01-08;19000;Онлайн;Курьер;2025-01-11
11;4;2025-01-08;590;Наличные;Самовывоз;2025-01-09
12;15;2025-01-08;6400;Карта;Курьер;2025-01-10
13;25;2025-01-09;300;Онлайн;Самовывоз;2025-01-09
14;19;2025-01-09;8100;Онлайн;Курьер;2025-01-12
15;21;2025-01-10;500;Наличные;Самовывоз;2025-01-13
16;6;2025-01-10;15000;Карта;Курьер;2025-01-14
17;3;2025-01-11;2300;Онлайн;Курьер;2025-01-14
18;22;2025-01-11;17900;Наличные;Самовывоз;2025-01-12
19;9;2025-01-12;9999;Карта;Курьер;2025-01-15
20;11;2025-01-12;4500;Онлайн;Самовывоз;2025-01-14
21;18;2025-01-12;19900;Карта;Курьер;2025-01-16
22;13;2025-01-13;680;Наличные;Курьер;2025-01-15
23;17;2025-01-13;5200;Онлайн;Самовывоз;2025-01-17
24;24;2025-01-14;11900;Карта;Курьер;2025-01-18
25;1;2025-01-14;3700;Наличные;Самовывоз;2025-01-15
26;16;2025-01-14;550;Онлайн;Курьер;2025-01-17
27;20;2025-01-15;20200;Карта;Курьер;2025-01-18
28;8;2025-01-15;7777;Карта;Самовывоз;2025-01-17
29;23;2025-01-15;4300;Наличные;Самовывоз;2025-01-16
30;14;2025-01-16;13000;Онлайн;Курьер;2025-01-18
31;19;2025-01-16;400;Наличные;Самовывоз;2025-01-17
32;7;2025-01-17;15600;Онлайн;Курьер;2025-01-20
33;12;2025-01-17;8600;Карта;Курьер;2025-01-19
34;25;2025-01-18;520;Онлайн;Самовывоз;2025-01-18
35;10;2025-01-18;999;Наличные;Самовывоз;2025-01-19
36;5;2025-01-19;18500;Карта;Курьер;2025-01-22
37;9;2025-01-19;2600;Онлайн;Курьер;2025-01-21
38;21;2025-01-19;6000;Карта;Самовывоз;2025-01-20
39;4;2025-01-20;15200;Наличные;Курьер;2025-01-23
40;3;2025-01-20;4555;Онлайн;Самовывоз;2025-01-22
41;40;2025-01-21;8200;Карта;Самовывоз;2025-01-22
42;16;2025-01-21;19990;Онлайн;Курьер;2025-01-25
43;26;2025-01-21;470;Наличные;Самовывоз;2025-01-22
44;30;2025-01-22;3400;Карта;Курьер;2025-01-24
45;9;2025-01-22;12050;Онлайн;Курьер;2025-01-23
46;41;2025-01-23;1000;Наличные;Самовывоз;2025-01-24
47;50;2025-01-23;9100;Карта;Курьер;2025-01-26
48;33;2025-01-24;230;Наличные;Самовывоз;2025-01-24
49;37;2025-01-24;18900;Онлайн;Курьер;2025-01-27
50;44;2025-01-24;5700;Карта;Курьер;2025-01-26
51;60;2025-01-25;2200;Наличные;Самовывоз;2025-01-27
52;47;2025-01-25;13950;Онлайн;Курьер;2025-01-29
53;11;2025-01-25;8600;Карта;Самовывоз;2025-01-28
54;54;2025-01-26;1560;Наличные;Самовывоз;2025-01-26
55;71;2025-01-26;2020;Онлайн;Курьер;2025-01-29
56;18;2025-01-26;15000;Карта;Курьер;2025-01-28
57;32;2025-01-27;3100;Карта;Курьер;2025-01-28
58;72;2025-01-27;7800;Онлайн;Самовывоз;2025-01-28
59;65;2025-01-27;22000;Карта;Курьер;2025-01-30
60;8;2025-01-28;8888;Онлайн;Курьер;2025-01-31
61;66;2025-01-28;350;Наличные;Самовывоз;2025-01-29
62;74;2025-01-28;22200;Карта;Курьер;2025-01-29
63;9;2025-01-29;777;Онлайн;Самовывоз;2025-01-29
64;80;2025-01-29;15900;Карта;Курьер;2025-01-31
65;59;2025-01-29;10500;Онлайн;Курьер;2025-02-01
66;11;2025-01-30;4900;Наличные;Самовывоз;2025-02-01
67;90;2025-01-30;8800;Карта;Курьер;2025-02-02
68;15;2025-01-30;6100;Онлайн;Курьер;2025-02-02
69;100;2025-01-31;2400;Наличные;Самовывоз;2025-02-01
70;57;2025-01-31;13200;Карта;Самовывоз;2025-02-02
71;22;2025-01-31;3000;Онлайн;Курьер;2025-02-03
72;78;2025-02-01;540;Наличные;Самовывоз;2025-02-02
73;87;2025-02-01;18950;Онлайн;Курьер;2025-02-03
74;36;2025-02-01;14999;Карта;Курьер;2025-02-04
75;45;2025-02-02;9900;Наличные;Самовывоз;2025-02-03
76;53;2025-02-02;6750;Карта;Курьер;2025-02-04
77;49;2025-02-02;2888;Онлайн;Курьер;2025-02-03
78;1;2025-02-03;3999;Наличные;Самовывоз;2025-02-05
79;70;2025-02-03;880;Онлайн;Курьер;2025-02-05
80;95;2025-02-03;5100;Карта;Самовывоз;2025-02-04
81;64;2025-02-04;20770;Онлайн;Курьер;2025-02-06
82;46;2025-02-04;3050;Наличные;Самовывоз;2025-02-05
83;77;2025-02-04;16200;Карта;Курьер;2025-02-07
84;28;2025-02-05;4555;Онлайн;Курьер;2025-02-07
85;81;2025-02-05;6900;Карта;Самовывоз;2025-02-06
86;14;2025-02-05;990;Наличные;Самовывоз;2025-02-06
87;48;2025-02-06;12900;Онлайн;Курьер;2025-02-07
88;34;2025-02-06;2320;Карта;Курьер;2025-02-08
89;27;2025-02-06;2222;Наличные;Самовывоз;2025-02-06
90;91;2025-02-07;15000;Карта;Самовывоз;2025-02-08
91;82;2025-02-07;18600;Онлайн;Курьер;2025-02-10
92;39;2025-02-07;990;Наличные;Самовывоз;2025-02-08
93;56;2025-02-08;7550;Карта;Курьер;2025-02-11
94;86;2025-02-08;4999;Онлайн;Курьер;2025-02-09
95;29;2025-02-08;12200;Наличные;Самовывоз;2025-02-09
96;61;2025-02-09;7800;Карта;Курьер;2025-02-11
97;31;2025-02-09;340;Онлайн;Курьер;2025-02-10
98;94;2025-02-09;10700;Карта;Самовывоз;2025-02-10
99;75;2025-02-10;20600;Онлайн;Курьер;2025-02-13
100;24;2025-02-10;499;Наличные;Самовывоз;2025-02-11
Список вопросов
1. Расширенный поиск и фильтрация:
- Найти все заказы, где сумма превышает
10000, оформленные за последние 5 дней. Требуется получить даты заказов, суммы и ФИО клиентов. - Пользователи хотят сразу видеть не только ФИО клиента, но и город и email. Объясните, как слить данные из двух файлов.
- Нужно выделить заказы со способом оплаты «Онлайн» или «Карта», при этом показать только тех клиентов, у кого статус = «VIP». Как можно соединить
ID_Клиентаи статус?
2. Подсчёты и группировка:
- Подсчитать общее количество заказов, сделанных каждым городом (ориентируясь на поле «Город» из
Klienty.txtиID_КлиентаизZakazy.txt). - Определить среднюю сумму заказов по каждому статусу (Обычный, VIP, Заблокирован). Нужно одновременно «достать» статусы из первого файла и суммы из второго. Что делать, если в
Klienty.txtесть ID клиента со статусом «Заблокирован», но такой клиент сделал несколько заказов до блокировки? - Посчитать суммарную выручку по каждой дате доставки (поле «Дата_Доставки») и сравнить её с датой оформления заказа.
3. Проверка целостности и дублирования:
- Предположим, в файле
Zakazy.txtвдруг появились ссылки наID_Клиента=101. ВKlienty.txtже всего 100 клиентов (ID 101 не существует). Что произойдёт? Как понять, какие заказы «висят в воздухе»? Где логика, которая запрещает такие ошибки? - Один и тот же клиент (допустим, ID=9) в «реальности» сменил фамилию, а в файле
Klienty.txtстарая фамилия не обновлена, зато уже создались новые заказы с «новой» фамилией (предположим, какой-то отдел внёс изменения в копию файла). Как согласовать копии? Что будет, если у разных сотрудников компании разная версияKlienty.txt?
4. Сложное условие объединения:
- Нужно вывести список заказов, у которых «Способ_Оплаты» = «Карта», Сумма > 9000, и при этом клиенты находятся в «Москва» или «Санкт-Петербург». Нужно также показать не только их ФИО, но и даты регистрации, чтобы узнать, «насколько свежий» клиент.
- Необходтио сравнить «даты оформления» и «даты доставки» и найти все случаи, когда доставка опоздала более чем на 3 дня. При хранении в файлах как проверить разницу дат? Каким образом можно учесть различный формат дат?
5. Многопользовательские конфликты:
- Что, если два оператора одновременно корректируют файл
Klienty.txt— один меняет e-mail у клиента ID=10, другой одновременно меняет его «Статус»? Есть ли какой-то встроенный механизм блокировки в текстовых файлах? - Если конфликты привели к тому, что часть строк «переписалась» или файл повредился, как восстановить информацию? Есть ли централизованное логирование изменений или транзакции?
«Система управления базами данных»
Что такое СУБД?
До появления СУБД разработчики работали непосредственно с файлами (так называемыми «электронными картотеками»), полностью создавая всю «начинку»: определяли форматы хранения, способы индексации и поиска данных, механизмы проверки корректности. Подобный подход был достаточно трудоёмким и негибким: любая модификация структуры данных или правил доступа означала переписывание значительной части программного кода.
С возникновением более совершенных моделей данных (иерархической, сетевой, реляционной) появилась идея отделить управление данными от прикладных программ. Возникли специальные комплексы программных средств — системы управления базами данных (СУБД). Их главная задача — предоставить универсальные механизмы для хранения и обслуживания данных, чтобы прикладным разработчикам не приходилось снова и снова изобретать базовые операции.
Система управления базами данных (Database Management System, DBMS) – это комплекс программных средств, с помощью которых можно создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ пользователей.
Современная БД немыслима без СУБД. Последняя обеспечивает удобные инструменты для:
- проектирования и администрирования (создание структуры таблиц, настройка прав, заданий, мониторинг);
- управления безопасностью (разграничение прав пользователей);
- реализации механизмов параллельного доступа;
- резервного копирования и восстановления;
- взаимодействия с программными приложениями (через язык SQL или другие интерфейсы).
Особый акцент в определении нужно сделать на «контролируемом доступе», который включает в себя:
- Предотвращение несанкционированного доступа к данным.
- Контроль многопользовательского (параллельного) доступа.
- Поддержку целостности данных.
- Восстановление данных после сбоев.
Таким образом, СУБД не только предоставляет базовые операции с данными, но и берёт на себя большую часть «ответственности» по обеспечению корректности, защиты и сохранности информации.
Ключевой функционал СУБД
Основные функции были выделены ещё Э.Ф. Коддом в начале 1980-х годов. С тех пор этот список только дополнялся:
-
Доступность данных
СУБД должна предоставить средства для вставки, редактирования, удаления и выборки данных без необходимости углубляться в физические аспекты хранения. С точки зрения пользователя операции должны быть «прозрачными»: детали реализации (как именно информация хранится на диске, где лежат индексы и т. д.) скрыты. -
Метаописание данных
Наличие системного каталога (или словаря данных), в котором хранится структура БД: имена таблиц, их столбцов и типов данных, связи, ограничительные условия, учётные записи пользователей и вспомогательная статистика. Метаданные помогают понять суть хранимой информации и обеспечивают более безопасный и упорядоченный доступ. -
Управление параллельностью
Одновременная работа многих пользователей с общими данными требует механизмов, которые предотвращают конфликты при одновременном редактировании и чтении. СУБД должна уметь управлять блокировками, обеспечивать «сериальность» транзакций, решать конфликты блокировок или, по крайней мере, снижать риски некорректных обновлений. -
Обработка данных в рамках транзакции
Данные в СУБД обновляются целостными блоками (транзакциями). Если внутри транзакции что-то идёт не так (программа аварийно завершается, пропадает связь, возникает ошибка), изменения автоматически отменяются (откат). Принцип «либо все операции выполнились, либо ни одна» обеспечивает непротиворечивое состояние данных.Классическим примером является снятие наличных в банкомате: если не происходит физическая выдача денег, транзакция откатывается, и сумма возвращается на счёт клиента.
-
Обеспечение целостности данных
Правила целостности — «каркас», который гарантирует, что данные в БД не придут в несоответствие. Обычно говорят о целостности доменов (типов), строк (уникальность первичных ключей), связей (ссылочная целостность), а также о дополнительных корпоративных ограничениях. СУБД должна не допускать операций, нарушающих эти правила. -
Восстановление данных
При аппаратных сбоях или ошибках СУБД должна уметь восстанавливать утраченную или повреждённую информацию. Основная защита — система резервного копирования и журналы транзакций, что позволяет «откатить» или «прокрутить» изменения в нужную точку во времени. -
Обмен данными
Современная СУБД должна поддерживать сетевые протоколы и обеспечивать удалённый доступ к БД, чтобы пользователи могли взаимодействовать с информацией из разных точек (локальной сети, интернета и т. д.). -
Контроль за доступом
Только авторизованные пользователи с необходимыми правами могут работать с базой. Это включает проверку логинов и паролей, разграничение уровней доступа (чтение, модификация, администрирование и т. д.).
Также в большинстве случаев можно выделить другие дополнительные сервисы (мониторинг производительности, статистический анализ запросов, экспорт/импорт и проч.), которые часто необходимы для крупных проектов, где важны тонкая настройка и анализ работы системы.
Компоненты СУБД
СУБД — это сложный программный комплекс, над созданием которого трудятся высококвалифицированные специалисты. Несмотря на то что разные СУБД могут существенно отличаться друг от друга, можно в обобщённом виде выделить типовые компоненты.
-
Участники работы с БД
- Администратор БД (Database Administrator, DBA): разрабатывает проект, настраивает структуру БД, определяет схемы резервного копирования, управляет безопасностью, отслеживает производительность, вносит изменения по мере необходимости.
- Программисты (разработчики клиентских и серверных приложений): больше внимания уделяют созданию форм ввода и отчётов, интеграции с другими системами, написанию кода, взаимодействующего с БД.
- Конечные пользователи: обычно работают с заранее разработанными формами и отчётами; иногда даже не осознают, что система использует СУБД.
-
Модули, обрабатывающие SQL-запросы
- Процессор запросов: принимает инструкции SQL и переводит их в «понятные» ядру СУБД низкоуровневые операции.
- Оптимизатор запросов: определяет оптимальный план выполнения, используя индексы и статистику.
- Система управления транзакциями: координирует обработку обновлений и решает, как фиксировать или откатывать результаты.
-
Модуль безопасности
- Контроль прав доступа: проверяет, имеет ли пользователь право выполнять данную операцию (чтение, запись, удаление), сверяет логин/пароль и уровень привилегий.
- Модуль целостности: следит за соблюдением ограничений (доменных, ссылочных и т. д.), используя данные из системного каталога.
-
Системный каталог (словарь данных)
- Это «мозг» СУБД, хранящий метаданные обо всех элементах базы. Здесь описаны все объекты БД: таблицы, индексы, представления, типы данных, ограничения, пользователи, статистическая информация.
- В большинстве СУБД системный каталог реализован в виде специальных служебных таблиц, скрытых от обычных пользователей.
-
Контроллер БД
- Обеспечивает взаимодействие с файлами, где фактически хранятся данные и системный каталог.
- Использует стандартные механизмы операционной системы (чтение, запись, блокировки на уровне файлов и т. д.).
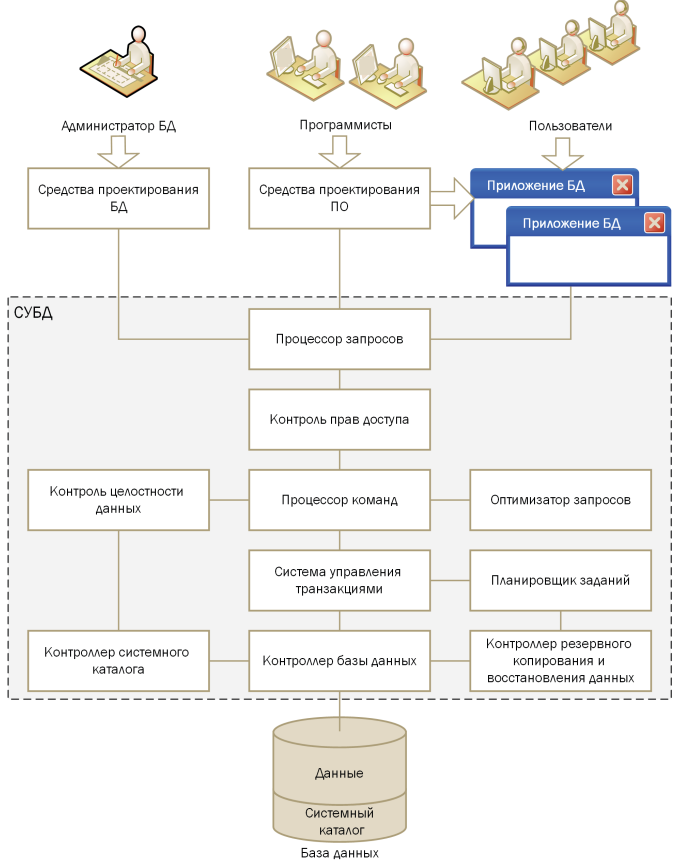
Архитектурные решения доступа к БД
«Файл-сервер»
Файлы базы находятся в сетевой папке сервера. Приложение (клиент) на рабочей станции напрямую открывает и модифицирует файлы, по сути, перекачивая их через сеть.
Недостатки.
- Высокая нагрузка на сеть при чтении и записи больших объёмов данных.
- Управление параллельностью и целостностью усложнено, так как несколько клиентов могут работать с одной и той же «кусочной» информацией.
- На каждом рабочем месте нужно устанавливать или дублировать основные модули СУБД.
Такой подход применялся в начале развития микрокомпьютеров и до сих пор сохраняется в самых простых решениях (например, Microsoft Access при одновременной работе нескольких человек).
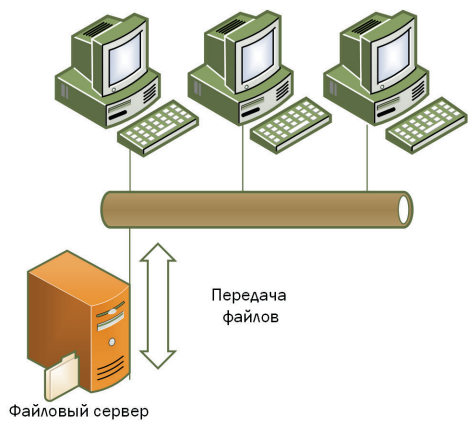
«Клиент-сервер»
На выделенной машине разворачивается полноценный сервер СУБД, где хранятся файлы базы. Клиентские приложения общаются с ним через язык SQL или другое протокольное API, передавая запросы и получая результаты.
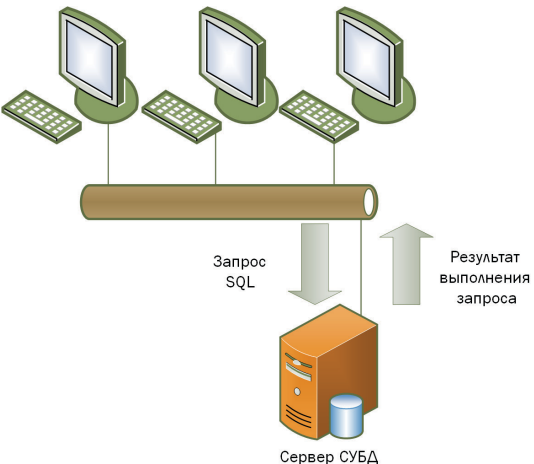
Преимущества.
- Централизованное хранение: легко управлять безопасностью и резервным копированием.
- Эффективность: по сети передаются только результаты выполнения запроса, а не весь файл.
- Параллельная работа: сервер СУБД умеет распределять нагрузку, блокировать данные на уровне строк или страниц, управлять транзакциями.
- Прозрачность: клиенты могут работать в разных ОС (Windows, Linux и т. д.), если имеются нужные драйверы и сетевые протоколы.
Варианты распределения логики между сервером и клиентом:
- Тонкий клиент (Thin Client): клиент предоставляет лишь интерфейсную часть (формы, экранные поля, кнопки); вся «бизнес-логика» и механизмы проверки сосредоточены на сервере.
- Толстый клиент (Fat Client): часть логики по обработке данных, проверке бизнес-правил и даже формированию SQL-запросов переносится на рабочую станцию пользователя.
Примеры СУБД: MySQL, Oracle, Microsoft SQL Server, PostgreSQL, InterBase, Firebird и др.
Многоуровневая архитектура
Иногда между клиентом и сервером БД вводят дополнительный уровень — сервер приложений. Клиент уже не подключается напрямую к СУБД, а взаимодействует с этим промежуточным сервером, который:
- инкапсулирует бизнес-логику;
- контролирует трансляцию данных для разных клиентов;
- может масштабироваться и балансировать нагрузку.
Технологии: CORBA, DCOM, SOAP, RPC, сокеты и т. д.
Преимущества: гибкость, возможность интеграции разных систем, централизованное управление логикой.
Недостатки: сложность проектирования и большие требования к квалификации разработчиков.
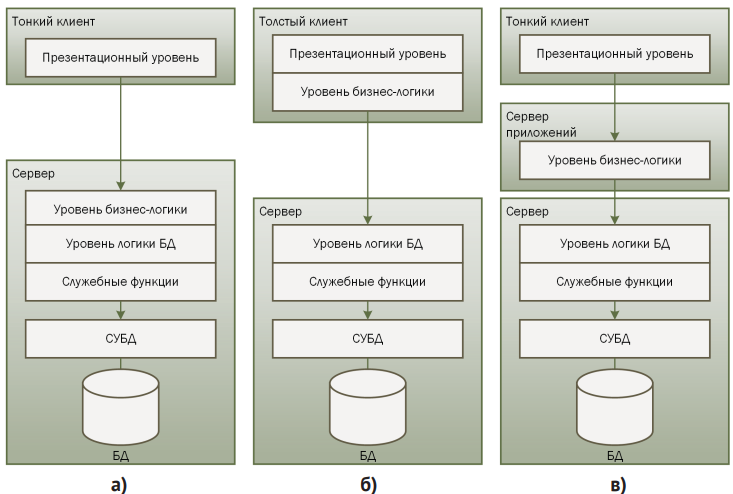
Распределенная система
В распределённых БД данные могут храниться на нескольких серверах, часто географически удалённых. Для пользователя это может выглядеть как единая база, хотя за кулисами происходит обмен между узлами, осуществляются механизмы репликации и фрагментации.
- Гомогенные (все узлы используют одну и ту же СУБД).
- Гетерогенные (узлы разных производителей, возможна конвертация форматов).
Распределённые БД повышают отказоустойчивость (при падении одного узла система продолжает работать), но усложняют администрирование (нужно синхронизировать данные, следить за целостностью во всех сегментах).
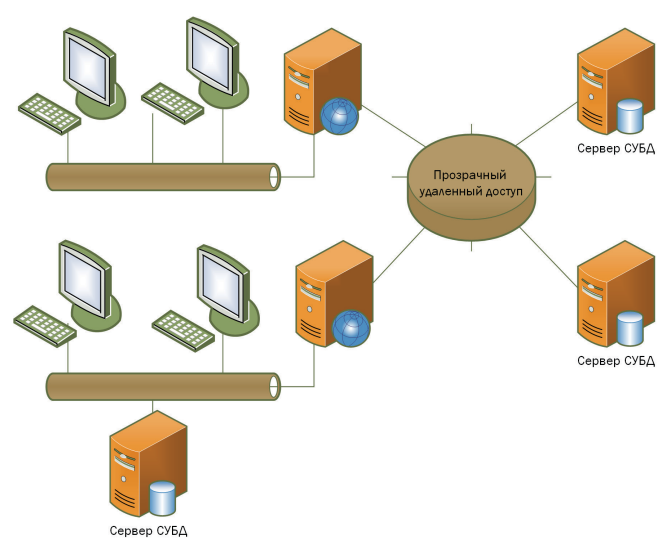
«Реляционная модель»
Реляционный подход был разработан математиком Эдгаром Фрэнком Коддом (1923–2003). В июне 1970 года он опубликовал статью «Реляционная модель данных для больших совместно используемых банков данных» (Codd E. F. A Relational Model of Data for Large Shared Data Banks. CACM 13: 6), в которой впервые сформулировал концепцию реляционной модели.
Первопричиной возникновения нового по тем временам подхода к проектированию баз данных послужили существенные ограничения предыдущих моделей. Сетевая и иерархическая модели, существовавшие до реляционной, оказались сложными в управлении и непонятными широкому кругу пользователей. Кодд стремился найти способ, сочетающий математическую строгость (опора на теорию множеств) с высокой доступностью и простотой при проектировании.
Реляционная модель предлагает рассматривать базу данных как совокупность связных двумерных таблиц (отношений). При этом каждая таблица отражает некоторую сущность и её свойства, а теория множеств обеспечивает математическое обоснование для операций над этими таблицами.
«Модель данных» — это логическая конструкция, описывающая объекты базы и операции над ними. Чтобы она стала реальной БД, её нужно физически реализовать в конкретной СУБД.
Любая реляционная база данных начинается с понимания того, какие объекты (или сущности) будет описывать система и какими признаками (или атрибутами) эти объекты обладают.
Основные понятия
Сущность (entity) – это обобщённый класс объектов, подлежащих хранению в базе. Чаще всего сущность отвечает на вопросы «Кто?» или «Что?». Например, в библиотеке: «Автор», «Книга», «Читатель», а в авиакомпании: «Рейс», «Самолёт», «Пассажир». Экземпляр сущности — это конкретный представитель данного класса. Если сущность – это «Книга», то экземплярами будут «Война и мир» и «Ромео и Джульетта»; если сущность – это «Самолёт», то экземплярами станут конкретные борты с их уникальными номерами.
«Экземпляр сущности» в реальной СУБД соответствует отдельной строке в реляционной таблице.
У каждой сущности есть отличительные свойства, которые в базе данных называются атрибутами. Например, самолёт может иметь такие характеристики, как марка, максимальная скорость, дата выпуска, а читатель — имя, номер телефона и адрес. При проектировании БД нужно выбирать именно те параметры, которые важны для решения прикладных задач, отбрасывая избыточные или неактуальные.
- Простые. Хранят одно однозначное значение (например, «Название», «Дата рождения»).
- Составные. Объединяют несколько более мелких значений, часто встречаются с адресами (город, улица, индекс и т. д.).
- Производные. Вычисляются на основе других полей. Так, налог может рассчитываться в проценте от заработной платы; возраст сотрудника – из «даты рождения» и «текущей даты».
- Многозначные. Позволяют хранить несколько значений в одном атрибуте, например список телефонов. В классической реляционной модели предпочтительнее создавать отдельную таблицу для таких данных, но иногда допускают многозначные поля для упрощения проекта.
В современных БД в качестве многозначных атрибутов в современных СУБД (например, PostgreSQL) часто используются тип данных, хранящий данные в формате
JSON.
При проектировании БД крайне важно предусмотреть такой атрибут, который уникально отличает один экземпляр сущности от другого. В одном случае это номер паспорта (для человека), в другом — заводской номер (для самолёта). Часто разработчики выбирают искусственное автоинкрементное поле, которое получает новое значение при каждой вставке строки, исключая дубликаты.
Идентифицирующие атрибуты впоследствии становятся ключами (первичными) в реляционных таблицах. Они гарантируют, что все экземпляры сущности различимы и система может безошибочно обращаться к нужной записи.
Тип данных и домен
Чтобы описать конкретный атрибут, в базе данных необходимо указать, какого типа там будут храниться значения. Однако одного выбора типа (целое число, строка, дата и т. д.) часто оказывается недостаточно, поэтому вводят дополнительные ограничения, которые называются доменами.
В любой СУБД или языке программирования мы встречаемся с вопросом, как хранить определённую информацию:
- Числа могут быть целыми (
INTEGER) или вещественными (FLOAT,REAL). - Тексты обозначаются строковыми типами (
CHAR,VARCHAR).Вопрос. Чем отличаются типы
CHARиVARCHAR? - Даты и время имеют собственные типы (
DATE,DATETIME,TIMESTAMP).
Типизация указывает размер занимаемой памяти и определяет допустимые операции. Так, невозможно складывать строку «ABC» с числом 123 без явного преобразования, а результат деления никогда не занесётся напрямую в целое поле, если в нём не учесть округление.
Тип данных задаёт физический формат хранения: сколько байт отвести, как распознавать содержимое. Но не решает, логично ли значение (например, «телефон» в виде числа с ведущим нулём или «дата рождения» в формате доисторического периода).
Понятие домен расширяет тип данных дополнительными логическими правилами и ограничениями, более близкими к реальной предметной области. К примеру,
- Почтовый индекс в России — это строго 6 цифр. Просто задать тип
CHAR(6)означает «6 символов», но не проверяет, что там действительно цифры. Если же мы опишем домен индекса как «строка из 6 цифр», то СУБД не допустит ввода букв или 7-значных значений. - Дата рождения сотрудника не должна позволять указывать год, далёкий от разумных человеческих пределов (скажем, не меньше 1900 и не больше текущего дня). Стандартный тип
DATETIMEтакого ограничения сам по себе не накладывает, поэтому домен накладывает нужные проверки.
Домены помогают реализовать целостность доменов, когда значения в каждом поле не просто «формально соответствуют» типу (число или текст), но и «логически корректны» с точки зрения конкретной задачи.
В реляционной модели предусмотрен особый определитель NULL, который означает «неизвестно» или «не определено». Это может потребоваться, если:
- Студент поступил в вуз, но ему ещё не выдали зачётную книжку, и её номер неизвестен.
- Сотруднику пока неизвестен адрес (он сменил место жительства).
Связь между сущностями
После того, как мы определись с тем, какие сущности (объекты) нужно хранить, наступает черёд понять, как они взаимодействуют. Такой «вектор связи» между ними обычно выражается глаголом: «Автор написал книгу», «Заказчик оформил заказ», «Пассажир летит рейсом».
Типы связей:
- Один к одному (1:1). Встречается достаточно редко. Обычно говорит о том, что избыточно выделили отдельную сущность вместо атрибута.
- Один ко многим (1:N). Наиболее распространённая ситуация: один автор может написать много книг, один отдел — иметь много сотрудников.
- Многие ко многим (M:N). В классической реляционной модели не поддерживается напрямую. Решается путём ввода промежуточной таблицы: так связь M:N разбивается на две связи 1:N.
Если у вас возникла связь «1:1», вполне возможно, что это атрибут, а не отдельная сущность.
С точки зрения реляционной модели, вся информация представлена в виде двумерных таблиц, называемых отношениями. Каждая сущность из реального мира (например, «Книга», «Самолёт», «Сотрудник») имеет отдельную таблицу, где:
- Строка (кортеж) хранит информацию об одном экземпляре сущности: одной конкретной книге или одном сотруднике.
- Столбец (атрибут) соответствует определённой характеристике (название, автор, телефон, адрес и т. д.).
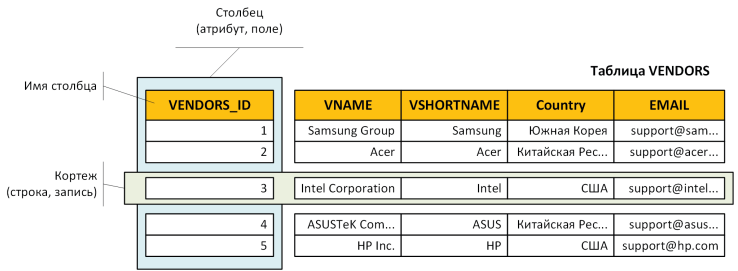
Требования к реляционной таблице:
- Уникальные имена столбцов. В пределах одной таблицы имя атрибута не должно повторяться.
- Каждая строка описывает одну сущность. Нельзя «мешать» сущности «Книга» и «Автор» в одной таблице, если это разные объекты.
- Отсутствие идентичных строк. Если две строки полностью совпадают, система не может однозначно понять, какую именно из них обновлять или удалять.
- Атомарные значения в ячейках. Запрещается хранить в одной ячейке «список» из нескольких элементов (например, три адреса сразу).
- Нет жёсткого порядка строк и столбцов. Можно выводить их в любом порядке при помощи SQL (ORDER BY, выбор столбцов и т. д.).
Замечание
Когда таблица удовлетворяет этим условиям, о ней говорят, что она приведена хотя бы к первой нормальной форме (1NF). В более развитых нормальных формах дополнительные требования ужесточают логику и уменьшают дублирование данных.
Для того чтобы однозначно найти нужную строку в таблице, в реляционной модели используют систему ключей.
Первичный ключ (Primary Key, PK) Это особое поле или набор полей, которые уникально идентифицируют каждую строку. Чаще всего создают искусственное целочисленное поле с автоинкрементом (ID), которое при добавлении новой записи получает очередное значение, исключая дубликаты.
- Естественный ключ (номер паспорта, VIN автомобиля) тоже можно использовать, но тогда изменение этого реального номера (например, при замене документа) приводит к сложностям в БД.
- Автоинкрементный ключ остаётся неизменным, не зависит от внешних обстоятельств и упрощает администрирование.
Внешний ключ (Foreign Key, FK)
Позволяет связать одну таблицу с другой. Значение во внешнем ключе указывает на первичный ключ «родительской» таблицы. Допустим, если у «Сотрудника» есть поле ID_Отдела, то в нём хранятся значения ID из таблицы «Отделы». Если запись «Отдел кадров» имеет ID=3, а у сотрудника Арбузова ID_Отдела=3, то мы знаем, что он работает именно в этом отделе.
Целостность данных
В реляционной модели важно не только сохранить нужные строки и столбцы, но и убедиться, что данные отражают объекты реального мира без противоречий. Для этого существуют несколько уровней целостности.
Целостность доменов Каждое поле обязано соответствовать описанному домену. Если мы утвердили, что «Дата рождения» не может быть старше 150 лет или позже текущей даты, БД должна блокировать любые неуместные значения. Аналогично с другими полями: почтовый индекс, код города и т. д.
Целостность сущностей Требует, чтобы каждая строка была уникальной и имела корректный первичный ключ. Если ключ состоит из нескольких атрибутов (составной ключ), ни один из этих атрибутов не может быть NULL. Кроме того, можно закладывать дополнительные проверки (например, студент не может одновременно числиться на двух дневных факультетах, если это нарушает логику вуза).
Ссылочная целостность Если таблицы связаны внешними ключами, нельзя допускать «осиротевших» ссылок. Если родительская запись удаляется, дочерняя или корректно обрабатывается (удаляется, обнуляется, запрещается удаление), или обновляется так, чтобы ссылки оставались непротиворечивыми.
Корпоративная целостность Вся специфика конкретных бизнес-правил, присущих организации. Например, если читатель взял книгу в библиотеке и не вернул её в срок, нельзя выдавать ему новую; если кладовщик разместил молоко в несоответствующем месте, БД должна это блокировать. Эти правила обычно внедряют с помощью триггеров и хранимых процедур, которые автоматически проверяют нужную логику при вставке, обновлении или удалении данных.
Соблюдение целостности данных напрямую влияет на качество работы базы и точность отражения реальности. Даже если формально есть правильные таблицы, но нет защиты от нелепых значений и нарушений связей, результаты будут далеки от истины.
Реляционная алгебра
Реляционная алгебра — это теоретический язык для манипулирования данными, основанный на теории множеств. Она вводит операции, которые создают новые «отношения» (таблицы) из уже имеющихся, что дало основу для языка SQL.
- Выборка (selection, σ). Забирает из исходной таблицы только те строки, которые удовлетворяют заданному условию (например, «Студенты, родившиеся в 2000 году»).
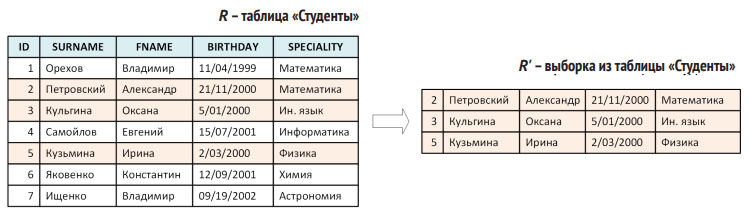
- Проекция (projection, ↓). Формирует новую «таблицу», в которой остаются только нужные столбцы. Все строки сохраняются, но отбрасываются ненужные поля.
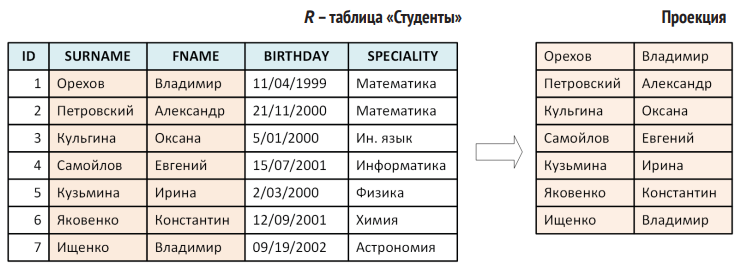
- Декартово произведение (×). Каждая строка одной таблицы совмещается со всей совокупностью строк другой. Получается множество пар (или троек, если продолжать), что служит основой для будущих соединений. На практике используется достаточно редко.
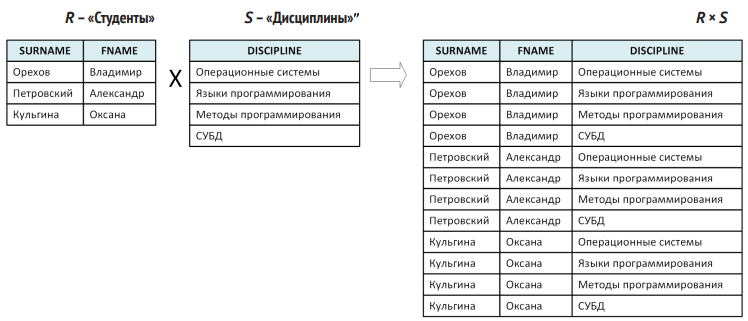
- Объединение (union, ∪). Складывает вместе совместимые по структуре таблицы, объединяя их строки и удаляя дубликаты.
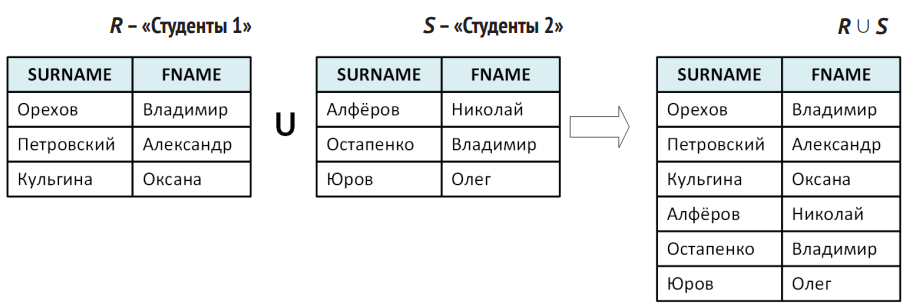
- Разность (set difference, –). Выбирает строки, которые присутствуют в одной таблице и отсутствуют в другой (подобно вычислению, кто не сдал экзамен, если сравнить «список студентов группы» минус «студенты, сдавшие экзамен»).
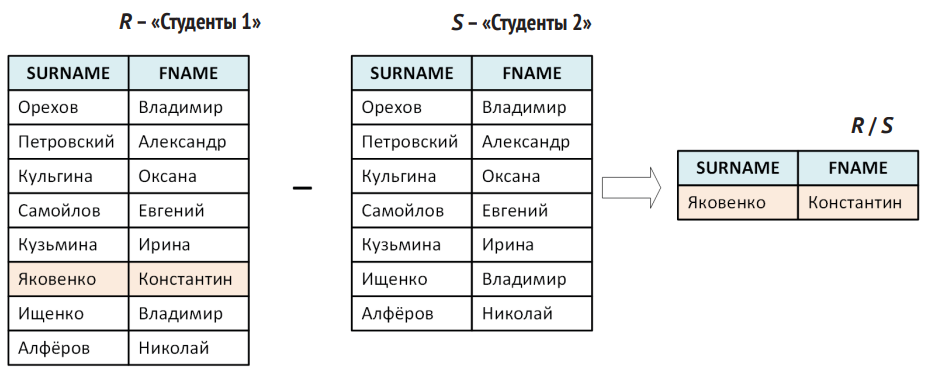
- Пересечение (intersection, ∩). Выбирает строки, которые встречаются в обеих таблицах.
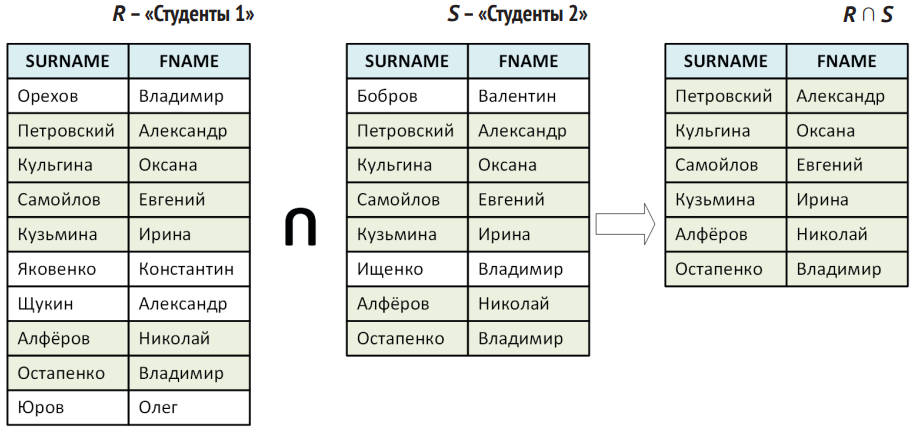
- Деление (division, ÷). Полезная, но менее очевидная операция. Даёт возможность понять, какие объекты «выполнили весь набор» заданных условий. Нужно учитывать две вещи:
- Результат деления исходной таблицы R на таблицу-делитель S будет содержать столбцы, отсутствующие в делителе;
- В качестве строк в результат P войдут только те записи из делителя S, что при декартовом произведении результата на делитель P × S содержатся в делимом R.
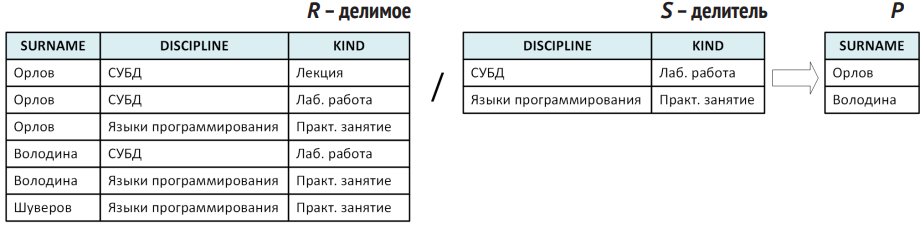
- Соединение (join, ⨝). Главный инструмент для связывания информации в реляционных системах. Обычно комбинация «декартово произведение + условие равенства по ключевым полям» (естественное соединение). Также бывают внешние соединения (left join, right join), при которых «недостающие» строки одной из таблиц тоже сохраняются.
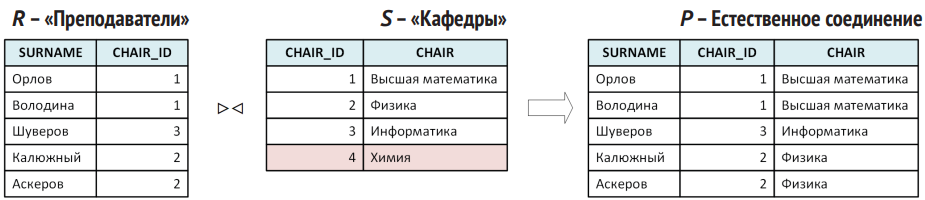
Естественное соединение складывает строки, у которых совпадают значения связующих полей (первичных и внешних ключей), и не включает те, где соответствий нет. Внешнее соединение (outer join) может добавить ещё и «брошенные» строки, проставляя в пустых местах
NULL.
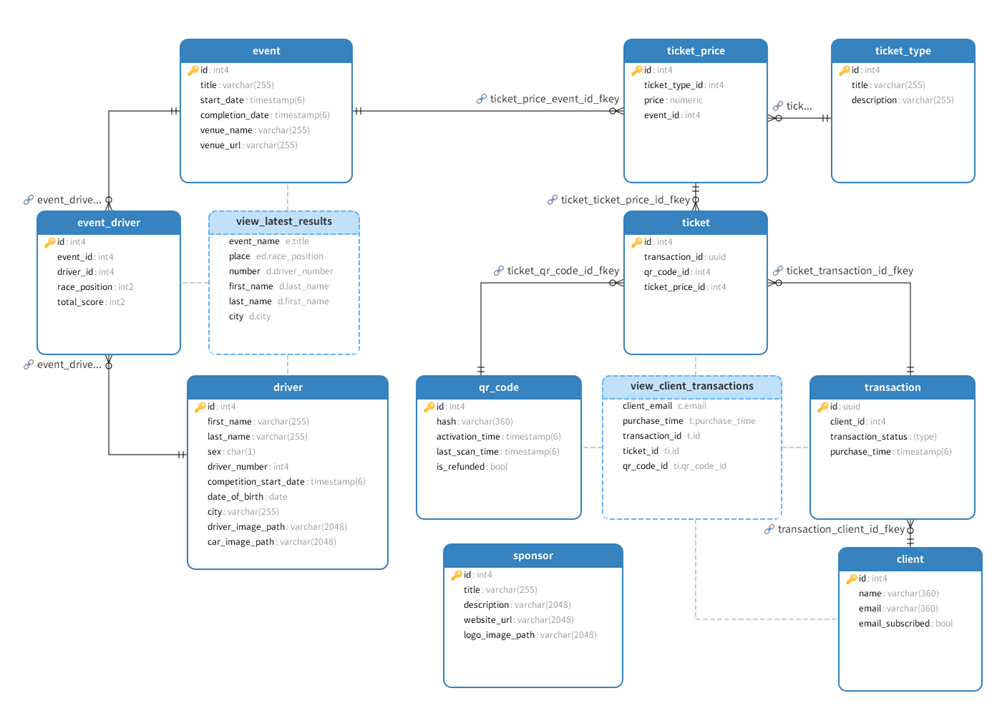
Практическое задание
На сайте aermolenko.ru выполнить задания в модулях 1-3 по дисциплине Базы данных.
Проектирование БД (ER-модели)
Концептуальное проектирование и ER-модель
Одной из важнейших трудностей в создании программного продукта считается нахождение взаимопонимания между разработчиком и заказчиком. Когда речь заходит о базах данных, сложность возрастает, поскольку специалист по СУБД мыслит категориями таблиц, индексов и транзакций, в то время как заказчик говорит про накладные, поставки, спецификации или оборудование. Экономисты, бухгалтеры или инженеры часто точно знают, какая информация должна храниться, но не представляют, как описывать это в терминах программирования. Параллельно программист, обладающий глубокими знаниями о реляционной теории, алгоритмах и языках SQL, может не знать тонкости бизнеса и технические нюансы предметной области.
Чтобы устранить это противоречие, в проектировании баз данных принято выделять этап концептуального проектирования. На нём разработчик и представители бизнеса пытаются выявить и зафиксировать ключевые сущности, необходимые для автоматизации реального предприятия, и определить их взаимосвязи. Пока не рассматривается, какая конкретно СУБД будет использована, как именно будут храниться файлы и где разместить индексы. Технические детали остаются за рамками, потому что в первую очередь важно отразить суть бизнеса.
Задачи концептуальной модели
В ходе концептуального проектирования создаётся обобщённая модель информации, которая должна быть представлена в БД. Эта модель не учитывает особенности SQL, аппаратные ограничения, детали операционной системы или оптимизацию хранения на диске. Цель – сформировать высокоуровневое понимание данных: какие объекты (сущности) должны храниться, какие у них атрибуты и какие связи между ними существуют. Подобный подход даёт свободу в выборе дальнейших архитектурных решений, а также упрощает процесс обсуждения с заинтересованными лицами, поскольку им проще рассматривать наглядные схемы, чем перечень реляционных таблиц или исходный код.
ER-модель (сущность–связь)
Для визуального и интуитивно понятного представления на концептуальном уровне была создана модель «сущность–связь», анонсированная Питером Ченом в 1976 году в работе «The Entity-Relationship Model. Toward a Unified View of Data». Эта модель опирается на несколько базовых понятий:
- Сущность (Entity). Является обобщённой категорией объектов из реального мира, о которых требуется хранить сведения. Примеры: «Сотрудник», «Договор», «Самолёт», «Книга», «Цех» и т. п.
- Атрибут (Attribute). Отражает свойства сущности, которые помогают характеризовать конкретный объект. Примером служат «Имя» и «Фамилия» для сотрудника, «Номер рейса» для самолёта, «Название» для книги.
- Связь (Relationship). Описывает, каким образом сущности взаимодействуют между собой. Например, один сотрудник работает в одном отделе, а один отдел содержит многих сотрудников; книга пишется одним или несколькими авторами и т. д.
При построении диаграмм ER-модели сущности обычно рисуются прямоугольниками, атрибуты — эллипсами, а связи — ромбами, которые соединяют соответствующие сущности.
Сильные и слабые типы сущностей
В ER-диаграммах различаются сильные и слабые сущности. Сильная сущность способна существовать отдельно, а слабая зависит от «родительской» сущности. К примеру, «Сотрудник» может быть слабой сущностью по отношению к «Отделу», если не имеет смысла существование сотрудника вне отдела. На диаграмме сильный тип сущности изображается обычным прямоугольником, а контур слабого типа сущности рисуется двойной линией.
Атрибуты сущностей
Каждая сущность обладает набором атрибутов, которые могут быть:
– простыми (одно значение, например «Имя»);
– составными (адрес или ФИО, которые объединяют несколько податрибутов);
– многозначными (несколько телефонных номеров);
– производными (значения, получаемые расчётом, например возраст, вычисляемый из даты рождения).
В реляционных таблицах производные атрибуты редко когда превращаются в реальные столбцы таблицы, физически хранящие значения. Ведь нет смысла занимать память под данные, которые можно получить путем элементарных вычислений.
На диаграмме производные атрибуты обычно окружены пунктирной линией, а многозначные — двойной. Если атрибут является идентификатором (первичным ключом в будущем), его название подчёркивается.
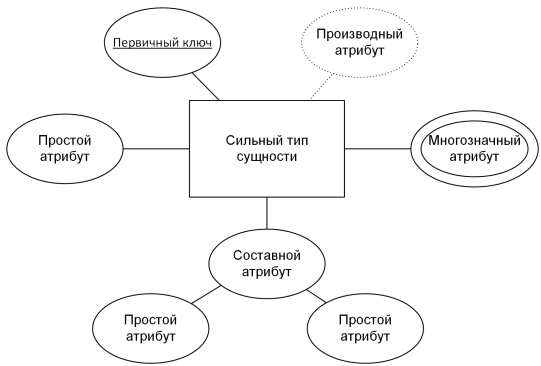
Связи в ER-модели
При концептуальном проектировании особое внимание уделяется тому, как объекты взаимодействуют. Часто встречаются три основных типа:
- 1:1 (например, «человек – паспорт»).
- 1:N (например, «отдел – сотрудники»).
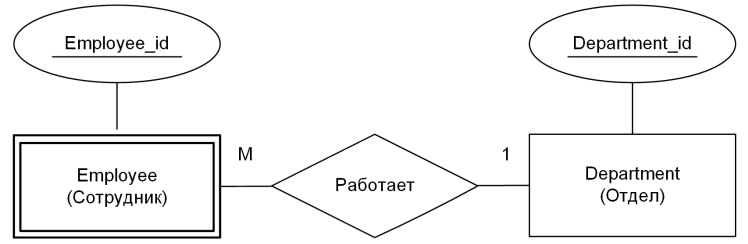
- M:N (например, «книга – авторы» или «заказ – товары»).
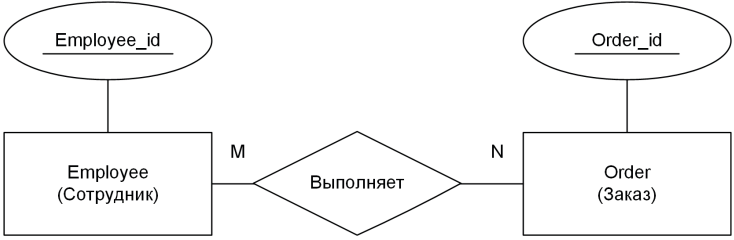
При этом связь M:N в классической реляционной БД прямо не поддерживается и в дальнейшем логическом проектировании преобразуется путём введения «коммутирующей» таблицы. Дополнительный тип сущности разрывает связь M:N пополам, что позволяет нам трансформировать неподъемное для реляционных баз данных отношение «многие ко многим» в пару обычных связей «один ко многим». Вне зависимости от всех хитросплетений нашей ER-модели искусственно созданная сущность-коммутатор в любом случае будет содержать два атрибута для внешних ключей.
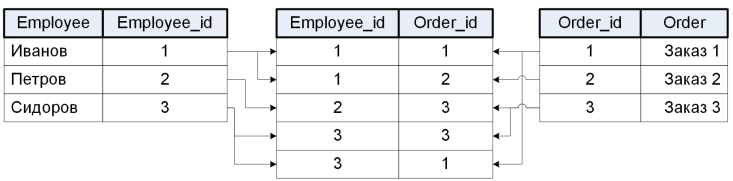
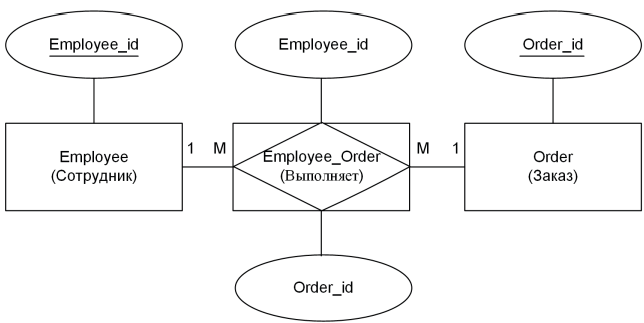
Кроме бинарных связей встречаются унарные (рекурсивные).Замыкание типа сущности на самого себя окажется весьма полезным при описании многоуровневых иерархических структур, подобных классификатору товаров, хранящихся на складе. Возможны и связи более высоких порядков (тернарные и т. д.), когда одна и та же связь объединяет три или более сущностей, но при реальной реализации чаще всего такая связь разбивается на несколько бинарных.
На практике для построения иерархии реальной реляционной таб лице потребуется как минимум три столбца: поле первичного ключа «Goodsclass_id», поле внешнего ключа «Parent_id» и содержащее названия категорий текстовое поле «Goodsclass». Рекурсивная связь между
записями таблицы обеспечивается за счет взаимодействия внешнего и первичного ключей, с этой целью поле внешнего ключа дочернего элемента хранит значение первичного ключа родительского узла. Если же идет речь о самом старшем элементе иерархии, который никому не подчинен (в нашем примере во главе дерева расположена папка «Классификатор»), то в его внешнем ключе окажется определитель NULL.

Вариации ER-моделей и CASE-системы
Модель Чена оказалась настолько удачной, что на её основе возникло несколько нотаций. Одна из популярных – Crow’s Foot («воронья лапка»), предложенная Чарльзом Бэчмэном. Там связи рисуются линиями, причём сторона «N» выглядит как «лапка», а сторона «1» изображается в виде одиночной черты. Существуют и другие варианты: IDEF1X, ERwin, PowerDesigner и т. д. Многие современные CASE-средства предоставляют графический интерфейс, позволяющий рисовать ER-диаграммы «наглядно», после чего могут автоматически генерировать структуры SQL для определённой СУБД.
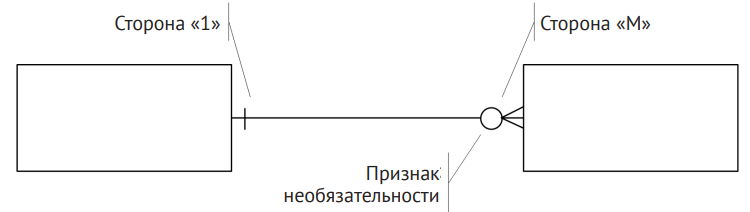
Что получается в итоге?
Главным результатом становится набор схем, диаграмм и пояснений, отражающих реальную предметную область в удобном для понимания виде. Подобное представление даёт возможность проверить, действительно ли система точно отражает логику предприятия, и убедиться, что все ключевые объекты и связи учтены. После согласования концептуальной модели наступает очередь логического проектирования.
Логическое проектирование и нормализация
На логическом уровне происходит преобразование концептуальной ER-схемы в набор реляционных таблиц. Каждая сущность превращается в отдельную таблицу, а атрибуты становятся столбцами. Связи воплощаются через первичные и внешние ключи. Однако недостаточно просто «механически» перенести объекты на таблицы. Структура нуждается в проверке на отсутствие аномалий (нежелательных ситуаций при вставке, удалении или обновлении строк). Для этого применяется процесс нормализации.
Ненормализованные таблицы могут содержать дублирующуюся информацию и некорректно отражать реальные объекты. Подобная избыточность может казаться безобидной, пока не приходится вносить изменения или добавлять новые данные. На этом фоне возникают три характерных вида аномалий — вставки, удаления и редактирования.
-
Аномалия вставки. В ненормализованной таблице при добавлении новой строки может оказаться, что требуется ввести лишнюю информацию, не относящуюся к сути добавляемых данных. Для примера — если по каждому товару приходится повторять одни и те же сведения о поставщике или накладной. Бывает и обратная ситуация: невозможно корректно вставить запись, пока не заполнены обязательные поля, которые пока неизвестны (например, номер накладной для товара ещё не получен). Компьютеру не ясно, что пустые поля означают «те же данные, что и в предыдущей строке», и это приводит к конфликтам или неполным записям.
-
Аномалия удаления. При удалении одной строки может утратиться информация, ценная для других записей. В примере склада указывается удаление ошибочно внесённого товара (жёсткого диска), а вместе с ним — потери сведений о накладной, поскольку поля накладной дублировались только в этой строке. В итоге оставшиеся товары «теряют» связь с накладной или переходят под другую. Лишние перемещения данных с одной строки в другую усложняют работу и могут приводить к полному рассогласованию учёта.
-
Аномалия обновления (редактирования). Если одинаковые сведения (название поставщика, классификатор товара, производителя) присутствуют во множестве строк, то при изменении одного из этих значений придётся искать и исправлять все дубликаты. Пропуск хотя бы одной строки приведёт к тому, что в базе будут сосуществовать старый и новый варианты. Тот же «классификатор» «Память» → «Модуль памяти» придётся массово переправлять во всех строках, что создаёт риск ошибиться или оставить часть ячеек без обновления.
Такие ситуации особенно ярко проявляются в примере с одним большим листом Excel, где дублируются названия поставщиков или другие поля.
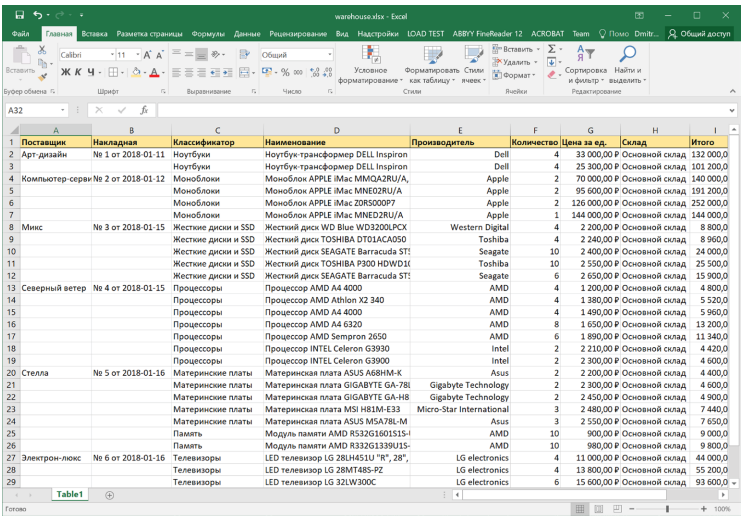
Нормализация последовательно упорядочивает реляционные таблицы, устраняя повторяющиеся группы и расщепляя слишком «тесно связанные» столбцы. Этот процесс идёт ступенчато через нормальные формы: 1NF → 2NF → 3NF (затем BCNF, 4NF, 5NF). На каждой ступени таблица приобретает новые свойства, позволяющие избавиться от очередного типа аномалий.
Первая нормальная форма (1NF)
Неделимость (атомарность) значений
Основа 1NF — отсутствие повторяющихся групп и соблюдение атомарности. Если в одной ячейке хранится список значений (к примеру, «фантастический комедийный боевик» для жанров кино), это нарушает 1NF. С точки зрения реляционной теории каждая ячейка должна содержать строго одно значение. Аналогичная проблема возникает, если в ячейке объединён номер накладной и дата в виде «45/12.05.2021». Атомарность означает, что номер накладной и дата должны храниться отдельно.
Часто встречающимся примером нарушения атомарности становится хранение нескольких телефонных номеров в одном поле или перечисление категорий через точку с запятой. Для приведения к 1NF рекомендуется либо выделять отдельную таблицу для многозначных атрибутов, либо реализовать иной механизм хранения.
Под атомарностью значения понимается, с одной стороны, его целостность, а с другой – неделимость. Разделение данных на «атомы» впоследствии позволит нам вооружить БД дополнительным сервисом, в частности разнообразными способами сортировки данных и расширенными методами фильтрации и поиска данных.

Функциональные зависимости и их роль
Нормализация — это не только механическое разделение таблиц, но и анализ функциональных зависимостей. При записи A → B считается, что значению A соответствует единственное значение B (A — детерминант, B — зависимый атрибут). Различают несколько типов:
-
Частичная зависимость. Атрибут зависит лишь от части составного ключа (например, если ключ состоит из полей «Номер накладной» + «Дата», а какой-либо столбец зависит только от «Номера»). Подобная ситуация мешает 2NF и указывает на необходимость выносить зависимый столбец в отдельную таблицу или вводить искусственный ключ.
-
Полная зависимость. Каждый неключевой атрибут связан сразу со всей совокупностью ключа (или ключом из одного столбца). Пример: «ИНН» ↔ «ФИО владельца». Нет избыточного повторения, поскольку каждому значению ИНН строго соответствует одна фамилия, имя и отчество и наоборот.
-
Транзитивная зависимость. Возникает, если атрибут A зависит от B, а B — от C, при этом A косвенно зависит от C. В примере склада «Поставщик» может зависеть от «НомерНакладной + Дата», а «Производитель» относится уже к конкретному наименованию товара, и получается цепочка зависимостей. Транзитивность даёт повод выделять отдельные таблицы для тех групп атрибутов, которые связаны через «промежуточные» поля. Удаление транзитивных зависимостей обеспечивает третью нормальную форму (3NF).
-
Многозначная зависимость. Обозначает связь, при которой одному значению A сопоставляется набор значений B. Это прямая предпосылка наличия связи «многие ко многим» (M:N). Во избежание аномалий такая структура разносится на отдельную промежуточную таблицу, что соответствует четвёртой нормальной форме (4NF).
Наряду с зависимыми могут быть независимые атрибуты — те, что вообще никак не связаны между собой. К примеру, если «Поставщик» и «Склад» не влияют друг на друга напрямую, то в терминах функциональных зависимостей будет записано A ¬→ B и B ¬→ A. Когда таблица грамотно декомпозирована и ключи расставлены, функциональные зависимости становятся прозрачнее, а риск аномалий заметно снижается.
Вторая нормальная форма (2NF)
Частичные зависимости
Таблица соответствует 2NF, если в ней отсутствуют частичные зависимости неключевых атрибутов от части составного ключа. Если ключ составной, то некоторые столбцы могут зависеть только от одного из компонент ключа, что нежелательно. Чаще всего 2NF достигается, когда вместо составных ключей используются искусственные (суррогатные) первичные ключи, например поле-счётчик (INTEGER IDENTITY) или GUID. Тогда не возникает частичных зависимостей, так как ключ состоит из единственного поля.
Предположим, что мы определили составной первичный ключ таблицы на основе атрибутов «Номер накладной», «Дата накладной» и «Наименование». Обсудим это решение с точки зрения частичных функциональных зависимостей. Наличие составного ключа привело к тому, что такой атрибут, как «Поставщик», зависит от первой половины ключа («Номер накладной» и «Дата накладной»), а атрибут «Производитель» зависит от другой части ключа – «Наименование». Следовательно, наша исходная таблица не соответствует требованиям 2NF.
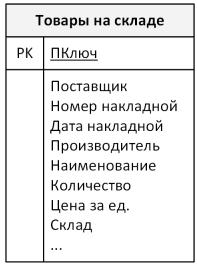
После приведения к 2NF между атрибутом ключа «ПКлюч» и любым другим столбцом таблицы установилось однозначное соответствие, частичные зависимости устранены.
Третья нормальная форма (3NF)
Транзитивные зависимости
3NF убирает транзитивные зависимости, при которых атрибут A зависит от B, а B зависит от ключа, и потому A косвенно зависит от ключа. Типичный пример — поля, указывающие имя поставщика, когда сам поставщик связан с другой таблицей. В 3NF требуется вынести такие группы столбцов в отдельные таблицы, чтобы каждый атрибут зависел напрямую только от первичного ключа. При выполнении 3NF обычно формируется несколько «справочных» таблиц (например, для производителей, категорий, типов и т. п.), а в основной таблице остаются лишь идентификаторы и ключи.
В таблице склада посредников больше чем достаточно – она прячет в себе несколько транзитивных зависимостей. Очевидный пример транзитивности – «Поставщик». Указанный атрибут непосредственно связан лишь с атрибутами, описывающими накладную («Номер накладной» и «Дата накладной»), а все остальные атрибуты связаны с «Поставщик» транзитивно.
Исправим сложившуюся ситуацию:
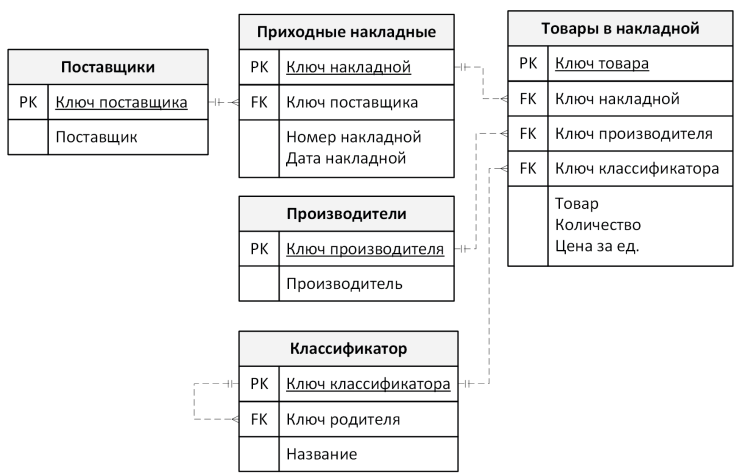
Справочные таблицы также имеют ряд очевидных преимуществ:
- существенно сокращается физический размер дочерней таблицы.
- при редактировании значения (например, переименование поставщика) нет необходимости просматривать сотни записей, а достаточно изменить одно значение в справочной таблице;
- при вводе данных значительно снижается вероятность появления ошибки пользователя, так как вместо ввода с клавиатуры ему предлагаются на выбор заранее подготовленные значения.
Формы BCNF, 4NF, 5NF
– BCNF (нормальная форма Бойса–Кодда) усиливает требования 3NF для случаев, когда в таблице имеется несколько потенциальных ключей.
– 4NF устраняет многозначные зависимости, то есть ситуацию M:N. Для её реализации вводится дополнительная таблица-связка, чтобы связь «многие ко многим» стала двумя «один ко многим».
– 5NF решает проблему зависимых сочетаний, когда при декомпозиции таблицы могут появиться ложные строки при обратном соединении (JOIN).
В большинстве обычных проектов достигается 3NF или BCNF, поскольку этого достаточно, чтобы исключить основные аномалии модификации и избыточность данных.
Что получается в итоге? На данном этапе формируются взаимосвязанные реляционные таблицы, удовлетворя хотя бы первым трём нормальным формам. Конечная схема обеспечивает удобство и целостность при вводе, обновлении и удалении данных. При этом внутри базы появляются внешние ключи, «справочные» таблицы для хранения отдельных категорий, а связи M:N заменяются промежуточными. Полученная логическая модель готова к реализации в конкретной СУБД.
Физическое представление данных
Когда реляционная схема таблиц утверждена, приходит черёд детального решения: как хранить данные на диске или другом постоянном носителе. В 1960-е годы преобладали файлы с последовательным доступом на магнитной ленте, и реализация БД была крайне примитивной. В современных СУБД обычно применяется двухуровневая структура хранения: часть данных находится в оперативной памяти (кеш/буфер), а основная копия размещается во внешней памяти (жесткий диск, SSD).
Двухуровневая модель
В типичной реляционной системе хранится один или несколько файлов БД, внутри которых размещаются блоки, а блоки состоят из записей. Записи, в свою очередь, включают поля, соответствующие столбцам таблицы. Примерная схема выглядит следующим образом:
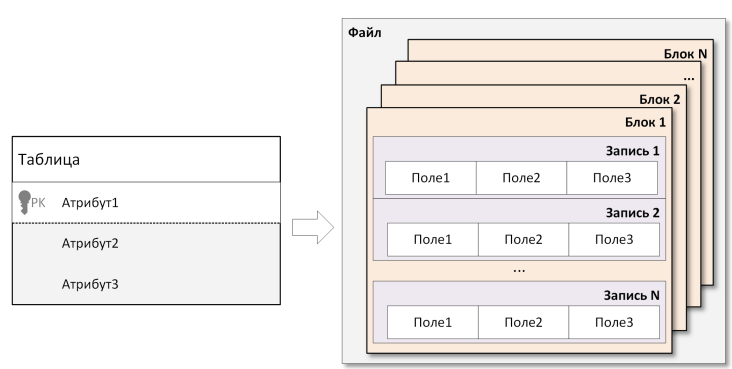
- Поле (Field). Является низкоуровневым элементом, соответствующим конкретному атрибуту (столбцу) в логической таблице. Может иметь фиксированный размер (числа, даты) или переменный (строки
VARCHAR). - Запись (Record). Объединение полей, обычно отражает одну строку таблицы (кортеж). Может быть фиксированной или переменной длины, если в ней есть хотя бы одно поле переменной длины. Зачастую запись сопровождается служебным заголовком с информацией о размере, времени модификации и т. д.
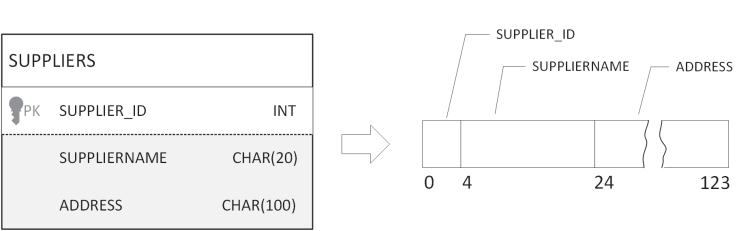
- Блок (Block/Page). Содержит одну или несколько записей, а также служебный заголовок, где указываются идентификатор блока, таблица смещений для записей, сведения о блокировках. Размер блока может быть, к примеру, 4 КБ. При недостаточном месте для новой записи выполняется «расщепление» или запись отправляется в блок переполнения.
- Файл (File). Набор блоков, представляющий физическую основу хранения. В реальных СУБД часто используется один или несколько крупных файлов, внутри которых СУБД сама распределяет таблицы, индексы и служебные объекты.
Модификация записей
Вставка новой строки приводит к созданию записи в одном из блоков, удаление — высвобождает пространство, которое помечается специальным признаком (tombstone), а обновление — заменяет содержимое полей, иногда с перемещением записи в другой блок при изменении длины. Подобная внутренняя механика скрыта от пользователя, который воспринимает таблицу логически.
Журнал транзакций
Одним из важнейших компонентов физического уровня выступает журнал (лог) транзакций. При каждом изменении СУБД записывает в него информацию о том, какие данные менялись, под каким идентификатором транзакции, в каком блоке или файле. Это даёт возможность откатывать изменения при сбоях, а также восстанавливать базу до согласованного состояния. Вследствие этого журнал транзакций рекомендуется включать в резервное копирование вместе с основными файлами БД.
Резюме
Разработка базы данных идёт поэтапно:
- Концептуальное проектирование: создаётся ER-модель, описывающая сущности, их атрибуты и связи. Этот уровень даёт полное представление о предметной области, не затрагивая технические детали.
- Логическое проектирование: ER-модель переводится в реляционные отношения (таблицы). Применяется нормализация (1NF, 2NF, 3NF и при необходимости более высокие формы), устраняются аномалии модификаций и избыточность, прорабатываются внешние ключи и структура столбцов.
- Физическое представление: определяется, как именно таблицы, индексы, журналы транзакций и другие объекты будут храниться на диске. Рассматриваются блоки, файлы, механизмы вставки, удаления, обновления, слияния и расщепления блоков, а также работа с журналом транзакций.
Такой подход обеспечивает системную и надёжную базу данных, точно отражающую реальные процессы предприятия и при этом оптимизированную для практической работы в конкретной СУБД.
Кейс: «Небольшая библиотека»
Ситуация:
В учреждении (например, в учебном заведении) открывается библиотека с ограниченным каталогом книг. Требуется вести базу данных, чтобы учитывать:
- Сами книги (название, автор, ISBN и т. д.).
- Читателей, имеющих право брать книги (фамилия, имя, контакты).
- Факт выдачи книги: кто и когда взял, когда нужно вернуть, когда вернул.
Задача — спроектировать БД, не усложняя её дополнительными справочниками, но при этом правильно учесть основные принципы:
- Отдельные сущности для книг и читателей (а не всё в одной таблице).
- Хранение фактов выдачи/возврата в отдельной структуре, чтобы понимать текущее состояние книги (на руках у читателя или в наличии).
- Исключение дублирующихся полей (автор/название/фамилия) и обеспечение целостности.
1. Концептуальная (ER) модель
В самом простом варианте можно выделить такие сущности:
-
Book (Книга)
Содержит основные характеристики: название, автор, год издания, ISBN (при наличии) и, возможно, издательство. -
Reader (Читатель)
Описывает людей, имеющих право получать книги на руки: Фамилия, Имя, Отчество (опционально), контактный телефон, адрес или другой идентификатор (например, номер читательского билета). -
Loan (Выдача)
Отражает конкретный акт выдачи книги читателю. Хранит дату выдачи, дату возврата (может быть NULL, если книга ещё на руках), а также ссылки на какую книгу выдали и какому читателю.
С точки зрения ER-диаграммы:
- «Book» и «Reader» — две сильные сущности.
- «Loan» выступает как отдельная сущность, указывающая связь между «Book» и «Reader». Фактически это связь многие ко многим, превращённая в сущность: одна книга может иметь много записей о выдаче (в разное время разным людям), а один читатель может брать много книг.
При желании можно усложнить сценарий, добавив сущность «Автор», если предполагаются книги с несколькими авторами (возникнет связь M:N между «Book» и «Author»). Однако для знакомства достаточно считать, что поле «Автор» хранится внутри «Book» как текстовая строка.
2. Логическая модель (реляционная структура)
Вводим первичные ключи (ID) и внешние ключи:
-
Таблица
BookBook_ID(PK, автоинкремент или GUID)Title(Название)Author(Автор книги)Year(Год издания)ISBN(Уникальный международный код, опционально)
-
Таблица
ReaderReader_ID(PK)LastName(Фамилия)FirstName(Имя)PhoneAddress(или другой идентификатор, например номер билета)
-
Таблица
LoanLoan_ID(PK)Book_ID(FK →Book.Book_ID)Reader_ID(FK →Reader.Reader_ID)DateBorrowed(дата выдачи)DateReturned(дата возврата, NULL, если не вернули)
Минимальная нормализация
- 1NF: Каждое поле — атомарное значение: название книги, фамилия читателя и пр. Запрещается хранить несколько авторов в одной ячейке через запятую (в нашем упрощении допустимо считать «Автор» одним текстовым полем).
- 2NF: Отсутствуют частичные зависимости, поскольку ключи (
Book_ID,Reader_IDиLoan_ID) состоят из одного столбца. - 3NF: Нет транзитивных зависимостей: «Автор» напрямую привязан к книге, а не к чему-то ещё.
Пример аномалий
Если попытаться в одной «общей» структуре записать название книги, фамилию читателя, дату выдачи, дату возврата и т. д., то возникнут аномалии:
- Аномалия вставки: при добавлении новой книги придётся указывать читателя (который может быть неизвестен), либо же пустые поля создадут путаницу.
- Аномалия удаления: при удалении одной записи (например, если ошибочно внесли неверную дату выдачи) можно потерять данные о книге или о читателе.
- Аномалия обновления: если потребуется переименовать книгу, в которой автор опечатан, придётся исправлять это во всех строках (где она фигурирует вместе с разными датами выдачи).
Разделение на три таблицы решает эти проблемы: каждая книга описывается один раз, каждый читатель — один раз, а выдачи отражаются только через связи.
3. Физическая реализация
На физическом уровне (например, в любой SQL-СУБД) создаются три таблицы с полями, как описано выше. Индексы ставятся по первичным ключам и, возможно, по столбцу ISBN (если требуется быстрый поиск книг). При выдаче книги в программу вносится новая строка в Loan со ссылками на Book_ID и Reader_ID, фиксируется текущая дата. При возврате просто заполняется DateReturned.
Задание
Ниже приводятся пять возможных вариантов небольших учебных проектов по созданию базы данных. Конкретный вариант выбираете, исходя из формулы: Вариант = (номер зачётки % 5) + 1
Общие требования к заданию для всех вариантов:
- Сначала необходимо выполнить концептуальное проектирование (ER-модель), определить сущности, их атрибуты и связи.
- После этого — логическое проектирование (реляционные таблицы, ключи, внешние ключи и т. д.).
- Реализовать базу данных в Microsoft Access.
Для получения представления о работе в MS Access и стандартных приёмах создания форм и отчётов предлагается курс у А. Ермоленко: https://aermolenko.ru/2012/02/bazy-danny-h/.
- Создать не менее двух оформленных форм (например, для ввода/поиска данных) и как минимум один отчёт (для вывода результатов).
Прим. При желании можно согласовать собственную тематику, если имеется интерес к другой предметной области.
Вариант 1: «Учёт посетителей фитнес-клуба»
Небольшой фитнес-клуб выдаёт абонементы клиентам. Необходимо учитывать данные:
- Клиенты (ФИО, дата рождения, контактный телефон, вид абонемента).
- Тренеры (ФИО, специализация, стаж).
- Посещения (кто, в какой день и время пришёл, в какой зал пошёл).
- Возможность формирования отчёта по активным клиентам и их плану тренировок.
Задачи:
- Выделить сущности «Клиент», «Тренер», «Абонемент» (или атрибут типа абонемента), «Посещение», прописать основные атрибуты.
- Продумать, как фиксируется факт визита и кто из тренеров занимается с клиентом (если такая опция нужна).
- Создать формы для ввода/редактирования клиентов и регистрации посещений.
- Подготовить отчёт, например, о текущих активных абонементах или статистику по посещениям за месяц.
Вариант 2: «Учёт студентов и дисциплин»
В учебном заведении необходимо учитывать информацию о студентах, изучаемых ими предметах и оценках за сессии. База данных помогает формировать итоговую ведомость.
Задачи:
- Определить сущности «Студент» (ФИО, группа, дата рождения), «Дисциплина» (название, кафедра), «Успеваемость» (студент, дисциплина, оценка, семестр).
- Организовать связи: один студент может сдавать много дисциплин, а одна дисциплина — многим студентам (M:N, решается промежуточной сущностью «Успеваемость»).
- Создать формы для ввода/редактирования студентов и добавления оценок.
- Сформировать отчёт, например, сводную ведомость оценок по группе или по конкретной дисциплине.
Вариант 3: «Учёт заявок на ремонт компьютеров»
Сервис по ремонту компьютеров принимает заявки от клиентов (ФИО, контактные данные). Каждый клиент может обращаться многократно с разными устройствами (ноутбук, стационарный ПК, планшет). Для каждой заявки фиксируется дата, тип проблемы (аппаратная, программная), предварительная стоимость. После ремонта указывается окончательная стоимость и дата завершения.
Задачи:
- Определить сущности: «Клиент» (ФИО, телефон), «Устройство» (тип, модель), «Заявка» (дата начала, дата завершения, статус, стоимость). Связь «Клиент–Устройство» может быть 1:N, а сами заявки могут содержать ссылку и на клиента, и на устройство.
- Создать формы для регистрации новых заявок, закрытия (завершения) заявок, поиска по клиентам.
- Сделать отчёт, например, о текущих незавершённых ремонтах или сводку суммарных затрат по клиентам за месяц.
Вариант 4: «Мини-магазин электроники»
Небольшой магазин торгует электроникой. Необходимо хранить информацию о товарах, поставщиках и продажах.
Задачи:
- Выделить сущности «Товар» (название, категория, цена), «Поставщик» (название компании, контактные данные) и «Продажа» (номер продажи, дата, клиент, список купленных товаров).
- Подумать, как оформляются покупки: одна продажа может включать несколько позиций. Это может потребовать дополнительную таблицу «Продажа_Товар» (M:N).
- Создать формы для добавления новых товаров и регистрации продаж.
- Реализовать отчёт о сумме продаж за период или о количестве проданных устройств конкретного типа.
Вариант 5: «Небольшой автопарк»
Есть автопарк, где учитывают наличие машин, водителей и их командировки (или рейсы).
Задачи:
- Определить сущности «Автомобиль» (марка, модель, госномер, год выпуска), «Водитель» (ФИО, стаж, категория прав), «Рейс» (дата выезда, дата возврата, водитель, автомобиль).
- Продумать связи: один автомобиль может совершить множество рейсов (но в каждый момент времени — не более одного рейса), водитель также может участвовать в разных рейсах.
- Создать формы для ввода новых автомобилей и регистрации рейсов.
- Сформировать отчёт: например, список всех поездок за месяц по конкретному автомобилю или водителю.
Знакомство с SQL
Концепция SQL
SQL появился в середине 70‑х годов XX века сразу после возникновения реляционной модели данных. Разработчики стремились создать язык, который позволял бы создавать базы данных, таблицы и другие объекты, а также выполнять основные операции с данными (вставку, изменение, удаление) и формировать запросы, преобразующие хранящиеся данные в нужный формат. Одной из ключевых особенностей стало использование трёхзначной логики, когда помимо истинного и ложного значений учитывается значение «UNKNOWN» (True, False, UNKNOWN), что отражает неопределённость данных. Кроме того, язык был разработан как декларативный, чтобы пользователь мог описывать требуемый результат, не заботясь о деталях реализации.
SQL был впервые стандартизирован благодаря совместным усилиям ANSI и ISO в 1976г.:
- В 1986 году SQL был стандартизирован ANSI и ISO (часто именуется ANSI SQL).
- SQL:92 (принят в 1992 году) стал общепризнанным стандартом, и большинство СУБД стремятся его поддерживать.
- SQL:99 (SQL-3) в 1999 году расширил возможности языка (например, введены пользовательские типы данных и типизированные таблицы).
Замечание: Некоторые специалисты критиковали SQL-3 за незавершённость. - SQL:2003 модернизировал стандарт, включив все части SQL:99 (с некоторыми изменениями) и добавив поддержку взаимодействия с Java и XML.
- С тех пор новые версии стандарта появляются примерно каждые 3–5 лет. На момент написания последним считается SQL:2023.
Возможности SQL
SQL предоставляет мощный набор возможностей для работы с данными, который можно разделить на несколько крупных блоков. Каждый из них отвечает за свою область функциональности, позволяя не только задавать структуру базы данных, но и гибко работать с её содержимым, обеспечивать безопасность и целостность данных, а также проводить детальную обработку информации.
DDL (Data Definition Language) – подъязык определения данных, предназначенный для создания, изменения и удаления объектов базы данных. С помощью команды CREATE можно создавать базы данных и их объекты, такие как таблицы, представления, индексы, курсоры и определения доменов, что задаёт «скелет» базы данных. Например:
CREATE TABLE Employees (
ID INT PRIMARY KEY,
Name VARCHAR(100)
);
Команда ALTER позволяет изменять уже созданные объекты (например, добавлять новые столбцы или изменять их типы), а DROP – удалять объекты из базы.
Прим.: Изменения, внесённые через DDL, обычно фиксируются автоматически, отражая изменения в архитектуре базы данных.
DML (Data Manipulation Language) – подъязык манипулирования данными, который отвечает за их добавление, изменение, удаление и извлечение. Здесь применяются такие команды, как INSERT для добавления новых записей, UPDATE для изменения существующих данных и DELETE для их удаления. Наиболее часто используемой является команда SELECT, которая извлекает данные из одной или нескольких таблиц и позволяет объединять, фильтровать, сортировать и группировать информацию. Пример вставки записи:
INSERT INTO Employees (ID, Name) VALUES (1, 'Ivan Ivanov');
и выборки данных:
SELECT * FROM Employees;
Эта комбинация операций обеспечивает динамичное взаимодействие с содержимым базы данных.
Для обеспечения безопасности и контроля доступа к данным используются команды GRANT и REVOKE. Администратор с помощью GRANT предоставляет пользователям или группам права на выполнение определённых операций (чтение, запись, изменение данных), а REVOKE позволяет отозвать ранее предоставленные права.
Гибкость этих команд позволяет создавать тонкие уровни доступа, что особенно важно в корпоративных системах с большим числом пользователей.
Когда требуется обработка результата запроса по одной строке за раз, применяется механизм управления курсором. Курсор – это специальный объект, позволяющий осуществлять итеративную обработку данных, то есть построчно получать и обрабатывать результаты запроса. Сначала курсор объявляется с помощью команды DECLARE CURSOR, затем открывается командой OPEN CURSOR, строки извлекаются по одной через FETCH CURSOR, и, наконец, курсор закрывается с помощью CLOSE CURSOR. Пример использования курсора:
DECLARE myCursor CURSOR FOR SELECT Name FROM Employees;
OPEN myCursor;
FETCH myCursor INTO @EmployeeName;
-- Обработка строки (например, вывод или дополнительные вычисления)
CLOSE myCursor;
Прим.: Курсоры полезны в тех случаях, когда необходимо выполнять сложную логику для каждой строки, однако их использование может замедлять обработку больших объёмов данных.
Наконец, управление транзакциями обеспечивает целостность данных при выполнении группы взаимосвязанных операций. Транзакция представляет собой логическую единицу, объединяющую несколько SQL-команд. При успешном выполнении всех операций транзакция фиксируется командой COMMIT; в случае возникновения ошибки все изменения отменяются командой ROLLBACK. Команда BEGIN TRANSACTION инициирует транзакцию, а SET TRANSACTION позволяет задать параметры, например, уровень изоляции, влияющий на видимость изменений другими пользователями. Пример транзакции:
BEGIN TRANSACTION;
UPDATE Employees SET Name = 'Ivan Petrov' WHERE ID = 1;
-- Дополнительные операции...
COMMIT;
Если возникает ошибка, можно выполнить:
ROLLBACK;
** Транзакции гарантируют, что данные остаются в консистентном состоянии даже при сбоях, что критично для финансовых и других критически важных приложений.
SQL предоставляет мощный инструментарий для управления базой данных. DDL задаёт структуру, DML обеспечивает работу с данными, а механизмы контроля доступа, курсоры и транзакции помогают организовать безопасную, гибкую и надёжную обработку информации. Эти компоненты работают совместно, создавая фундамент для современных реляционных баз данных.
Типы данных в SQL
SQL предлагает богатый набор типов данных, который позволяет представлять и обрабатывать самые разные виды информации. Эти типы делятся на две большие группы: стандартные (предопределённые) типы, поддерживаемые, как минимум, стандартом SQL:92, и расширенные (непредопределённые) типы, введённые в более поздних версиях стандарта (SQL:1999 и SQL:2003).
Стандартные типы
Точные числовые типы
Эти типы предназначены для хранения целых чисел и чисел с дробной частью без потерь точности. При их использовании необходимо указывать два параметра: точность (n) и масштаб (m). Точность определяет общее количество значащих цифр, а масштаб – число цифр после десятичной точки. Например, тип NUMERIC(5,2) позволяет хранить число, содержащее до пяти цифр, из которых две располагаются после запятой:
-- Пример использования точного числового типа
CREATE TABLE Sales (
SaleID INT PRIMARY KEY,
Amount NUMERIC(5,2)
);
Прим.: При указании параметров обязательно должно выполняться условие: n > m. Если масштаб не указан, он считается равным 0.
Ниже приведена таблица, суммирующая основные точные числовые типы:
| Тип данных | Описание |
|---|---|
| NUMERIC(n, m) | Точное число с заданной точностью и масштабом |
| DECIMAL(n, m) | Похож на NUMERIC, но гарантирует минимальную точность, заданную m |
| BIGINT | Для хранения больших целых чисел (обычно 64 бита) |
| INTEGER (INT) | Для хранения целых чисел (обычно 32 бита) |
| SMALLINT | Для хранения малых целых чисел (обычно 16 бит) |
Приближенные числовые типы
Приближенные числовые типы используются для представления чисел с плавающей точкой в научном формате (мантисса плюс порядок). Они полезны для хранения чисел, не требующих высокой точности, например, для статистических или научных расчётов.
Примеры:
- REAL – обычно занимает 6 байт и может хранить числа в диапазоне от –3,4E–38 до +3,4E+38 с точностью до 7 знаков.
- FLOAT(n) – если n не указан, требует 8 байт памяти; позволяет хранить числа с точностью до 15 знаков.
- DOUBLE PRECISION – имеет ещё большую точность, чем REAL, и зависит от реализации СУБД.
-- Пример объявления столбца с приближённым числовым типом
CREATE TABLE Measurements (
MeasurementID INT PRIMARY KEY,
Value FLOAT
);
Дата и время
Типы данных для работы с датой и временем позволяют хранить значения в формате, принятом в большинстве стран мира (григорианский календарь).
- DATE – хранит дату в формате
yyyy-mm-dd(например,2020-02-01). - TIME[(n)] – хранит время в формате
hh:mm:ss; аргумент n позволяет задать точность для долей секунд. - TIMESTAMP[(n)] – объединяет DATE и TIME, создавая метку даты-времени.
- TIME WITH TIME ZONE и TIMESTAMP WITH TIME ZONE – учитывают смещение от Гринвича.
-- Пример создания таблицы с типами даты и времени
CREATE TABLE Events (
EventID INT PRIMARY KEY,
EventDate DATE,
EventTime TIME,
EventTimestamp TIMESTAMP
);
Интервалы
Интервалы представляют собой тип данных, позволяющий описывать разницу между двумя временными отсчетами. Они делятся на:
- Интервалы год-месяц (year-month interval) – используются для представления длительных периодов (например, интервал в 5 лет и 1 месяц).
- Интервалы день-время (day-time interval) – позволяют хранить разницу в днях, часах, минутах и секундах с точностью до долей секунды.
Пример:
-- Пример задания интервала в 12 часов 54 минуты
SELECT INTERVAL '12:54' HOUR TO MINUTE;
Интервалы можно складывать, вычитать, а также умножать или делить на вещественные числа, что позволяет гибко выполнять вычисления с временными данными.
Логический тип
Логический тип данных (BOOLEAN) реализует трёхзначную логику: помимо стандартных значений TRUE и FALSE, используется значение UNKNOWN для обозначения неопределенности. Это особенно важно при обработке значений, где может возникнуть неопределённость (например, при сравнении с NULL).
-- Пример использования логического типа в условии
SELECT * FROM Orders WHERE IsProcessed = TRUE;
Строковые типы
Строковые типы данных используются для хранения текстовой информации. Они делятся на:
- Фиксированной длины (CHAR или CHARACTER [n]) – если строка короче указанной длины, оставшиеся позиции заполняются пробелами.
- Переменной длины (VARCHAR или CHARACTER VARYING [n]) – позволяет экономить память, так как неиспользуемые позиции не выделяются.
- Национальные варианты (NCHAR, NVARCHAR) – предназначены для хранения символов национальных наборов.
- Большие объекты (CLOB) – используются для хранения больших текстовых данных.
-- Пример создания таблицы со строковыми типами
CREATE TABLE Users (
UserID INT PRIMARY KEY,
UserName VARCHAR(50),
UserDescription CLOB
);
Прим.: При работе со строками необходимо указывать длину (n), что помогает управлять памятью и обеспечивает предсказуемость размера данных.
Битовые строки
Битовые типы предназначены для хранения двоичной информации. Они позволяют описывать как простейшие логические данные (например, поля типа BIT для хранения значения "Да/Нет"), так и сложные объекты, такие как файлы мультимедиа.
- BIT [n] – фиксированная битовая последовательность.
- BIT VARYING [n] – последовательность переменной длины.
- BLOB (Binary Large Object) – для хранения больших двоичных объектов, таких как изображения или аудиофайлы.
-- Пример использования BLOB для хранения изображений
CREATE TABLE Pictures (
PictureID INT PRIMARY KEY,
ImageData BLOB
);
Расширенные (непредопределенные) типы
Современные стандарты SQL расширяют набор типов данных, позволяя работать с более сложными структурами, которые традиционно не укладывались в рамки атомарности.
Коллекции и массивы
Стандарт SQL позволяет объявлять одномерные массивы, где индекс начинается с 1 (в отличие от большинства языков программирования).
Пример:
-- Пример одномерного массива целых чисел
DECLARE numbers INT ARRAY[10];
Массивы в SQL используются реже, но могут быть полезны для хранения упорядоченных наборов данных в одной колонке.
Множество и мультимножество
- Множество (SET) – не допускает повторяющихся значений.
- Мультимножество (MULTISET) – допускает дублирование значений.
Эти типы полезны для хранения наборов значений, где важна уникальность или, наоборот, повторение элементов.
Последовательности (ROW types)
Последовательности создаются с помощью конструктора типа ROW, который позволяет объединять несколько полей в одну структурированную запись. Например, чтобы хранить ФИО в одном столбце, можно определить структуру, которая разделяет фамилию, имя и отчество:
-- Пример создания таблицы с использованием ROW
CREATE TABLE Demotable (
Demotable_Key INTEGER PRIMARY KEY,
FIO ROW (SName VARCHAR(20),
FName VARCHAR(15),
LName VARCHAR(15)),
BDay DATE
);
Пользовательские типы (UDT)
Пользовательские типы позволяют создавать собственные типы данных на базе уже существующих. Это полезно, когда стандартные типы не охватывают все требования базы данных. Пример простого пользовательского типа:
-- Пример создания пользовательского типа для коротких строк
CREATE TYPE SHORT_STRING_TYPE AS CHAR(10);
Также возможна иерархия типов. Например, можно создать родительский тип для адреса, а затем на его основе – дочерний тип, добавляющий номер телефона:
-- Пример создания родительского типа ADDRESS_TYPE
CREATE TYPE ADDRESS_TYPE AS (
ZIPCODE CHAR(6),
CITYNAME VARCHAR(20) NOT NULL,
STREET VARCHAR(20) NOT NULL,
HOME VARCHAR(3) NOT NULL
)
NOT FINALL;
-- Пример создания дочернего типа ADDRESSEX_TYPE
CREATE TYPE ADDRESSEX_TYPE
UNDER ADDRESS_TYPE
AS (PHONENUM CHAR(11))
FINALL;
Ссылочные типы, XML и JSON
- Ссылочные типы (REF) – позволяют создавать переменные, которые ссылаются на строки в типизированных таблицах.
- XML – предназначен для хранения и обработки структурированных данных с помощью расширяемой разметки.
- JSON – текстовый формат обмена данными, основанный на JavaScript, удобный для взаимодействия с веб-приложениями.
Прим.: Многие СУБД поддерживают дополнительные типы, не входящие в стандарт, что позволяет решать специфичные задачи, например, хранение геометрических данных (как в PostgreSQL: BOX, CIRCLE, LINE и т.д.).
Преобразование данных
В SQL поддерживаются два вида преобразования типов данных:
Неявное преобразование
Автоматическое преобразование происходит без вмешательства разработчика. Например, в MySQL можно выполнить операцию, где строковый литерал автоматически преобразуется в число:
-- Пример неявного преобразования: строка '2' преобразуется в число 2
SELECT 2 + '2'; -- Результат: 4
Однако неявное преобразование может привести к неожиданным результатам, если типы данных не совместимы:
-- Пример, демонстрирующий недостаток неявного преобразования
SELECT 'Hello' + 2; -- Результат: 2 (ожидалось бы возникновение ошибки)
Прим.: Неявное преобразование следует применять только в тех случаях, когда вы уверены в типах исходных данных.
Явное преобразование
Явное преобразование выполняется с помощью функции CAST, которая позволяет точно указать целевой тип данных. Например:
-- Пример явного преобразования: преобразование даты в строку
SELECT CAST(DNDATE AS CHAR(24)) AS DNDATE_TXT
FROM DELIVERYNOTE;
Операторы в SQL
SQL содержит стандартный набор операторов для различных операций:
6.1. Арифметические операторы
-
Присваивание:
Обычно используется знак=(иногда:=), например:SELECT @X := COUNT(*) FROM SUPPLIERS; -
Арифметические операторы:
- Стандартные:
+,-,*,/ - Дополнительные:
DIV– целочисленное деление (например,7 DIV 2даёт 3)%(илиMOD) – остаток от деления (например,7 % 2даёт 1)
- Стандартные:
-
Особенности:
Арифметические операции могут применяться к числам, а также – с датами, временем и интервалами (см. таблицу ниже).
| Операнд 1 | Оператор | Операнд 2 | Результат |
|---|---|---|---|
| Datetime | - | Datetime | Interval |
| Datetime | + или - | Interval | Datetime |
| Interval | + | Datetime | Datetime |
| Interval | + или - | Interval | Interval |
| Interval | * или / | Numeric | Interval |
| Numeric | * | Interval | Interval |
6.2. Логические операторы
- Основные:
AND,OR,NOT - Дополнительно во многих диалектах поддерживается
XOR.
Таблицы 11.3 и 11.9 иллюстрируют работу логических операторов с учетом значенияNULL(неопределённости).
6.3. Операторы сравнения
- Сравнения:
<,>,<=,>=,=,<>(или!=) - Специфические для NULL:
<=>, а также конструкцииIS NULLиIS NOT NULL
Пример проверки на неопределённость:
SELECT NULL IS NULL, 1 IS NULL; -- Результат: 1 0
SELECT ISNULL(NULL), ISNULL(1); -- Результат: 1 0
6.4. Конкатенация строк
- Стандартно: используется оператор
+ - В некоторых диалектах (InterBase, FireBird): применяется оператор
||
6.5. Встроенные функции
Набор встроенных функций SQL включает:
| Функция | Описание |
|---|---|
| BIT_LENGTH(битовая строка) | Возвращает длину строки в битах |
| CHAR_LENGTH(символьная строка) | Определяет количество символов в строке |
| CURRENT_DATE | Текущая дата |
| CURRENT_TIME | Текущее время с заданной точностью |
| CURRENT_TIMESTAMP | Текущая дата и время |
| LOWER / UPPER | Преобразуют строку к нижнему/верхнему регистру |
| POSITION | Определяет позицию подстроки в строке |
| SUBSTRING | Извлекает часть строки |
| TRIM | Удаляет ведущие, завершающие или обе группы символов |
| TRANSLATE | Преобразует строку с использованием заданной функции |
Манипулирование данными SQL
Ниже приведён конспект по использованию инструкции SELECT, предложения WHERE, псевдонимов (alias) и агрегирующих функций с пояснениями и примерами. Этот материал поможет понять базовую синтаксическую конструкцию запросов SQL, а также как фильтровать, переименовывать и агрегировать данные.
Инструкция SELECT
Инструкция SELECT – ключевой элемент SQL, предназначенный для выборки данных из таблиц или представлений. Результатом запроса всегда является отношение (набор строк), которое можно выводить на экран или использовать в последующих операциях (например, для создания представлений или хранимых процедур).
Базовая структура запроса:
SELECT [DISTINCT|ALL]
{ имя_столбца [AS псевдоним] | функция_агрегирования [AS псевдоним] | выражение [AS псевдоним] | * }
FROM имя_таблицы [AS псевдоним]
[WHERE условие]
[GROUP BY имя_столбца [,...]]
[HAVING условие]
[ORDER BY имя_столбца [ASC|DESC] [,...]];
Прим.: По умолчанию используется режим ALL (все строки, включая дубликаты). Использование DISTINCT исключает повторения.
Примеры:
-
Выбор всех данных из таблицы поставщиков:
SELECT * FROM suppliers; -
Выбор конкретного столбца:
SELECT supplier FROM suppliers; -
Выбор нескольких столбцов:
SELECT dnnum, dndate FROM deliverynotes;
Условие (WHERE)
Предложение WHERE используется для ограничения набора строк, возвращаемых запросом, на основании заданного условия. Оно позволяет фильтровать данные по значениям, сравнениям, диапазонам, шаблонам и другим критериям.
Основные виды условий:
-
Сравнение:
Пример – выбор записей с датой позже 1 января 2017 года:SELECT * FROM deliverynotes WHERE dndate >= '2017-01-01'; -
Комбинированные условия:
С использованием логических операторов AND и OR:SELECT * FROM goodslist WHERE SizeX <= 1000 AND SizeY <= 1000 AND SizeZ <= 1000; -
Диапазон (BETWEEN):
Пример – выбор записей с датой между 1 января и 31 декабря 2018 года:SELECT * FROM deliverynotes WHERE dndate BETWEEN '2018-01-01' AND '2018-12-31'; -
Соответствие шаблону (LIKE):
Пример – выбор поставщиков, в имени которых присутствует символ «о»:SELECT * FROM suppliers WHERE supplier LIKE '%о%';
Прим.: Для сложных условий, где используются комбинации операторов AND и OR, рекомендуется применять круглые скобки для группировки условий.
Псевдонимы (Alias)
Псевдонимы используются для упрощения запросов, когда имена столбцов или таблиц слишком длинные или когда результат вычислений требует понятного названия. Для этого применяется ключевое слово AS, которое позволяет задать альтернативное имя.
Примеры использования:
-
Присвоение псевдонима столбцу, результат которого является выражением:
SELECT CONCAT('№ ', dnnum, ' от ', dndate) AS dinfo FROM deliverynotes; -
Присвоение псевдонима таблице для сокращения кода:
SELECT g.goods, t.amount FROM goodslist g, transfers t WHERE t.goodslist_id = g.goodslist_id;
Использование псевдонимов не только сокращает записи, но и повышает читаемость сложных запросов, особенно когда задействованы агрегатные функции или вычисляемые поля.
Агрегирующие функции
Агрегирующие функции применяются для вычисления единого значения по набору строк. Обычно они используются вместе с предложением GROUP BY, которое группирует строки по определённому признаку. Основные агрегатные функции:
| Функция | Описание | Пример использования |
|---|---|---|
| COUNT | Возвращает количество строк. | SELECT COUNT(*) FROM suppliers; |
| AVG | Вычисляет среднее арифметическое для числовых значений. | SELECT AVG(price) FROM products; |
| SUM | Вычисляет сумму значений. | SELECT SUM(amount) FROM goodslist; |
| MAX | Возвращает максимальное значение. | SELECT MAX(dndate) FROM deliverynotes; |
| MIN | Возвращает минимальное значение. | SELECT MIN(dndate) FROM deliverynotes; |
Примеры:
-
Подсчёт количества записей в таблице поставщиков:
SELECT COUNT(*) AS total_suppliers FROM suppliers; -
Вычисление средней цены товара:
SELECT AVG(price) AS average_price FROM products; -
Группировка данных и применение SUM для подсчёта общего количества единиц товара по наименованию:
SELECT goods, SUM(amount) AS total_amount FROM goodslist WHERE deliverynote_id = 100 GROUP BY goods; -
Применение предиката HAVING для фильтрации групп с суммарной стоимостью более 1000:
SELECT goods, SUM(amount * factoryprice) AS total_price FROM goodslist GROUP BY goods HAVING SUM(amount * factoryprice) > 1000;
Прим.: Если в запросе GROUP BY используются агрегирующие функции, все столбцы, не являющиеся результатом агрегирования, должны присутствовать в списке группировки. Квантификатор DISTINCT может быть применён внутри агрегатных функций для исключения дубликатов.
Ознакомиться и выполнить упражнения из разделов:
- Простой оператор SELECT. Упражнения - 1, 2, 3, 4, 5, 6, 9, 14, 31, 33, 42.
- Переименование столбцов и вычисления в результирующем наборе. Упражнения - 32.
- Получение итоговых значений. Упражнения - 10, 11, 12, 13, 18, 24, 25, 26, 27, 40, 41, 43, 51, 53, 54, 58, 61, 62, 75, 77, 79, 80, 81, 85, 86, 88, 91, 92, 93, 94, 95, 96, 103, 109, 127, 129.
Создание базы данных В СУБД MS SQL Server
Установка и настройка среды
- Переходим по ссылке на официальный сайт Microsoft и скачиваем Developer Edition SQL Server 2022. После запуска .exe'шника достаточно выбрать базовый вариант установки.
- Теперь необходимо установить инструмент для управления SQL Server - SQL Server Management Studio. Его также будет необходимо установить с официального сайта Microsoft.
При первом подключении достаточно указать "Проверку подлинности Windows" (рис. ниже), но для дальнейшей работы необходимо подключить вход по логину и паролю, т.к. в процессе разработки нам необходимо будет подключиться к БД при помощи драйвера и строки подключения (строка вида: Server=myServerAddress;Database=myDataBase;User Id=myUsername;Password=myPassword;).
Прим. При использовании параметров установки по умолчанию не забываем указать в строке подключения параметр
Trusted_Connection=True;, иначе авторизация не пройдет.
После первой авторизации открываем свойства сервера БД и во вкладке "Безопасность" в пункте "Серверная проверка подлинности" устанавливаем значение на "Проверка подлинности SQL Server и Windows".
Прим. Перезагрузить MS SQL Sevrer можно при помощи SQL Server 2022 Configuration Manager. Выбираем вкладку "Службы SQL Server", ПКМ по пункту "SQL Server (MSSQLSERVER)" -> Перезагрузить.
Далее обновим данные для подключения пользователя sa (системный администратор) в Обозревателе объектов. На первой вкладке (Безопасность) устанавливаем новый пароль для учетной записи, в рамках тестовой разработки на локальном сервере можете использовать 123, чтобы потом его случайно не забыть и избержать дополнительных проблем с использованием специальных символов в более сложных паролях.
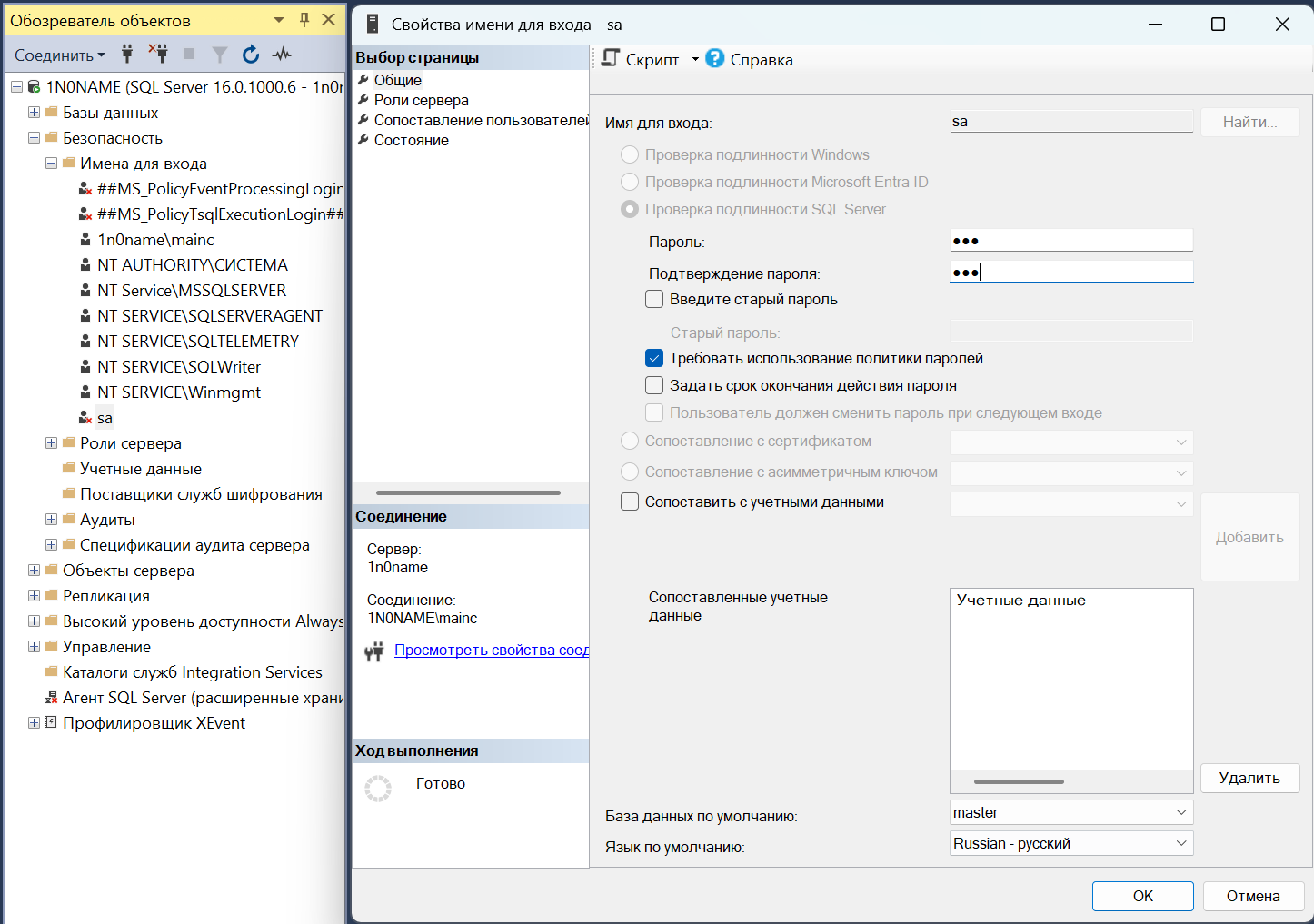
Важно! Не забудьте включить профиль во вкладке "Состояние" -> "Имя для входа" -> "Включено".
Теперь мы готовы приступать к лабораторкам.
Лабораторные работы
- Создание БД в среде СУБД MS SQL Server;
- Создание БД при помощи T-SQL;
- Выборка и манипулирование данными при помощи языка SQL;
Закрепление навыков манипуляции данными
Для закрепления навыков полуенных в рамках прошлых работ рекомендуется повторно прочитать справку и выполнить соотвествующие упражнения на сайте sql-ex.
Работа с запросами
Тема текущих лабораторных - работа с запросами и подзапросами с базой данных, созданной на прошлых лабораторных работах.
Задание: Подзапросы, case-выражения, табличные выражения
Виды соединений (JOIN'ов)
Почти любой аналитический запрос включает в себя объединение данных из нескольких различных сущностей, что вызывает логичный вопрос «каким связать эти таблицы между собой». В SQL для этого предназначены соединения (JOIN) решают эту задачу. Всего их есть несколько видов и у каждый тип обладает своей собственной логикой:
| Тип JOIN | Что возвращает | Когда использовать |
|---|---|---|
INNER JOIN | Только строки, для которых условие соединения выполняется в обеих таблицах. | «Пересечение» данных: показать только совпадающие сущности. |
LEFT (OUTER) JOIN | Все строки из левой таблицы + совпадения из правой. Отсутствующие значения заполняются NULL. | «Обогащение» главной (левой) таблицы дополнительной информацией, не теряя ни одной записи. |
RIGHT (OUTER) JOIN | Симметрично LEFT: всё из правой + совпадения из левой. | Редко нужен, но полезен, если «главной» является правая таблица. |
FULL (OUTER) JOIN | Объединяет результаты LEFT и RIGHT: все строки обеих таблиц. | Сводные отчёты, когда важно увидеть и «висящие» записи в обеих таблицах. |
CROSS JOIN | Декартово произведение: каждая строка левой таблицы сочетается с каждой строкой правой. | Генерация всех возможных комбинаций. |
SELF JOIN | Соединение таблицы с самой собой (требует псевдонимов). | Иерархии (сотрудник-начальник), поиск «пар» внутри одного набора данных. |
Прим. в некоторых СУБД есть ещё
NATURAL JOINиUSING (… ), но на данном этапе мы сосредоточимся на шести базовых типах.
Проследим различия между ними на примере "сказки".
«DataUni»: мини-информационная система учебного центра
Учебный центр проводит курсы; студенты обращаются к расписанию, а менеджеры следят за заполняемостью. Схема данных сводится к четырём сущностям:
Students(student_id PK, full_name, city)
Courses(course_id PK, title, ects)
Professors(professor_id PK, full_name, department)
Enrollments(enrollment_id PK, student_id FK, course_id FK)
Содержимое таблиц
Students
| id | ФИО | Город |
|---|---|---|
| 1 | Алиса Миронова | Москва |
| 2 | Борис Егоров | Казань |
| 3 | Вера Чан | Томск |
| 4 | Григорий Левин | Самара |
Courses
| id | Название | ECTS |
|---|---|---|
| 10 | SQL-аналитика | 5 |
| 11 | Python для Data Science | 6 |
| 12 | Power BI с нуля | 4 |
Professors
| id | ФИО | Кафедра |
|---|---|---|
| 100 | Дмитрий Белый | Факультет данных |
| 101 | Евгений Корнеев | Факультет данных |
Enrollments
| id | student_id | course_id |
|---|---|---|
| 1001 | 1 | 10 |
| 1002 | 1 | 11 |
| 1003 | 2 | 10 |
| 1004 | 3 | 12 |
Демонстрация JOIN-ов «на доске»
1️⃣ INNER: увидеть только существующие пары студент – курс.
SELECT s.full_name, c.title
FROM Students AS s
JOIN Enrollments AS e ON e.student_id = s.student_id
JOIN Courses AS c ON c.course_id = e.course_id;
| full_name | title |
|---|---|
| Алиса Миронова | SQL-аналитика |
| Алиса Миронова | Python для DS |
| Борис Егоров | SQL-аналитика |
| Вера Чан | Power BI с нуля |
2️⃣ LEFT: показать всех студентов плюс их курсы (у Григория курсов нет).
SELECT s.full_name,
COALESCE(c.title,'(нет курса)') AS course
FROM Students AS s
LEFT JOIN Enrollments AS e ON e.student_id = s.student_id
LEFT JOIN Courses AS c ON c.course_id = e.course_id
ORDER BY s.student_id;
| full_name | course |
|---|---|
| Алиса Миронова | SQL-аналитика |
| … | Python … |
| Борис Егоров | SQL-аналитика |
| Вера Чан | Power BI … |
| Григорий Левин | (нет курса) |
3️⃣ RIGHT: курсы без назначенных преподавателей.
INSERT INTO CourseTeachers(course_id, professor_id) VALUES (10,100);
SELECT c.title,
p.full_name AS professor
FROM CourseTeachers AS ct
RIGHT JOIN Courses AS c ON c.course_id = ct.course_id
LEFT JOIN Professors AS p ON p.professor_id = ct.professor_id;
| title | professor |
|---|---|
| SQL-аналитика | Дмитрий Белый |
| Python для DS | NULL |
| Power BI с нуля | NULL |
4️⃣ FULL: сводная картина «одиноких» студентов и курсов.
SELECT c.title, s.full_name
FROM Courses AS c
FULL JOIN Enrollments AS e ON e.course_id = c.course_id
FULL JOIN Students AS s ON s.student_id = e.student_id;
| title | full_name |
|---|---|
| SQL-аналитика | Алиса Миронова |
| SQL-аналитика | Борис Егоров |
| Python для Data Science | Алиса Миронова |
| Power BI с нуля | Вера Чан |
| NULL | Григорий Левин |
5️⃣ CROSS: маркетинг хочет список «город × курс» для e-mail-рассылки.
SELECT DISTINCT s.city, c.title
FROM Students AS s
CROSS JOIN Courses AS c
ORDER BY s.city, c.title;
| city | title |
|---|---|
| Казань | Power BI с нуля |
| Казань | Python для Data Science |
| Казань | SQL-аналитика |
| Москва | Power BI с нуля |
| Москва | Python для Data Science |
| Москва | SQL-аналитика |
| Самара | Power BI с нуля |
| Самара | Python для Data Science |
| Самара | SQL-аналитика |
| Томск | Power BI с нуля |
| Томск | Python для Data Science |
| Томск | SQL-аналитика |
6️⃣ SELF: если бы в Professors была колонка mentor_id, запрос выглядел бы так:
SELECT p.full_name AS professor,
m.full_name AS mentor
FROM Professors AS p
LEFT JOIN Professors AS m ON m.professor_id = p.mentor_id;
| professor | mentor |
|---|---|
| Дмитрий Белый | NULL |
| Евгений Корнеев | NULL |
Практическое задание
Ваша предметная область - сеть пунктов выдачи онлайн-заказов. Ниже — схема, которую нужно создать вручную (имена полей можно копировать, но значения придумайте сами).
Branches(branch_id PK, city, address)
Couriers(courier_id PK, full_name, vehicle_id FK NULLABLE)
Vehicles(vehicle_id PK, type, capacity)
Parcels(parcel_id PK, weight, branch_id FK NULLABLE, courier_id FK NULLABLE, dispatched_at DATE)
Условие перед заполнением
- хотя бы один филиал не должен иметь посылок;
- в Parcels должны быть строки без курьера и/или без филиала;
- минимум один курьер остаётся без транспорта, а минимум одна машина – без курьера.
После вставки 10-15 строк выполните (и сохраните результаты):
Пример скрипта для заполнения
/* ============================================================
1. Создаём (или пересоздаём) базу
============================================================ */
IF DB_ID(N'ParcelOffice') IS NOT NULL
DROP DATABASE ParcelOffice;
GO
CREATE DATABASE ParcelOffice;
GO
USE ParcelOffice;
GO
/* ============================================================
2. Справочники и основной журнал
============================================================ */
-- ─── Branches ───
IF OBJECT_ID(N'dbo.Branches', N'U') IS NOT NULL
DROP TABLE dbo.Branches;
GO
CREATE TABLE dbo.Branches (
branch_id INT IDENTITY(1,1) PRIMARY KEY,
city NVARCHAR(50) NOT NULL,
address NVARCHAR(100) NOT NULL
);
-- ─── Vehicles ───
IF OBJECT_ID(N'dbo.Vehicles', N'U') IS NOT NULL
DROP TABLE dbo.Vehicles;
GO
CREATE TABLE dbo.Vehicles (
vehicle_id INT IDENTITY(1,1) PRIMARY KEY,
type NVARCHAR(50) NOT NULL,
capacity DECIMAL(10,2) NOT NULL -- кг
);
-- ─── Couriers ───
IF OBJECT_ID(N'dbo.Couriers', N'U') IS NOT NULL
DROP TABLE dbo.Couriers;
GO
CREATE TABLE dbo.Couriers (
courier_id INT IDENTITY(1,1) PRIMARY KEY,
full_name NVARCHAR(100) NOT NULL,
vehicle_id INT NULL
CONSTRAINT FK_Couriers_Vehicles
REFERENCES dbo.Vehicles(vehicle_id)
);
-- ─── Parcels ───
IF OBJECT_ID(N'dbo.Parcels', N'U') IS NOT NULL
DROP TABLE dbo.Parcels;
GO
CREATE TABLE dbo.Parcels (
parcel_id INT IDENTITY(1,1) PRIMARY KEY,
weight DECIMAL(10,2) NOT NULL, -- кг
branch_id INT NULL
CONSTRAINT FK_Parcels_Branches
REFERENCES dbo.Branches(branch_id),
courier_id INT NULL
CONSTRAINT FK_Parcels_Couriers
REFERENCES dbo.Couriers(courier_id),
dispatched_at DATE NOT NULL
);
/* ============================================================
3. Демонстрационные данные (12 посылок, 4 курьера, 4 машины)
• один филиал без посылок (branch_id = 3);
• посылки без курьера и/или без филиала;
• курьер без транспорта, транспорт без курьера.
============================================================ */
SET NOCOUNT ON;
-- ─── Branches ───
INSERT INTO dbo.Branches (city, address) VALUES
(N'Москва', N'ул. Тверская, 1'), -- id = 1
(N'Казань', N'пр. Победы, 10'), -- id = 2
(N'Сочи', N'ул. Курортная, 5'); -- id = 3 (без посылок)
-- ─── Vehicles ───
INSERT INTO dbo.Vehicles (type, capacity) VALUES
(N'Фургон', 100), -- id = 1
(N'Каблук', 50), -- id = 2
(N'Минивэн', 80), -- id = 3
(N'Грузовик', 200); -- id = 4 (без курьера)
-- ─── Couriers ───
INSERT INTO dbo.Couriers (full_name, vehicle_id) VALUES
(N'Алексей Петров', 1),
(N'Никита Смирнов', NULL), -- без транспорта
(N'Ольга Иванова', 2),
(N'Сергей Козлов', 3);
-- ─── Parcels ───
DECLARE @today DATE = CONVERT(date, GETDATE()); -- 2025-05-27
DECLARE @yday DATE = DATEADD(day,-1,@today); -- 2025-05-26
DECLARE @yyday DATE = DATEADD(day,-2,@today); -- 2025-05-25
INSERT INTO dbo.Parcels (weight, branch_id, courier_id, dispatched_at) VALUES
( 5, 1, 1, @today),
(12, 1, 1, @today),
( 2, 1, NULL, @today), -- филиал есть, курьера нет
(10, 2, 3, @today),
(15, 2, NULL, @today), -- филиал есть, курьера нет
( 7, NULL, 2, @today), -- курьер без филиала
( 9, NULL, NULL, @today), -- ни филиала, ни курьера
(20, 1, 1, @yday),
( 4, 2, 3, @yday),
( 6, 1, 1, @yday),
(40, 2, 3, @yyday),
( 3, NULL, NULL, @yyday); -- ни филиала, ни курьера
- 1. список всех посылок с именами курьеров, если они назначены (
LEFT JOIN). - 2. курьеры, у которых нет ни одной посылки на сегодняшнюю дату (
LEFT JOIN+WHERE p.parcel_id IS NULL). - 3. филиалы и число отправленных посылок, включая нулевую активность (
LEFT JOIN+ агрегат). - 4. посылки, у которых и филиал, и курьер не заданы (
FULL JOIN+ фильтр поIS NULL). - 5. «цепной» запрос Branches → Parcels → Couriers → Vehicles: вычислите нагрузку
weight / capacityи отсортируйте по убыванию, чтобы увидеть, где транспорт перегружают.
Проектирование БД (зачетное задание)
Модель создаётся в MS SQL Server 2022. Для каждой темы достаточно 5-7 взаимосвязанных таблиц с первичными и внешними ключами и обязательными CHECK, UNIQUE, DEFAULT- ограничениями. Базу нужно наполнить демонстрационные данными (≈ 10-20 строк в таблице). В результате работы сохранить dump файл с полученной системой + концептуальная и физическая модель.
Прим. Номер варианта вычисляется как «(Номер зачетки + 4) mod 10 + 1».
Условия зачета: 5-7 хорошо нормализованных таблиц, корректных ограничений ссылочной и предметной целостности, качественных демонстрационных данных и 7-8 правильно выполненных запросов.
Вариант 1 — Школьная лига по киберспорту
Лига объединяет команды общеобразовательных школ, соревнующиеся в двух популярных дисциплинах (например, CS и Dota 2). Для каждой школы хранится уникальный набор игроков с паспортными данными, учебным классом и никнеймами в игре; для дисциплин — карты, регламент раунда и возрастные ограничения. Расписание турнира состоит из группового этапа и плей-офф: база фиксирует дату, время, сервер, счёт раундов и продолжительность каждого матча. Параллельно ведётся учёт зрительской аудитории: система регистрирует пиковое и среднее онлайн-число зрителей на платформах YouTube и Twitch, а также продажи билетов на оффлайн-финал (партер, фан-зона, VIP-ложи). Призовой фонд формируется из спонсорских взносов компаний-партнёров и распределяется по этапам. Для аналитики хранения статистики предусмотрены показатели KDA каждого участника и история переходов игроков между командами.
Контрольные запросы
- календарь игр выбранной дисциплины на текущую неделю;
- турнирная таблица группы «А» c разницей раундов;
- команды без поражений после трёх туров;
- игроки, сменившие команду в этом сезоне;
- топ-5 матчей по пиковым зрителям;
- распределение призовых между тремя лучшими командами;
- продажи билетов в фан-зону по дням;
- суммарный онлайн-watch-time спонсора X;
- игроки с KDA > 3, сыгравшие минимум два матча;
- сформированная сетка плей-офф на основе итогов групп.
Вариант 2 — Платформа онлайн-курсов
Платформа размещает короткие и длительные курсы: каждый курс состоит из модулей, модули — из уроков-видео. Для урока фиксируются длительность, язык, дата обновления и рекомендуемая литература; для модуля — минимальный проходной балл теста. Пользовательская часть хранит слушателей с учётными записями, их платежи (стоимость, метод, дата), попытки прохождения контрольных и результаты тестов. При успешном закрытии курса платформа генерирует цифровой сертификат с уникальным номером и временем выдачи. Система рейтингов позволяет оставлять отзыв и числовую оценку как курсу в целом, так и каждому уроку. Отдельно учёт идёт по преподавателям: для них сохраняется портфель курсов, договорная ставка и налоги, а также средний рейтинг по их контенту. Для финансовой аналитики хранится помесячная выручка, источники трафика и статус возврата средств в течение гарантийного периода.
Контрольные запросы
- список слушателей курса «SQL Basics» и их прогресс;
- среднее время прохождения модуля № 2;
- курсы, где завершение < 60 % записавшихся;
- пять самых высоко оценённых уроков;
- лекции, просмотренные > 1000 раз;
- выручка по месяцам за текущий год;
- преподаватели, у которых более трёх активных курсов;
- слушатели, получившие сразу два сертификата в один день;
- рейтинг курсов по соотношению «оценка / длительность»;
- критические отзывы (оценка ≤ 2) за последние 30 дней.
Вариант 3 — Городской велопрокат
Сервис охватывает сеть станций по всему городу. Для каждой станции фиксируются координаты, вместимость и статус (активна, на ремонте). Велопарк делится на механические и электрические модели с разной стартовой ценой и тарифом за минуту; для электробайков дополнительно хранится остаточный заряд и дата последней замены аккумулятора. Пользователь профилируется по ID приложения, возрасту и способу оплаты; указывается наличие годового абонемента. Каждая поездка содержит время начала и окончания, начальную и конечную станцию, протяжённость и списанную сумму. Журнал технического обслуживания отражает дату последнего ТО, пробег, обнаруженные неисправности и затраты на ремонт. Для анализа популярности тарифов сохраняется справочник тарифных планов (разовый, дневной, месячный) и счётчик активированных планов по датам.
Контрольные запросы
- свободные велосипеды на станции «Парк Горького»;
- пользователи, совершившие > 15 поездок за месяц;
- средняя длительность аренды по дням недели;
- станции с наибольшим числом возвратов вечером (18-22);
- велосипеды, проехавшие > 500 км со дня последнего ТО;
- динамика общего пробега парка помесячно;
- коэффициент оборачиваемости для каждой станции;
- популярность тарифов за квартал;
- топ-10 самых длинных поездок;
- список пользователей, у которых было два и более штрафа.
Вариант 4 — Городская библиотека
Каталог библиотеки содержит книги, разделённые по жанрам и возрастным категориям, с указанием автора, издательства, года издания и уникального ISBN. Для каждой книги хранится несколько экземпляров с инвентарным номером, текущим местоположением (зал, на руках, ремонт) и состоянием (отличное, хорошее, ветхое). Читательская карточка фиксирует паспортные данные, контактную информацию и историю всех визитов. Операции выдачи и возврата записываются с датой, сроком возврата и автоматически рассчитываемым штрафом при просрочке. Культурно-просветительский блок описывает мероприятия — презентации, клубы по интересам, встречи авторов — c датой, организатором, списком зарегистрированных читателей и максимальной вместимостью зала. Дополнительно ведётся журнал ремонтных работ экземпляров: дата отправки, предполагаемая дата возврата и стоимость ремонта.
Контрольные запросы
- книги без свободных экземпляров;
- читатели с долгом > 300 ₽;
- выдачи за последний месяц по жанрам;
- мероприятия на ближайшие 14 дней и число регистраций;
- экземпляры в ремонте дольше двух недель;
- самые читаемые авторы года;
- средняя задержка возврата по жанрам;
- читатели, не посещавшие библиотеку > 90 дней;
- книги, выданные > 50 раз с начала года;
- динамика штрафных оплат помесячно.
Вариант 5 — Сеть кофеен
Каждое заведение хранит общий справочник рецептур: ингредиенты (зёрна, молоко, сиропы) с нормой на порцию, калорийностью и себестоимостью. Заказы делятся на «зал» и «take-away»; для каждого заказа фиксируются позиции меню, время от принятия до выдачи и способ оплаты. Программа лояльности хранит кошелёк бонусов, дату последней транзакции и сегмент клиента (новый, регуляр, VIP). Инвентаризация ведётся по остаткам ингредиентов на начало смены, поступлению и списанию; суточная норма выводится из суммарных продаж. Рабочие смены бариста содержат дату, длительность, количество приготовленных напитков и итоговый средний рейтинг по чек-беку пользователя. Для оценки эффективности маркетинга базируется справочник акций, период действия и правила (скидка %, 2 + 1, подарок).
Контрольные запросы
- хиты продаж недели (топ-5 позиций);
- средний чек по типу обслуживания;
- ингредиенты с остатком ниже дневной нормы;
- бариста с наивысшим средним рейтингом;
- 95-й перцентиль времени ожидания заказа;
- выручка каждой кофейни за вчера;
- клиенты, сделавшие ≥ 3 покупок за 7 дней;
- продажи акционных позиций и их доля;
- корреляция «рейтинг точки ↔ средний чек»;
- динамика расхода молока по неделям.
Вариант 6 — Мини-отель
Отель насчитывает до 25 номеров различных категорий (эконом, стандарт, улучшенный, люкс). Для номера хранятся площадь, количество спальных мест и цена за ночь, вариативная по сезону. Бронирование указывает дату заезда и выезда, канал брони (сайт, агрегатор, телефон), статус оплаты и флаг «гарантированное». В карточке гостя сохраняются личные данные, предпочтения (тип подушки, этаж), а также история прошлых проживаний и оценок. Каталог дополнительных услуг включает завтрак-шведский стол, поздний выезд, трансфер в аэропорт; каждая услуга привязывается к бронированию отдельной записью. Модуль «Хозяйственная служба» фиксирует статусы уборки, даты и стоимость ремонтных работ. Выручка агрегируется по дням: проживание, услуги, штрафы за незаезд.
Контрольные запросы
- свободные номера на произвольный диапазон дат;
- загрузка по категориям за месяц;
- гости с более чем двумя повторными визитами;
- средняя длительность пребывания;
- доход от дополнительных услуг;
- бронирования, отменённые < 24 ч до заезда;
- номера, находившиеся на ремонте > 5 дней;
- динамика выручки по каналам;
- коэффициент no-show по месяцам;
- средняя цена номера в разрезе сезонов.
Вариант 7 — Учебное расписание университета
Учебный модуль хранит список дисциплин с трудоёмкостью, семестр и формой контроля. Преподавательский справочник включает учёную степень, должность и норму часов в нагрузке. Каждая аудитория имеет вместимость, тип (лекционная, лаборатория, компьютерный класс) и оборудование (проектор, системы видеоконференций). Для занятия фиксируются группа, дисциплина, преподаватель, аудитория, дата, пара и формат (очно, онлайн). Посещаемость хранится отдельной таблицей с флагами «присутствовал», «опоздал», «уважительная причина». Для ведомости оценок указывается семестр, дисциплина, студент, балл, дата сдачи и номер перепроверки. Справочник групп содержит факультет, направление, год набора и старосту.
Контрольные запросы
- расписание группы ИВТ-21-1 на неделю;
- аудитории, занятые > 80 % времени;
- преподаватели, имеющие «окно» > 2 ч между парами;
- пересечения бронирований одной аудитории;
- средний балл по дисциплине «Базы данных»;
- список студентов-отличников факультета;
- нагрузка преподавателей в часах;
- дисциплины без назначенной аудитории;
- посещаемость занятий по датам;
- доля очных занятий, заменённых на онлайн.
Вариант 8 — Автосервис
Сервис обслуживает легковые автомобили: для каждой машины хранится VIN, марка, модель, год выпуска и пробег. Заказ-наряд включает работы (диагностика, замена масла и т.п.), стоимость запчастей, зарплату мастера и итоговую сумму счета. Каталог работ содержит нормативное время и тариф; каталог запчастей — поставщика, складской остаток, минимальный запас и цену закупки. Расписание постов состоит из даты, мастера, поста и статуса «свободен/занят». Лабораторный блок хранит дефектовку деталей: выявленные неисправности, фотографию повреждений (путь к файлу) и заключение инженера. Для повторных обращений фиксируется ссылка на предыдущий заказ-наряд и причина возврата клиента.
Контрольные запросы
- автомобили, ожидающие выдачи > 2 дней после готовности;
- топ-5 самых частых услуг;
- мастера с выработкой > 160 ч за месяц;
- запас запчастей ниже минимального;
- средняя стоимость ремонта по моделям;
- заказы, где срок ремонта превысил плановый;
- доход автосервиса по неделям;
- заказы с повторным обращением по той же проблеме;
- модели, требующие больше всего времени на обслуживание;
- коэффициент использования постов в дневную смену.
Вариант 9 — Студия групповых тренировок
Расписание студии формируется из программ (йога, HIIT, пилатес), каждая из которых имеет минимальное и максимальное количество участников, длительность и уровень сложности. Для тренера хранится квалификация, специализация и средний рейтинг по отзывам. Абонементы делятся на типы (4/8/12 занятий, безлимит) с разной ценой и сроком действия; система продаж фиксирует дату покупки, канал (касса, онлайн), использованные бонусы. Таблица визитов отражает факт присутствия, опоздание, заморозку абонемента и списание занятия. Бар-магазин хранит ассортимент мерча и напитков; продажи барной зоны поддерживаются отдельными записями, но могут быть связаны с клиентом. Для анализа загрузки залов указываются интервалы суток и вместимость.
Контрольные запросы
- посещаемость занятия «HIIT 18:00» за месяц;
- клиенты без визитов > 30 дней;
- тренеры с средним рейтингом ≥ 4,8;
- загруженность залов по часам;
- выручка от абонементов и разовых посещений;
- занятия, отменённые по недоуплотнению (< 3 записей);
- среднее заполнение групп по программам;
- продажи мерча и воды в баре;
- топ-10 самых лояльных клиентов;
- динамика продаж абонементов перед Новым годом.
Вариант 10 — Центр помощи бездомным животным
Для каждого животного хранятся кличка, вид, порода, дата поступления, чип-ID и текущий статус (в приюте, на домашнем передержке, усыновлено). Медицинская карта содержит диагоноз, прививки и назначения ветеринара с датой следующего осмотра. Профиль волонтёра фиксирует контакты, доступные смены и общее отработанное время. Заявка на усыновление связывает потенциального хозяина, выбранное животное, этапы одобрения (звонок, визит, проверка условий), дату финальной передачи и возможный возврат. Модуль фонда отражает пожертвования по каналам, целевые программы (корма, стерилизация) и фактическое расходование средств. Складской раздел хранит остатки кормов и лекарств с датой окончания годности.
Контрольные запросы
- животные, находящиеся в центре > 90 дней;
- среднее время пристройства по породам;
- поступления животных за месяц по причинам;
- активные заявки на усыновление и их статус;
- волонтёры с > 20 ч помощи за месяц;
- пожертвования по каналам;
- животные, требующие повторного мед-осмотра;
- доля усыновлений, завершившихся возвратом;
- потребность в кормах и лекарствах на неделю;
- динамика поступлений и пристройств за год.
Часть 1: Вспоминаем основы С++
Цель: повтор основных элементов и синтаксиса C++.
Краткое содержание:
- Указатели и работа с динамической памятью
- Подпрограммы (функции / методы)
- Модификаторы видимости
- Структуры
- Классы и объекты
- Конструкторы
- Операторы присваивания
- Деструкторы
- Правило "трёх" / "пяти"
Часть 2: Введение в ООП
Цель: знакомство с основными принципами ООП.
Знакомство с ключевыми принципами ООП:
- Инкапсуляцией;
- Наследование
- Полиморфизм
Новые элементы синтаксиса:
- Перегрузка функций и операторов
- Шаблоны
- Статические члены класса
- Дружественные функции и классы
Часть 3: Применение ООП в практическом решении задач
Цель: закрепление знаний и навыков, полученных на прошлых занятиях. Задания для самостоятельной работы:
- Задача 1: Система поиска по документам и файлам;
- Задача 2: Система бронирования отелей.
Часть 4: Паттерны проектирования
Принципы проектирования:
MVC (Model-View-Controller)
MVC разделяет приложение на три компонента: Model, View и Controller. Модель отвечает за управление данными и бизнес-логику, Вид отображает интерфейс пользователю, а Контроллер обрабатывает пользовательский ввод и взаимодействует с Моделью и Видом. Этот паттерн используется для того, чтобы отделить логику приложения от его интерфейса, повышая масштабируемость и удобство поддержки продукта в будущем.
Задача: разработать систему управления каталогом товаров.
-
Упрощенный вариант (консольное приложение):
- Создать консольное приложение, позволяющее пользователям управлять каталогом товаров.
- Модель хранит данные о товарах (название, цена, количество).
- Контроллер обрабатывает ввод пользователя.
- Вид отображает данные в консоли.
-
Усложненный вариант (GUI с использованием Qt):
- Приложение с графическим интерфейсом, где пользователи могут просматривать и редактировать товары.
- Модель хранит данные в виде списка.
- Вид предоставляет интерфейс на основе Qt, позволяющий управлять товарами через формы и таблицы.
Порождающие паттерны
Фабричный метод
Паттерн Фабричный Метод определяет интерфейс создания объекта, но позволяет субклассам выбрать класс создаваемого экемпляра. Таким образом, Фабричный Метод делегирует операцию создания экземпляра субклассам.
- Одиночка
- Прототип
Структурные паттерны
Адаптер
Паттерн Адаптер используется для преобразования интерфейса одного класса в интерфейс, ожидаемый клиентом. Адаптер позволяет классам с несовместимыми интерфейсами работать вместе.
- Компоновщик
- Декоратор
Поведенческие паттерны
Наблюдатель
Паттерн Наблюдатель определяет отношение "один ко многим" между объектами таким образом, что при изменении состояния одного объекта происходит автоматическое оповещение и обновление всех зависимых объектов.
- Стратегия
- Состояние
Часть 5: Проверка усвоенного материала
В качестве финального задания курса, необходимо разработать программу в соответствии с номером варианта, который определяется по формуле: номер зачетки % {кол-во вариантов} + 1.
Задания могут быть выполненны в обычном и усложненном варианте. Обычный вариант - консольная программа. Для усложненного варианта необходимо реализовать графический интерфейс с использованием Qt или ImGui.
Как скачать и установить Qt?
1. Скачиваем установщик
Перейдите по ссылке на официальный сайт Qt. Выберите установщик, соответствующий вашей системе, и нажмите на кнопку "Qt Online Installer...".
2. Запускаем установку
Дождитесь завершения загрузки exe-файла и запустите его.
3. Регистрация
В открывшемся окне выберите "Зарегистрироваться".
4. Ввод данных
Введите вашу почту, пароль, примите условия соглашения и нажмите "Далее".
5. Подтверждение почты
Перейдите в почтовый ящик, откройте письмо от The Qt Company и подтвердите регистрацию, кликнув по ссылке.
6. Заполнение профиля
Заполните данные, поставьте галочку "I am an individual person not using Qt for any company" и нажмите "Confirm".
7. Авторизация в установщике
Вернитесь к установщику, войдите под своей учетной записью и нажмите на кнопку в левом нижнем углу (выделено красным).
8. Настройка прокси
В открывшемся окне выберите "Ручная настройка прокси-сервера". В поле "HTTP прокси-сервер" введите proxy.quterussia.ru, а в поле "Порт" — 31031. Нажмите "ОК".
9. Продолжение установки
Авторизуйтесь под своей учетной записью. Поставьте все галочки и нажмите "Далее".
10. Выбор установки
Выберите "Выборочная установка" и нажмите "Далее".
11. Выбор компонентов
Установите галочки, как показано на изображении ниже, и нажмите "Далее". Если не знаете, какой компилятор выбрать — выберите MinGW.
12. Завершение установки
Примите условия лицензионного соглашения, нажмите "Далее", затем "Установить".
Часть 1. Вспоминаем основы C++
В этом разделе мы освежим в памяти ключевые определения C++: указатели, динамическое управление памятью, функции, модификаторы видимости и классы.
1. Ссылки и указатели, работа с динамической памятью
Работа с указателями и динамической памятью — одна из основ C++, так как это напрямую влияет на производительность и безопасность программ.
- Презентация по ссылкам и указателям
- Динамическое выделение и освобождение памяти (операторы
newиdelete) - Умные указатели
Умные указатели — это современная концепция в C++, которая автоматизирует управление памятью, значительно снижая вероятность утечек памяти. Базовая информация о "умных указателях" хорошо разобрана в видеоуроке.
Основные понятия:
-
Сырые указатели: Хранят прямой адрес в памяти.
int* p = new int(10); // Динамическое выделение памяти delete p; // Очистка выделенной памяти -
Умные указатели: Упрощают управление памятью с помощью классов
std::unique_ptrиstd::shared_ptr, что исключает необходимость ручного удаления памяти.// Память автоматически освободится при выходе за область видимости std::unique_ptr<int> ptr = std::make_unique<int>(10);
Практическое задание: решаем Задачу 3 из раздела по матрицам.
2. Подпрограмммы
- Презентация по подпрограмммы
- Документ с заданиями. Решаем задачу повышенной сложности и задачу 2 из блока с рекурсией.
Пример простой подпрограммы:
#include <iostream>
// Функция для сложения двух чисел
int add(int a, int b) {
return a + b;
}
int main() {
int result = add(3, 5);
std::cout << "Сумма: " << result << std::endl;
return 0;
}
Методы и подпрограммы: в чем разница?
Методы — это подпрограммы, которые принадлежат классу. Они работают с данными, принадлежащими объектам этого класса. В отличие от обычных подпрограмм, методы всегда связаны с объектами и манипулируют их состоянием.
3. Модификаторы видимости
Модификаторы видимости контролируют доступ к членам класса или структуры (переменным и функциям). C++ предоставляет три основных модификатора:
public: Члены класса доступны извне.private: Члены класса доступны только внутри самого класса.protected: Члены класса доступны внутри класса и его дочерних классов.
4. Структуры
Структуры в C++ — это пользовательские типы данных, которые группируют переменные под одним именем.
- Презентация по структурам
- Документ с заданиями. Решаем задачу 2.
В структурах все члены по умолчанию имеют модификатор видимости
public.
Пример простой структуры:
struct Point {
int x;
int y;
};
int main() {
Point p;
p.x = 10;
p.y = 20;
std::cout << "Точка: (" << p.x << ", " << p.y << ")" << std::endl;
return 0;
}
5. Классы и объекты
Классы — это ключевой элемент объектно-ориентированного программирования (ООП) в C++. Они позволяют объединить данные (члены данных) и функции (методы) в одну сущность. Объекты — это конкретные экземпляры классов, которые могут обладать своими уникальными состояниями.
Конструкторы
Конструкторы — это специальные методы класса, которые вызываются автоматически при создании объекта и предназначены для инициализации его состояния. В C++ можно определить несколько типов конструкторов для разных целей.
Виды конструкторов:
1. Конструктор по умолчанию
Не принимает аргументов и используется для инициализации объекта без входных данных.
class Rectangle {
private:
int width;
int height;
public:
Rectangle() : width(0), height(0) {} // Конструктор по умолчанию
};
2. Конструктор с параметрами
Принимает параметры и инициализирует члены класса конкретными значениями.
class Rectangle {
private:
int width;
int height;
public:
Rectangle(int w, int h) : width(w), height(h) {} // Конструктор с параметрами
};
3. Конструктор копирования
Создаёт новый объект на основе существующего.
class Rectangle {
private:
int width;
int height;
public:
Rectangle(const Rectangle& rect) : width(rect.width), height(rect.height) {} // Конструктор копирования
};
4. Конструктор перемещения
Перемещает ресурсы от одного объекта к другому без их копирования (C++11 и выше).
class Rectangle {
private:
int* data;
public:
Rectangle(Rectangle&& rect) noexcept : data(rect.data) {
rect.data = nullptr;
} // Конструктор перемещения
};
Операторы присваивания
Конструкторы позволяют создавать объекты, но для их изменения или копирования используются операторы присваивания.
1. Оператор присваивания копирования
Осуществляет копирование данных одного объекта в другой.
class Rectangle {
private:
int* data;
public:
Rectangle& operator=(const Rectangle& rect) {
if (this == &rect) return *this; // Защита от самоприсваивания
delete data; // Очистка предыдущих данных
data = new int(*rect.data); // Копирование
return *this;
}
};
2. Оператор присваивания перемещения
Перемещает ресурсы от одного объекта к другому без копирования (C++11 и выше).
class Rectangle {
private:
int* data;
public:
Rectangle& operator=(Rectangle&& rect) noexcept {
if (this == &rect) return *this;
delete data; // Очистка предыдущих данных
data = rect.data; // Перемещение данных
rect.data = nullptr; // Очищаем исходный объект
return *this;
}
};
Деструктор
Деструктор вызывается автоматически при уничтожении объекта для освобождения любых ресурсов, выделенных для него.
class Rectangle {
private:
int* data;
public:
~Rectangle() {
delete data; // Освобождение динамической памяти
std::cout << "Прямоугольник уничтожен" << std::endl;
}
};
Для подробного изучения конструкторов и деструкторов см. видеоурок.
Листы инициализации
Листы инициализации позволяют инициализировать члены класса до выполнения тела конструктора.
class Rectangle {
private:
const int width;
int height;
public:
Rectangle(int w, int h) : width(w), height(h) {}
};
Правило "Трёх" и "Пяти"
Если класс управляет динамическими ресурсами, необходимо следовать правилу трёх или пяти:
- Конструктор копирования.
- Оператор присваивания копирования.
- Деструктор.
- Конструктор перемещения (C++11).
- Оператор присваивания перемещения (C++11).
Удаление стандартных конструкторов
В некоторых случаях необходимо удалить автоматические версии стандартных конструкторов. Это делается для предотвращения копирования или перемещения объектов класса. Обычно это требуется для классов, управляющих уникальными ресурсами, такими как файлы, сокеты или потоки.
Пример удаления конструкторов:
class NonCopyable {
public:
NonCopyable() = default; // Конструктор по умолчанию
NonCopyable(const NonCopyable&) = delete; // Удалённый конструктор копирования
NonCopyable& operator=(const NonCopyable&) = delete; // Удалённый оператор присваивания
};
Задания для самостоятельной работы
Задание 1: Реализация класса Book
Создайте класс Book, который моделирует книгу в библиотеке.
Требования:
- У класса должны быть члены данных:
- Название книги (строка).
- Автор (строка).
- Год издания (целое число).
- Количество страниц (целое число).
- Конструктор должен принимать название книги, автора и год издания. Количество страниц задаётся по умолчанию равным 0.
- Реализуйте методы:
setPages(int pages): метод для установки количества страниц.getDescription(): метод для вывода информации о книге в формате: "Название: ..., Автор: ..., Год: ..., Страниц: ...".
- Реализуйте конструктор копирования и оператор присваивания для класса.
Пример использования:
int main() {
Book book1("Война и мир", "Лев Толстой", 1869);
book1.setPages(1225);
book1.getDescription(); // Ожидаемый вывод: Название: Война и мир, Автор: Лев Толстой, Год: 1869, Страниц: 1225
Book book2 = book1; // Копирование
book2.getDescription(); // Ожидаемый вывод: Название: Война и мир, Автор: Лев Толстой, Год: 1869, Страниц: 1225
return 0;
}
Вариант реализации (стараемся сильно не смотреть сюда):
#include <iostream>
#include <string>
class Book {
private:
std::string m_title;
std::string m_author;
int m_year;
int m_pages;
public:
Book(const std::string& title, const std::string& author, int year, int pages = 0)
: m_title(title), m_author(author), m_year(year), m_pages(pages) {}
Book(const Book& other)
: m_title(other.m_title), m_author(other.m_author), m_year(other.m_year), m_pages(other.m_pages) {}
Book& operator=(const Book& other) {
if (this == &other) return *this;
m_title = other.m_title;
m_author = other.m_author;
m_year = other.m_year;
m_pages = other.m_pages;
return *this;
}
void setPages(int pages) {
m_pages = pages;
}
void getDescription() const {
std::cout << "Название: " << m_title
<< ", Автор: " << m_author
<< ", Год: " << m_year
<< ", Страниц: " << m_pages << std::endl;
}
};
int main() {
Book book1("Война и мир", "Лев Толстой", 1869);
book1.setPages(1225);
book1.getDescription();
Book book2 = book1;
book2.getDescription();
return 0;
}
Задание 2: Класс Vector с управлением ресурсами
Создайте класс Vector, который будет динамически управлять массивом целых чисел.
Требования:
- Конструктор с параметром: Принимает размер массива и инициализирует его элементами (например, нулями).
- Конструктор копирования: Создайте конструктор копирования, который делает глубокую копию массива.
- Конструктор перемещения: Реализуйте конструктор перемещения, который перемещает данные из одного объекта в другой, освобождая исходный объект.
- Оператор присваивания копированием: Реализуйте оператор присваивания, который корректно копирует данные с проверкой на самоприсваивание.
- Оператор присваивания перемещением: Реализуйте оператор присваивания перемещением для оптимизации работы с временными объектами.
- Метод
sum(): Напишите метод, который вычисляет сумму всех элементов в массиве. - Деструктор: Освобождает ресурсы (память), выделенные для массива.
Дополнительные задачи (рекомендуется):
- Метод
resize(size_t new_size): Добавьте возможность изменять размер массива. Если новый размер больше старого, новые элементы инициализируются нулями. Если меньше — лишние элементы удаляются. - Метод
slice(size_t start, size_t end): Реализуйте метод, который возвращает подмассив (срез) от индексаstartдо индексаend(включительно). Срез должен возвращаться как новый объектVector. - Итераторы: Реализуйте методы
begin()иend()для поддержки диапазонных циклов (range-based for loops). Это позволит использовать объектVectorв стандартных конструкциях цикла. - Метод
push_back(int value): Добавьте возможность добавлять элемент в конец массива, динамически увеличивая его размер. - Метод
find(int value): Реализуйте метод поиска элемента. Возвращает индекс первого найденного элемента с данным значением или-1, если элемент не найден.
Пример использования:
int main() {
Vector v1(5); // Вектор из 5 элементов
v1.push_back(10); // Добавление элемента в конец
Vector v2 = v1.slice(1, 3); // Создание среза вектора
Vector v3 = v2; // Копирование
Vector v4 = std::move(v2); // Перемещение
for (int x : v4) { // Использование итераторов
std::cout << x << " ";
}
std::cout << "Сумма элементов v3: " << v3.sum() << std::endl;
std::cout << "Индекс элемента 10 в v4: " << v4.find(10) << std::endl;
return 0;
}
Вариант реализации основных требований (стараемся сильно не смотреть сюда):
#include <iostream>
#include <algorithm>
#include <numeric>
class Vector {
private:
int* m_data;
size_t m_size;
public:
Vector(size_t size) : m_size(size), m_data(new int[size]) {
std::fill(m_data, m_data + m_size, 0);
}
Vector(const Vector& other) : m_size(other.m_size), m_data(new int[other.m_size]) {
std::copy(other.m_data, other.m_data + other.m_size, m_data);
}
Vector(Vector&& other) noexcept : m_size(other.m_size), m_data(other.m_data) {
other.m_data = nullptr;
other.m_size = 0;
}
Vector& operator=(const Vector& other) {
if (this == &other) return *this;
delete[] m_data;
m_size = other.m_size;
m_data = new int[m_size];
std::copy(other.m_data, other.m_data + m_size, m_data);
return *this;
}
Vector& operator=(Vector&& other) noexcept {
if (this == &other) return *this;
delete[] m_data;
m_data = other.m_data;
m_size = other.m_size;
other.m_data = nullptr;
other.m_size = 0;
return *this;
}
int sum() const {
return std::accumulate(m_data, m_data + m_size, 0);
}
~Vector() {
delete[] m_data;
}
};
int main() {
Vector v1(5);
std::cout << "Сумма элементов: " << v1.sum() << std::endl;
Vector v2 = v1;
std::cout << "Сумма элементов (копия): " << v2.sum() << std::endl;
Vector v3 = std::move(v1);
std::cout << "Сумма элементов (перемещение): " << v3.sum() << std::endl;
return 0;
}
Задание 3: Класс Matrix с использованием Vector
Создайте класс Matrix, который будет динамически управлять двумерным массивом (матрицей) целых чисел, используя класс Vector, разработанный в задании 2, для хранения строк матрицы.
Требования:
- Конструктор с параметрами: Принимает количество строк и столбцов и инициализирует их элементами, используя объекты
Vectorдля хранения строк. - Конструктор копирования: Создайте конструктор копирования, который делает глубокую копию матрицы, используя глубокое копирование векторов.
- Конструктор перемещения: Реализуйте конструктор перемещения, который перемещает данные из одного объекта в другой, освобождая исходный объект.
- Оператор присваивания копированием: Реализуйте оператор присваивания, который корректно копирует данные матрицы с проверкой на самоприсваивание.
- Оператор присваивания перемещением: Реализуйте оператор присваивания перемещением для оптимизации работы с временными объектами.
- Метод
transpose(): Напишите метод, который транспонирует матрицу, меняя строки и столбцы местами (выполняйте перестановку векторов). - Деструктор: Освобождает ресурсы (память), выделенные для матрицы, а также освобождает все используемые векторы.
Дополнительные задачи (рекомендуется):
- Метод
resize(size_t new_rows, size_t new_cols): Используйте методresize()классаVectorдля изменения размеров матрицы. Если новые размеры больше старых, новые элементы инициализируются нулями. - Метод
slice(size_t row_start, size_t row_end, size_t col_start, size_t col_end): Реализуйте метод, который возвращает подматрицу (срез), используя срезы векторов (методslice()классаVector). - Метод
determinant(): Реализуйте метод для вычисления детерминанта матрицы (для квадратных матриц). - Метод
multiply(const Matrix& other): Реализуйте метод, который умножает матрицу на другую матрицу. Проверьте совместимость размеров для умножения. - Метод
find(int value): Реализуйте метод поиска элемента в матрице, используя методfind()классаVector. Возвращает пару индексов (строка, столбец) первого найденного элемента.
Пример использования:
int main() {
Matrix m1(3, 3); // Матрица 3x3
m1.resize(4, 4); // Изменение размера матрицы на 4x4
Matrix m2 = m1.slice(1, 3, 1, 3); // Создание подматрицы
Matrix m3 = m2; // Копирование
Matrix m4 = std::move(m2); // Перемещение
m4.transpose(); // Транспонирование матрицы
std::pair<int, int> pos = m4.find(10); // Поиск элемента в матрице
std::cout << "Позиция элемента 10: (" << pos.first << ", " << pos.second << ")" << std::endl;
return 0;
}
Введение в ООП
Крайне рекомендую перед выполнения практических заданий ознакомиться с хорошей лекцией от преподавателя мехмата МГУ по ссылке. После этого можете ознакомиться с его другими лекциями по С++, информацию преподносит достаточно кратко и ёмко, зачастую упоминает интересные нюансы и особенности, на скорости x1,5 смотрится вполне комфортно.
1. Инкапсуляция
Теоретическая справка:
Инкапсуляция — это принцип ООП, который предполагает сокрытие данных и предоставление контролируемого доступа к ним через специальные методы. В C++ это достигается с помощью модификаторов доступа (private, public, protected). Приватные данные защищены от прямого изменения, и для работы с ними используются геттеры и сеттеры — специальные методы для получения и изменения значений приватных переменных.
- Геттеры предоставляют доступ к приватным данным.
- Сеттеры позволяют изменять приватные данные с дополнительной проверкой.
Инкапсуляция обеспечивает контроль над тем, как изменяются и используются данные в классе, и помогает защитить их от некорректного использования.
Синтаксис:
Пример инкапсуляции с использованием геттеров и сеттеров на примере управления складом:
class Warehouse {
private:
int itemCount;
public:
Warehouse(int initialCount) : itemCount(initialCount) {}
// Геттер для получения количества товаров
int getItemCount() const {
return itemCount;
}
// Сеттер для добавления товаров с проверкой
void addItem(int count) {
if (count > 0) {
itemCount += count;
}
}
// Сеттер для удаления товаров с проверкой
void removeItem(int count) {
if (count > 0 && count <= itemCount) {
itemCount -= count;
}
}
};
int main() {
Warehouse warehouse(100); // Создание склада с 100 единицами товара
warehouse.addItem(50); // Добавление товаров на склад
warehouse.removeItem(30); // Удаление товаров со склада
std::cout << "Current item count: " << warehouse.getItemCount() << std::endl; // Вывод текущего количества товаров
return 0;
}
В этом примере класс Warehouse инкапсулирует переменную itemCount, предоставляя доступ к ней только через методы getItemCount(), addItem(), и removeItem(), что позволяет контролировать изменение количества товаров на складе.
Задача: Моделирование банковского счета
Необходимо создать класс BankAccount, который инкапсулирует данные о счете: владелец и баланс. Методы класса:
deposit(double amount)— пополнение счета.withdraw(double amount)— снятие средств с проверкой на достаточность баланса.getBalance()— геттер для доступа к балансу.setOwner(std::string owner)— сеттер для изменения владельца счета.displayInfo()— вывод информации о счете.
Пример работы программы:
Входные данные:
- Создание счета для "Иван Иванов" с балансом 1000 рублей.
- Пополнение на 500 рублей.
- Снятие 300 рублей.
- Снятие 1500 рублей (превышение доступного баланса).
Выходные данные:
Владелец: Иван Иванов, Баланс: 1000 руб.
На счет зачислено: 500 руб. Баланс: 1500 руб.
Со счета снято: 300 руб. Баланс: 1200 руб.
Ошибка: Недостаточно средств на счете!
Владелец: Иван Иванов, Баланс: 1200 руб.
Вариант реализации основных требований:
#include <iostream>
#include <string>
class BankAccount {
private:
std::string owner; // Владелец счета
double balance; // Баланс счета
public:
// Конструктор для инициализации счета
BankAccount(std::string ownerName, double initialBalance) {
owner = ownerName;
balance = initialBalance;
}
// Метод для пополнения счета
void deposit(double amount) {
if (amount > 0) {
balance += amount;
std::cout << "На счет зачислено: " << amount << " руб. Баланс: " << balance << " руб.\n";
} else {
std::cout << "Ошибка: Некорректная сумма пополнения!\n";
}
}
// Метод для снятия средств со счета
void withdraw(double amount) {
if (amount <= balance) {
balance -= amount;
std::cout << "Со счета снято: " << amount << " руб. Баланс: " << balance << " руб.\n";
} else {
std::cout << "Ошибка: Недостаточно средств на счете!\n";
}
}
// Геттер для получения текущего баланса
double getBalance() {
return balance;
}
// Сеттер для изменения владельца счета
void setOwner(std::string newOwner) {
owner = newOwner;
}
// Метод для вывода информации о счете
void displayInfo() {
std::cout << "Владелец: " << owner << ", Баланс: " << balance << " руб.\n";
}
};
int main() {
BankAccount account("Иван Иванов", 1000);
account.displayInfo(); // Владелец: Иван Иванов, Баланс: 1000 руб.
account.deposit(500); // На счет зачислено: 500 руб. Баланс: 1500 руб.
account.withdraw(300); // Со счета снято: 300 руб. Баланс: 1200 руб.
account.withdraw(1500); // Ошибка: Недостаточно средств на счете!
account.displayInfo(); // Владелец: Иван Иванов, Баланс: 1200 руб.
return 0;
}
Дополнительные задания:
- Добавьте проверку при изменении владельца счета через сеттер (владелец не может быть пустым).
- Добавьте ограничение на количество операций пополнения/снятия в сутки (например, не более 5 операций).
- Добавьте поддержку мультивалютных счетов, чтобы можно было хранить баланс в разных валютах.
2. Наследование
Теоретическая справка:
Наследование — это механизм ООП, который позволяет создавать новые классы на основе существующих. Базовый класс содержит общие свойства и методы, которые могут быть унаследованы производными классами. Наследники могут добавлять новые функции или переопределять существующие методы для изменения поведения.
Наследование позволяет создавать иерархии классов, где производные классы используют общие черты базового класса, но могут переопределять или расширять функционал, добавляя собственные методы или свойства.
Синтаксис:
Пример наследования:
class Vehicle {
public:
void start() const {
std::cout << "Vehicle is starting.";
}
void stop() const {
std::cout << "Vehicle is stopping.";
}
};
class Car : public Vehicle {
public:
void honk() const {
std::cout << "Car is honking.";
}
};
class Bicycle : public Vehicle {
public:
void ringBell() const {
std::cout << "Bicycle is ringing the bell.";
}
};
int main() {
Car myCar;
Bicycle myBike;
myCar.start();
myCar.honk();
myCar.stop();
myBike.start();
myBike.ringBell();
myBike.stop();
return 0;
}
Машина и велосипед могут выполнять одинаковые действия - старт и остановка. Однако, каждый из них также может реализовывать специфичные действия, автомобиль - сигналить (метод honk), а велосипед использовать звонок (метод ringBell).
Для чего используется:
- Повторное использование кода: Наследование позволяет избежать дублирования кода, создавая общий базовый класс для связанных объектов. В системе управления заказами можно создать базовый класс
Order, от которого наследуются классыOnlineOrderиOfflineOrder, добавляющие специфичные для их типов данные. - Создание специализированных классов: Наследование позволяет расширять функциональность базовых классов, создавая специализированные классы с добавлением новых свойств и методов. В системе учета сотрудников можно создать базовый класс
Employeeи производные классыManagerиIntern, у каждого из которых будут свои особенности.
Когда лучше избегать:
- Чрезмерное наследование: Если слишком глубоко использовать наследование, это может усложнить поддержку кода и снизить его читаемость. В системе управления проектами чрезмерное использование наследования для каждого типа задач может усложнить архитектуру и затруднить внесение изменений.
- Нарушение принципа слабой связанности: При использовании наследования слишком часто можно нарушить принцип слабой связанности, когда классы становятся слишком зависимыми друг от друга. В системе управления продуктами создание слишком связанных классов, где изменение в одном классе требует изменений в других, может усложнить поддержку системы.
Задача: Наследование для модели животных
Создайте базовый класс Animal с методами move() и makeSound(), где move() будет одинаковым для всех животных, а метод makeSound() заменяется специфическими для каждого наследника методами: bark() для собак и meow() для кошек. Затем создайте классы-наследники Dog и Cat. Для класса Dog добавьте метод fetchStick(), чтобы собака могла приносить палку.
Пример работы программы:
Входные данные:
- Создание объектов
DogиCat. - Вызов методов
move(),bark(), иfetchStick()для собаки. - Вызов методов
move()иmeow()для кошки.
Выходные данные:
Животное двигается.
Собака лает.
Собака приносит палку.
Животное двигается.
Кошка мяукает.
Вариант реализации основных требований:
#include <iostream>
#include <string>
// Базовый класс Animal
class Animal {
public:
// Метод для звуков, общий для всех животных
void makeSound() const {
std::cout << "Животное издает звук.\n";
}
// Метод для движения, общий для всех животных
void move() const {
std::cout << "Животное двигается.\n";
}
};
// Класс Dog (Собака), наследник Animal
class Dog : public Animal {
public:
// Специфический метод для собаки - принести палку
void fetchStick() const {
std::cout << "Собака приносит палку.\n";
}
// Специфический звук собаки
void bark() const {
std::cout << "Собака лает.\n";
}
};
// Класс Cat (Кошка), наследник Animal
class Cat : public Animal {
public:
// Специфический звук кошки
void meow() const {
std::cout << "Кошка мяукает.\n";
}
};
int main() {
Dog myDog;
Cat myCat;
myDog.move(); // Животное двигается.
myDog.bark(); // Собака лает.
myDog.fetchStick(); // Собака приносит палку.
myCat.move(); // Животное двигается.
myCat.meow(); // Кошка мяукает.
return 0;
}
Дополнительные задания:
- Добавьте класс
Bird, который наследует классAnimal, и добавьте для него методfly(), который будет выводить сообщение о полете птицы. - Реализуйте методы для типичных действий животных в базовом классе
Animal, такие какeat()илиsleep(), и добавьте для каждого наследника специфические действия (например, кошка охотится). - Добавьте проверку состояния животного (например, усталость или голод), чтобы некоторые действия (например, движение или игра) могли быть недоступны, если животное устало или голодно.
3. Полиморфизм
Теоретическая справка:
Полиморфизм — это способность объектов разного типа реагировать на вызов одного и того же метода по-разному. В C++ полиморфизм достигается с помощью указателей на базовый класс и виртуальных методов. Это позволяет работать с разными типами объектов через единый интерфейс, не заботясь о конкретной реализации.
В С++ полиморфизм реализуется при помощи двух ключевых слов:
virtual— используется для указания того, что метод в базовом классе может быть переопределён в производных классах.override— применяется в производных классах для явного указания того, что метод переопределяет метод базового класса. Это помогает избежать ошибок, если метод базового класса не является виртуальным или если в сигнатуре метода допущена ошибка.
Синтаксис:
Пример полиморфизма с использованием виртуальных методов:
class Animal {
public:
virtual void sound() {
std::cout << "Animal makes a sound" << std::endl;
}
};
class Dog : public Animal {
public:
void sound() override {
std::cout << "Dog barks" << std::endl;
}
};
class Cat : public Animal {
public:
void sound() override {
std::cout << "Cat meows" << std::endl;
}
};
int main() {
Animal* animal1 = new Dog();
Animal* animal2 = new Cat();
animal1->sound(); // Вызывает метод Dog::sound()
animal2->sound(); // Вызывает метод Cat::sound()
delete animal1;
delete animal2;
return 0;
}
В этом примере базовый класс Animal имеет виртуальный метод sound, который переопределяется в классах-наследниках Dog и Cat. При вызове метода через указатель на базовый класс вызывается метод конкретного объекта.
Для чего используется:
- Унификация интерфейса: Полиморфизм позволяет создавать системы, где объекты разных типов могут использоваться через общий интерфейс. В системе обработки данных разных типов отчетов (финансовые, аналитические) можно использовать общий интерфейс
Report, с помощью которого можно обрабатывать все отчеты, не заботясь о конкретной реализации. - Упрощение поддержки и расширяемости: Полиморфизм позволяет легко добавлять новые классы без изменения существующего кода. В системе управления персоналом можно добавить новый класс
Intern, унаследованный отEmployee, с переопределением методов расчета заработной платы или рабочего времени.
Когда лучше избегать:
- Сложность понимания: Если слишком активно использовать полиморфизм, код может стать сложным для понимания, особенно для новых разработчиков. В системе управления заказами чрезмерное использование полиморфизма для разных типов продуктов может затруднить понимание и сопровождение кода.
- Неоправданная сложность: В проектах с четко определенными типами объектов может не требоваться полиморфизм. В небольшом приложении для учета задач полиморфизм может быть излишним, если все задачи имеют одну и ту же структуру и функционал.
Задача: Полиморфизм для геометрических фигур
Создайте базовый класс Shape с виртуальным методом getArea(). Далее создайте два производных класса: Circle и Rectangle, которые будут реализовывать метод getArea() для вычисления площади. Ваша задача — создать массив фигур и вычислить их площади через указатель на базовый класс.
Пример работы программы:
Входные данные:
- Создание объектов
Circleс радиусом 5 иRectangleс размерами 4x6. - Вычисление и вывод площади для каждой фигуры.
Выходные данные:
Площадь круга: 78.54 кв. ед.
Площадь прямоугольника: 24 кв. ед.
Вариант реализации основных требований:
#include <iostream>
#include <cmath>
// Базовый класс Shape
class Shape {
public:
// Виртуальный метод для вычисления площади
virtual double getArea() const = 0; // Чисто виртуальная функция
// Виртуальный деструктор
virtual ~Shape() {}
};
// Класс Circle (Круг), наследник Shape
class Circle : public Shape {
private:
double radius; // Радиус круга
public:
// Конструктор для инициализации радиуса
Circle(double r) : radius(r) {}
// Переопределение метода getArea() для вычисления площади круга
double getArea() const override {
return M_PI * radius * radius;
}
};
// Класс Rectangle (Прямоугольник), наследник Shape
class Rectangle : public Shape {
private:
double width, height; // Ширина и высота прямоугольника
public:
// Конструктор для инициализации ширины и высоты
Rectangle(double w, double h) : width(w), height(h) {}
// Переопределение метода getArea() для вычисления площади прямоугольника
double getArea() const override {
return width * height;
}
};
int main() {
Shape* shapes[2];
shapes[0] = new Circle(5); // Круг с радиусом 5
shapes[1] = new Rectangle(4, 6); // Прямоугольник с размерами 4x6
for (int i = 0; i < 2; ++i) {
std::cout << "Площадь фигуры: " << shapes[i]->getArea() << " кв. ед.\n";
}
for (int i = 0; i < 2; ++i) {
delete shapes[i]; // Вызов виртуального деструктора
}
return 0;
}
Дополнительные задания:
- Добавьте метод для вычисления периметра в каждом классе.
- Реализуйте класс для треугольника и добавьте его в массив фигур.
- Добавьте метод для вычисления и сравнения площадей между фигурами (например, сравнение площади круга и прямоугольника).
4. Различия между ООП и процедурным подходом
Теоретическая справка:
Одна из ключевых особенностей ООП — это способность легко масштабировать и поддерживать код, особенно в сложных системах. В процедурном подходе функции часто изолированы, что может приводить к дублированию кода и затруднению расширения системы. ООП, напротив, позволяет создавать гибкие и расширяемые системы благодаря использованию наследования, полиморфизма и инкапсуляции.
Задача: Система управления транспортными средствами
Создайте две версии программы для управления транспортными средствами:
- Процедурный подход: создайте функции для управления машиной и велосипедом, которые выполняют действия, такие как движение и заправка.
Пример решения задачи с использованием процедурного подхода
#include <iostream>
// Процедура для управления машиной
void driveCar(double& fuel, double distance) {
double fuelConsumptionPerKm = 0.1;
double requiredFuel = distance * fuelConsumptionPerKm;
if (fuel >= requiredFuel) {
fuel -= requiredFuel;
std::cout << "Машина проехала " << distance << " км. Осталось топлива: " << fuel << " л.\n";
} else {
std::cout << "Недостаточно топлива для поездки на " << distance << " км.\n";
}
}
// Процедура для заправки машины
void refuelCar(double& fuel, double amount) {
fuel += amount;
std::cout << "Машина заправлена на " << amount << " л. Осталось топлива: " << fuel << " л.\n";
}
// Процедура для управления велосипедом
void rideBicycle(double distance) {
std::cout << "Велосипед проехал " << distance << " км.\n";
}
int main() {
double carFuel = 5.0;
driveCar(carFuel, 50); // Машина двигается на 50 км
refuelCar(carFuel, 10); // Машина заправляется на 10 л топлива
rideBicycle(20); // Велосипед двигается на 20 км
return 0;
}
- ООП подход: создайте базовый класс
Vehicleс общими методами и классы-наследникиCarиBicycleс их специфическими методами.
Пример решения задачи с использованием ООП подхода
#include <iostream>
// Базовый класс для транспортных средств
class Vehicle {
public:
virtual void move(double distance) const = 0;
virtual ~Vehicle() {}
};
// Класс Car (Машина), наследует класс Vehicle
class Car : public Vehicle {
private:
double fuel; // Текущий уровень топлива
double fuelConsumptionPerKm; // Расход топлива на 1 км
public:
// Конструктор для инициализации машины
Car(double initialFuel) : fuel(initialFuel), fuelConsumptionPerKm(0.1) {}
// Метод для движения
void move(double distance) const override {
double requiredFuel = distance * fuelConsumptionPerKm;
if (fuel >= requiredFuel) {
std::cout << "Машина проехала " << distance << " км. Осталось топлива: " << fuel - requiredFuel << " л.\n";
} else {
std::cout << "Недостаточно топлива для поездки на " << distance << " км.\n";
}
}
// Метод для заправки машины
void refuel(double amount) {
fuel += amount;
std::cout << "Машина заправлена на " << amount << " л. Осталось топлива: " << fuel << " л.\n";
}
// Деструктор
~Car() override = default;
};
// Класс Bicycle (Велосипед), наследует класс Vehicle
class Bicycle : public Vehicle {
public:
// Метод для движения велосипеда
void move(double distance) const override {
std::cout << "Велосипед проехал " << distance << " км.\n";
}
};
int main() {
Car myCar(5);
myCar.move(50);
myCar.refuel(10);
Bicycle myBicycle;
myBicycle.move(20);
return 0;
}
Пример работы программы:
Входные данные:
- Машина двигается на 50 км, велосипед на 20 км.
- Машина заправляется на 10 литров топлива.
Выходные данные:
Машина проехала 50 км. Осталось топлива: 5 л.
Машина заправлена на 10 л. Осталось топлива: 15 л.
Велосипед проехал 20 км.
Дополнительные задания:
- В ООП версии добавьте новый вид транспорта (например, мотоцикл) и продемонстрируйте, как легко его интегрировать в систему.
- Добавьте возможность учета пройденного времени для каждого типа транспорта.
- Попробуйте внести аналогичные изменения в процедурный подход, проанализируйте насколько это было удобнее / сложнее, чем с использованием ООП.
5. Перегрузка функций и операторов
Теоретическая справка:
Перегрузка функций позволяет определять несколько функций с одинаковыми именами, но с разными типами или количеством параметров. Это полезно, когда одна и та же операция может выполняться над разными типами данных, что улучшает читаемость и удобство использования кода.
Перегрузка операторов позволяет изменять поведение стандартных операторов (например, +, -, *, ==) для пользовательских типов данных (классов). Это полезно, когда вы хотите, чтобы стандартные операторы могли работать с вашими объектами, например, для арифметических операций или сравнения объектов.
Синтаксис:
Пример перегрузки функции:
class MathOperation {
public:
int add(int a, int b) {
return a + b;
}
double add(double a, double b) {
return a + b;
}
int add(int a, int b, int c) {
return a + b + c;
}
};
int main() {
MathOperation math;
int sum1 = math.add(3, 4); // Перегрузка для целых чисел
double sum2 = math.add(2.5, 3.5); // Перегрузка для вещественных чисел
int sum3 = math.add(1, 2, 3); // Перегрузка для трех аргументов
return 0;
}
Пример перегрузки оператора:
class ComplexNumber {
private:
double real, imag;
public:
ComplexNumber(double r = 0, double i = 0) : real(r), imag(i) {}
// Перегрузка оператора +
ComplexNumber operator+(const ComplexNumber& other) {
return ComplexNumber(real + other.real, imag + other.imag);
}
void display() {
std::cout << real << " + " << imag << "i" << std::endl;
}
};
int main() {
ComplexNumber num1(3.0, 4.0), num2(1.0, 2.0);
ComplexNumber sum = num1 + num2; // Использование перегруженного оператора +
sum.display(); // Вывод: 4.0 + 6.0i
return 0;
}
В этом примере перегружается оператор +, чтобы его можно было использовать для сложения комплексных чисел.
Для чего используются:
- Обеспечение удобного интерфейса для пользователя: Перегрузка функций позволяет пользователям кода вызывать одну и ту же функцию для разных типов данных, что делает API более интуитивным. Пример: В системе управления учебными курсами перегруженная функция может использоваться для обработки различных типов данных студента (целочисленные идентификаторы, строки с именем и фамилией).
- Работа с пользовательскими типами данных: Перегрузка операторов позволяет пользователям определять естественное поведение операторов для объектов. Пример: В системе учета финансов перегруженный оператор
+может использоваться для сложения объектов классаMoney, который содержит информацию о валюте и сумме.
Когда лучше избегать:
- Чрезмерное использование перегрузки: Если перегружать слишком много операторов или функций, это может запутать пользователей кода и привести к сложностям в его понимании. Пример: В приложении для управления инвентарем слишком частое использование перегрузки операторов может привести к путанице, так как пользователи могут не понимать, как операторы работают с объектами инвентаря.
- Сложность отладки: Перегрузка операторов может затруднить отладку программы, так как она изменяет стандартное поведение операторов. Пример: В системе для управления проектами перегрузка операторов сравнения (
==или<) может привести к непредсказуемым результатам, если не реализована корректно.
Задача: Перегрузка операторов для работы с комплексными числами
Необходимо создать класс Complex, который будет представлять комплексные числа. Класс должен содержать:
- Приватные члены: действительная и мнимая часть числа.
- Публичные методы для получения и изменения частей комплексного числа.
- Перегруженные операторы:
+для сложения двух комплексных чисел.-для вычитания.==для сравнения двух комплексных чисел.<<для вывода комплексного числа.
Пример работы программы:
Входные данные:
- Создание двух комплексных чисел
3 + 4iи1 + 2i. - Сложение и вычитание этих чисел.
- Сравнение двух чисел.
Выходные данные:
Первое число: 3 + 4i
Второе число: 1 + 2i
Результат сложения: 4 + 6i
Результат вычитания: 2 + 2i
Вариант реализации основных требований:
#include <iostream>
class Complex {
private:
double real; // Действительная часть
double imag; // Мнимая часть
public:
Complex(double r = 0.0, double i = 0.0) : real(r), imag(i) {}
// Метод для получения действительной части
double getReal() const {
return real;
}
// Метод для получения мнимой части
double getImag() const {
return imag;
}
// Метод для изменения действительной части
void setReal(double r) {
real = r;
}
// Метод для изменения мнимой части
void setImag(double i) {
imag = i;
}
// Перегрузка оператора + для сложения двух комплексных чисел
Complex operator+(const Complex& other) const {
return Complex(real + other.real, imag + other.imag);
}
// Перегрузка оператора - для вычитания двух комплексных чисел
Complex operator-(const Complex& other) const {
return Complex(real - other.real, imag - other.imag);
}
// Перегрузка оператора == для сравнения двух комплексных чисел
bool operator==(const Complex& other) const {
return (real == other.real) && (imag == other.imag);
}
// Перегрузка оператора << для вывода комплексного числа
friend std::ostream& operator<<(std::ostream& out, const Complex& c) {
out << c.real;
if (c.imag >= 0) {
out << " + " << c.imag << "i";
} else {
out << " - " << -c.imag << "i";
}
return out;
}
};
int main() {
Complex num1(3, 4);
Complex num2(1, 2);
std::cout << "Первое число: " << num1 << "\n";
std::cout << "Второе число: " << num2 << "\n";
Complex sum = num1 + num2;
std::cout << "Результат сложения: " << sum << "\n";
Complex difference = num1 - num2;
std::cout << "Результат вычитания: " << difference << "\n";
if (num1 == num2) {
std::cout << "Числа равны.\n";
} else {
std::cout << "Числа не равны.\n";
}
return 0;
}
Дополнительные задания:
- Реализуйте перегрузку оператора
*для умножения комплексных чисел. - Добавьте оператор
!=для проверки неравенства. - Реализуйте оператор
[], который позволяет обращаться к действительной и мнимой частям числа по индексу (например,c[0]для действительной иc[1]для мнимой).
6. Шаблоны (Templates)
Теоретическая справка:
Шаблоны позволяют создавать функции и классы, которые могут работать с различными типами данных, не переписывая код для каждого типа. Это особенно полезно для создания универсальных функций и классов, которые могут обрабатывать любые типы данных, поддерживающие операции, используемые в этих функциях.
Синтаксис:
Пример работы шаблона на функции:
template <typename T>
T add(T a, T b) {
return a + b;
}
int main() {
int resultInt = add(3, 4); // Работает с целыми числами
double resultDouble = add(3.5, 2.1); // Работает с числами с плавающей запятой
return 0;
}
Этот шаблон функции позволяет складывать значения разных типов (например, целые числа и числа с плавающей запятой) без необходимости писать отдельную функцию для каждого типа.
Шаблоны также могут применяться к классам. Рассмотрим пример класса Vector, который может работать с различными типами данных:
template <typename T>
class Vector {
private:
T* data;
int size;
public:
Vector(int s) : size(s) {
data = new T[size];
}
void setData(int index, T value) {
if (index >= 0 && index < size) {
data[index] = value;
}
}
T getData(int index) {
if (index >= 0 && index < size) {
return data[index];
}
return T(); // Возвращаем значение по умолчанию для типа T
}
~Vector() {
delete[] data;
}
};
int main() {
Vector<int> intVector(5);
intVector.setData(0, 10);
Vector<double> doubleVector(3);
doubleVector.setData(1, 5.5);
return 0;
}
Шаблонный класс Vector может работать с различными типами данных, такими как целые числа и числа с плавающей запятой, что позволяет значительно упростить код и сделать его универсальным.
Для чего используются:
- Универсальные контейнеры данных: Шаблонные классы, такие как
Vector, можно использовать в небольших модулях для хранения и обработки данных (например, идентификаторы студентов или их оценки). - Гибкость с разными типами данных: В модуле вычислений шаблонные функции могут выполнять операции с различными типами данных (например, целые числа, вещественные числа, комплексные числа).
- Повторное использование кода: Шаблоны позволяют создавать универсальные структуры данных (например, списки, очереди), что предотвращает дублирование кода.
Когда лучше избегать:
- Переусложнение для конкретных задач: В модуле с четко определенными типами данных использование шаблонов может быть излишним. Конкретные типы данных проще использовать для решения задач.
- Сложность отладки: В приложениях, где используются разные типы данных (например, обработка изображений), отладка шаблонов может усложниться из-за неочевидных ошибок.
- Усложнение поддержки: Если использовать шаблоны для всех операций в одном модуле, это может усложнить поддержку кода, так как разработчики должны понимать взаимодействие шаблонов с разными типами данных.
Задача: Шаблон класса для работы с парой данных
Создайте шаблон класса Pair, который может хранить два объекта любого типа и предоставлять методы для доступа к этим объектам. Класс должен содержать:
- Приватные члены для хранения пары данных.
- Публичные методы для доступа к первому и второму элементам.
- Метод для сравнения двух объектов
Pair(пара считается равной, если оба элемента равны).
Пример работы программы:
Входные данные:
- Создание пары целых чисел (5, 10).
- Создание пары строк ("Привет", "Мир").
- Сравнение двух пар целых чисел.
Выходные данные:
Первая пара: 5, 10
Вторая пара: Привет, Мир
Пары равны: Нет
Вариант реализации основных требований:
#include <iostream>
#include <string>
// Шаблонный класс Pair для работы с двумя объектами любого типа
template <typename T1, typename T2>
class Pair {
private:
// Приватные члены для хранения двух объектов
T1 first;
T2 second;
public:
Pair(T1 firstValue, T2 secondValue) : first(firstValue), second(secondValue) {}
T1 getFirst() const {
return first;
}
T2 getSecond() const {
return second;
}
// Метод для сравнения двух пар
bool isEqual(const Pair<T1, T2>& other) const {
return (first == other.first && second == other.second);
}
friend std::ostream& operator<<(std::ostream& os, const Pair<T1, T2>& pair) {
os << pair.first << ", " << pair.second;
return os;
}
};
int main() {
// Создание пары целых чисел
Pair<int, int> intPair(5, 10);
std::cout << "Первая пара: " << intPair << std::endl;
// Создание пары строк
Pair<std::string, std::string> stringPair("Привет", "Мир");
std::cout << "Вторая пара: " << stringPair << std::endl;
// Сравнение двух пар целых чисел
Pair<int, int> anotherIntPair(5, 10);
bool areEqual = intPair.isEqual(anotherIntPair);
std::cout << "Пары равны: " << (areEqual ? "Да" : "Нет") << std::endl;
return 0;
}
Дополнительные задания:
- Реализуйте шаблон для сравнения пар разного типа (например, пара целых чисел и пара с плавающей точкой).
- Добавьте возможность работы с шаблоном для трех элементов (например,
Triplet). - Реализуйте шаблонный метод для вывода данных пары через перегрузку оператора
<<.
7. Статические члены класса
Теоретическая справка:
Статические члены класса принадлежат самому классу, а не конкретному объекту. Статическая переменная является общей для всех объектов класса и хранит одно значение для всех экземпляров. Статические методы могут работать только со статическими данными и могут быть вызваны без создания объекта класса. Также можно сделать статическим целый класс, при этом конструктор удаляется, а создание экземпляра происходит через статический метод.
Пример:
class Example {
public:
static int staticVar;
static void staticMethod() {
std::cout << "This is a static method!" << std::endl;
}
};
int Example::staticVar = 0;
int main() {
// Вызов статического метода
Example::staticMethod();
// Доступ к статической переменной
std::cout << "Static variable: " << Example::staticVar << std::endl;
return 0;
}
Для создания статического класса и управления его экземпляром, можно использовать следующий подход:
class Singleton {
private:
static Singleton* instance;
// Закрытый конструктор
Singleton() {}
public:
// Статический метод для получения экземпляра класса
static Singleton* getInstance() {
if (!instance)
instance = new Singleton();
return instance;
}
};
Singleton* Singleton::instance = nullptr;
Для чего используются:
-
Хранение общего состояния для всех экземпляров класса. Например, в информационной системе для управления пользователями статическая переменная может использоваться для хранения текущего количества активных пользователей системы. Все экземпляры объектов пользователей будут иметь доступ к этому числу, и любое изменение числа будет сразу отображено для всех объектов.
-
Оптимизация использования ресурсов. Например, CRM-системе статическая переменная может использоваться для хранения данных конфигурации подключения к базе данных. Эти данные не нужно дублировать для каждого экземпляра соединения, и они будут экономно расходовать память.
-
Удобство в утилитарных функциях. Например, статические методы могут использоваться для валидации данных в системе электронного документооборота (СЭД). Например, метод для проверки формата email можно реализовать как статический метод, который вызывается без создания экземпляра класса пользователя.
Когда лучше избегать:
-
Сложность тестирования. Например, в системе отчетности использование статических методов для обработки данных может осложнить тестирование, так как они сохраняют общее состояние для всех тестов. Это может привести к некорректным результатам, если один тест изменит состояние, которое повлияет на другой.
-
Нарушение принципа инкапсуляции. Например, в банковской системе использование статических переменных для хранения конфиденциальной информации (например, процентных ставок или лимитов по кредитам) может быть опасным, так как к ним могут получить доступ любые классы, что нарушает инкапсуляцию и делает данные уязвимыми.
Задача: Учет количества сотрудников в компании
Необходимо создать класс Employee, который будет хранить информацию о сотрудниках компании и вести статистику общего количества сотрудников. При каждом создании объекта-сотрудника счетчик должен увеличиваться. Класс должен включать статическую переменную для хранения количества сотрудников и статический метод для его вывода.
Класс должен содержать:
- Приватные члены: имя сотрудника и идентификационный номер (ID).
- Статический счетчик для подсчета сотрудников.
- Статический метод для вывода общего количества сотрудников.
- Конструктор, который увеличивает счетчик и присваивает сотруднику уникальный ID.
Пример работы программы:
Входные данные:
- Создание трех сотрудников с именами "Иван", "Мария" и "Алексей".
Выходные данные:
Сотрудник Иван, ID: 1
Сотрудник Мария, ID: 2
Сотрудник Алексей, ID: 3
Общее количество сотрудников: 3
Вариант реализации основных требований:
#include <iostream>
#include <string>
class Employee {
private:
std::string name;
int id;
// Статический счетчик для подсчета сотрудников
static int employeeCount;
public:
Employee(const std::string& employeeName) : name(employeeName) {
employeeCount++;
id = employeeCount;
}
void displayInfo() const {
std::cout << "Сотрудник " << name << ", ID: " << id << std::endl;
}
// Статический метод для вывода общего количества сотрудников
static void showEmployeeCount() {
std::cout << "Общее количество сотрудников: " << employeeCount << std::endl;
}
};
// Инициализация статической переменной
int Employee::employeeCount = 0;
int main() {
Employee emp1("Иван");
Employee emp2("Мария");
Employee emp3("Алексей");
emp1.displayInfo();
emp2.displayInfo();
emp3.displayInfo();
Employee::showEmployeeCount();
return 0;
}
Дополнительные задания:
- Реализуйте возможность удаления сотрудника. Не забудьте уменьшить общий счетчик сотрудников.
- Добавьте статический метод для вывода списка всех сотрудников.
- Добавьте методы для изменения данных сотрудника (например, изменение имени), чтобы проверить, как это влияет на работу статических методов.
8. Дружественные классы и функции
Теоретическая справка:
Дружественные классы и функции позволяют одному классу или функции получать доступ к приватным и защищённым членам другого класса, что в обычных условиях недоступно вне класса. При использовании этого механизма, класс или функция получает "особые права" на доступ к приватным и защищённым данным другого класса, сохраняя при этом инкапсуляцию.
Использование дружественных классов и функций полезно в тех случаях, когда требуется тесное взаимодействие между двумя классами, или когда функция должна работать с данными нескольких классов и ей необходимо более глубокое взаимодействие с их внутренней структурой.
Синтаксис:
Чтобы сделать функцию дружественной классу, необходимо объявить её с ключевым словом friend внутри класса. Пример синтаксиса:
class ClassName {
private:
int privateData;
public:
// Дружественная функция имеет доступ к приватным членам этого класса
friend void friendFunction(ClassName& obj);
};
// Определение дружественной функции
void friendFunction(ClassName& obj) {
// Функция имеет доступ к приватным членам класса
std::cout << "Private data: " << obj.privateData << std::endl;
}
Дружественные классы определяются с использованием ключевого слова friend перед именем дружественного класса в определении исходного класса:
class ClassA {
private:
int privateDataA;
// Класс ClassB является дружественным и имеет доступ ко всем приватным членам
friend class ClassB;
};
class ClassB {
public:
void accessClassA(ClassA& obj) {
// ClassB может получить доступ к приватным членам ClassA
std::cout << "Private data from ClassA: " << obj.privateDataA << std::endl;
}
};
В этом примере класс ClassB может получить доступ к приватным данным класса ClassA напрямую, так как объявлен дружественным.
Зачем нужны дружественные функции и классы?
Для чего используются:
-
Инкапсуляция сохраняется. Например, В системе управления складом можно использовать дружественные классы для обеспечения тесного взаимодействия между классом управления товаром и классом управления партией товара. Дружественные функции могут позволить одному классу получить доступ к детальной информации о партии, не раскрывая эти данные внешним системам.
-
Безопасность. Например, В системе безопасности данные о правах доступа могут быть закрыты для всех классов, кроме дружественного класса, который отвечает за проверку прав. Это позволяет сохранить конфиденциальность и защиту данных от прямого изменения.
-
Альтернатива геттерам. Например, в системе учета сотрудников можно реализовать дружественную функцию для класса зарплаты, которая позволяет классу отчетности получать доступ к данным о зарплате сотрудников напрямую, без необходимости использования большого количества геттеров.
Когда лучше избегать:
-
Чрезмерная связанность.. Например, в системе бронирования авиабилетов использование дружественных классов для тесной связи между классами билетов и пассажиров может привести к сложному коду, который трудно сопровождать, особенно если потребуется добавить новые виды билетов или изменить структуру данных пассажиров.
-
Нарушение SRP (Принципа единственной ответственности).. Например, в системе управления проектами, если дружественная функция, связанная с классом задач, будет брать на себя обязанности управления проектом, это может привести к нарушению SRP, так как задачи и проекты будут слишком сильно связаны между собой, усложняя их поддержку и расширяемость.
Задача: Модель взаимодействия между классами "Компания" и "Сотрудник"
Создайте два класса: Company и Employee. Класс Company должен управлять сотрудниками, а класс Employee должен содержать информацию о сотрудниках. Класс Company должен быть дружественным к классу Employee, чтобы иметь возможность добавлять и удалять сотрудников.
Класс Employee содержит:
- Приватные данные: имя и ID сотрудника.
- Конструктор для создания сотрудника.
- Метод для вывода информации о сотруднике.
Класс Company включает:
- Приватные данные: массив сотрудников (или вектор).
- Дружественные функции для добавления и удаления сотрудников.
Пример работы программы:
Входные данные:
- Создание объекта компании.
- Добавление двух сотрудников.
- Вывод списка сотрудников.
Выходные данные:
Сотрудник Иван, ID: 1
Сотрудник Мария, ID: 2
Общее количество сотрудников: 2
Вариант реализации основных требований:
#include <iostream>
#include <vector>
#include <string>
class Employee {
private:
std::string name;
int id;
static int employeeCount;
public:
Employee(const std::string& employeeName) : name(employeeName) {
employeeCount++;
id = employeeCount;
}
void displayInfo() const {
std::cout << "Сотрудник " << name << ", ID: " << id << std::endl;
}
static int getEmployeeCount() {
return employeeCount;
}
// Делаем класс Company дружественным, чтобы он имел доступ к приватным членам Employee
friend class Company;
};
// Инициализация статической переменной
int Employee::employeeCount = 0;
// Класс Company для управления сотрудниками
class Company {
private:
std::vector<Employee> employees;
public:
void addEmployee(const std::string& employeeName) {
Employee newEmployee(employeeName);
employees.push_back(newEmployee);
}
void removeLastEmployee() {
if (!employees.empty()) {
employees.pop_back();
}
}
void listEmployees() const {
for (const auto& employee : employees) {
employee.displayInfo();
}
}
void showEmployeeCount() const {
std::cout << "Общее количество сотрудников: " << Employee::getEmployeeCount() << std::endl;
}
};
int main() {
Company myCompany;
myCompany.addEmployee("Иван");
myCompany.addEmployee("Мария");
myCompany.listEmployees();
myCompany.showEmployeeCount();
return 0;
}
Дополнительные задания:
- Реализуйте возможность поиска сотрудника по имени или ID.
- Добавьте метод для изменения данных сотрудника через класс
Company(например, изменение имени). - Реализуйте дружественные функции для вывода всех сотрудников компании.
Контрольное задание: Магазин с товарами, клиентами и покупками
Это контрольное задание включает все изученные в ходе блока темы, такие как инкапсуляция, наследование, полиморфизм, статические члены класса, дружественные классы и функции, перегрузка операторов, а также шаблоны. Ваша задача — создать расширенную модель магазина с клиентами, товарами и покупками, которая будет использовать все ключевые концепции ООП.
Задача: Разработка модели магазина
Необходимо создать систему, моделирующую работу магазина с клиентами и товарами. Ваша система должна включать следующие элементы:
- Класс
Productдля хранения информации о товаре:- Приватные данные: название товара, цена, количество на складе.
- Публичные методы для изменения количества и получения информации о товаре.
- Перегрузите оператор
==для сравнения товаров.
- Класс
Customerдля хранения информации о клиентах:- Приватные данные: имя клиента, баланс счета.
- Публичные методы для пополнения счета и покупки товара.
- Дружественная функция для доступа к данным клиента из класса магазина.
- Класс
Storeдля управления покупками и товарами:- Приватные данные: список товаров и клиентов.
- Статический счетчик для учета количества товаров в магазине.
- Публичные методы для добавления товаров, покупки товаров клиентами.
- Шаблонный метод для возврата списка товаров или клиентов.
Пример работы программы:
Входные данные:
- Добавление товаров в магазин: "Хлеб", "Молоко", "Мясо".
- Создание клиента с балансом 1000 рублей.
- Покупка товара клиентом.
Выходные данные:
Товар: Хлеб, Цена: 50 руб., Остаток: 98 шт.
Товар: Молоко, Цена: 60 руб., Остаток: 97 шт.
Клиент Иван Иванов: Баланс: 940 руб.
Дополнительные задания:
- Реализуйте шаблонный метод для возврата информации как о товарах, так и о клиентах (например, метод, который принимает тип объекта и возвращает соответствующую информацию).
- Реализуйте перегрузку оператора
+=для увеличения количества товара на складе и оператора-=для уменьшения. - Добавьте шаблонный класс для управления учетными записями сотрудников магазина, который включает информацию о сотрудниках и позволяет управлять их статусом и зарплатой.
Применение ООП в практическом решении задач
Для выполнения заданий выберите вариант решения в зависимости от номера вашей зачетной книжки. Решайте вариант по формуле: Номер варианта = (Номер зачетной книжки mod 3) + 1
Задание 1: Система поиска по документам и файлам
Описание предметной области:
Вам необходимо разработать систему поиска документов и файлов, которая может работать с различными типами документов (текстовые файлы, PDF, изображения, видео, аудиофайлы). Программа должна поддерживать фильтрацию по различным критериям, таким как тип файла, размер, дата создания и последние изменения.
Задание:
- Реализуйте базовый класс
File, который будет содержать основные поля, такие как имя файла, дата создания, размер и путь к файлу (локальный). Реализуйте методopen(), который будет выводить сообщение о попытке открытия файла. - Создайте производные классы для различных типов файлов:
TextDocumentдля текстовых документов.PDFDocumentдля PDF файлов.ImageFileдля изображений.VideoFileдля видеофайлов.AudioFileдля аудиофайлов.
- Реализуйте методы поиска с возможностью фильтрации по имени, типу, размеру, дате создания и изменения.
- Реализуйте методы для имитации предварительного просмотра изображений и видео, а также воспроизведения аудиофайлов (вывод сообщений об этих действиях).
- Реализуйте возможность тегирования файлов и поиска по тегам.
- Система должна поддерживать сортировку результатов по различным параметрам (имя файла, дата создания, размер).
Доп. функции:
- Добавьте систему архивации файлов. Создайте возможность перемещать файлы в архив и выводить их в поисковых результатах отдельно.
- Реализуйте систему отчётов, которая выводит статистику по найденным файлам (количество файлов, средний размер, последние изменения).
- Создайте возможность удаления файлов с подтверждением в консоли.
Входные данные для тестирования:
Информация о файлах может быть введена с клавиатуры или считана из текстового файла. Пример ввода данных с клавиатуры:
Введите информацию о файлах (формат: имя файла, дата создания, размер, теги):
1. Report.pdf, 10.05.2023, 200 KB, [work, project]
2. Image.jpg, 15.11.2022, 1.5 MB, [vacation, family]
3. Notes.txt, 01.01.2021, 50 KB, [work, personal]
4. Video.mp4, 20.02.2020, 500 MB, []
5. Podcast.mp3, 05.04.2021, 100 MB, []
Или можно прочитать из текстового документа:
Report.pdf, 10.05.2023, 200 KB, [work, project]
Image.jpg, 15.11.2022, 1.5 MB, [vacation, family]
Notes.txt, 01.01.2021, 50 KB, [work, personal]
Video.mp4, 20.02.2020, 500 MB, []
Podcast.mp3, 05.04.2021, 100 MB, []
Запрос поиска: тип файла - "PDF", теги - "work", сортировка - по дате создания.
Выходные данные:
Результаты поиска (сортировка по дате создания):
1. Report.pdf (10.05.2023, 200 KB, Local, Теги: [work, project])
Открытие файла: Report.pdf
Файл Report.pdf открыт для редактирования.
Задание 2: Система бронирования отелей
Описание предметной области:
Вам необходимо разработать масштабируемую систему управления бронированием отелей, которая поддерживает не только бронирование стандартных номеров (одноместные, двухместные и люксы), но и управление дополнительными услугами (например, завтрак, обед, экскурсии), а также управление скидками для постоянных клиентов. Система должна поддерживать динамическое изменение цен в зависимости от спроса и загруженности отелей. Клиенты могут получать скидки за накопленные бонусные баллы, которые они накапливают за каждое бронирование. Также система должна поддерживать групповые бронирования с расчетом специальных условий для групп.
Программа будет полностью консольной, и все действия по бронированию, расчету скидок и услуг будут выполняться через ввод данных в консоли.
Задание:
- Реализуйте базовый класс
Booking, который будет содержать информацию о бронировании (номер комнаты, тип комнаты, количество ночей, базовая цена). Создайте методы для расчета стоимости бронирования с учетом дополнительных услуг и динамического изменения цен в зависимости от загруженности отеля. - Создайте производные классы для различных типов номеров:
SingleRoomдля одноместных номеров.DoubleRoomдля двухместных номеров.Suiteдля люксов.
- Реализуйте систему управления скидками и бонусами для постоянных клиентов. Создайте систему накопления баллов, которые можно использовать для получения скидок.
- Реализуйте систему динамического изменения цен в зависимости от загруженности отелей.
- Поддержите групповые бронирования с расчетом скидок и спецпредложений для групп.
Доп. функции:
- Реализуйте систему управления сетью отелей, где каждый отель имеет свои цены и дополнительные услуги.
- Реализуйте систему отчётов, которая выводит информацию о загрузке отелей, количестве бронирований и использовании дополнительных услуг за определенный период времени.
Входные данные для тестирования:
Доступные номера:
1. Номер 101 - Single Room - 1000 руб/ночь
2. Номер 102 - Double Room - 1500 руб/ночь
3. Номер 201 - Suite - 3000 руб/ночь
Бонусы клиента:
Постоянный клиент, накоплено 300 баллов (5% скидка).
Запросы на бронирование:
1. Номер 102, 3 ночи, завтрак, клиент - постоянный.
2. Номер 101, групповое бронирование (2 номера), 2 ночи, обед.
Текущая загруженность отеля: 85%
Выходные данные:
Номер 102 (Double Room)
Количество ночей: 3
Дополнительные услуги: завтрак
Общая стоимость: 6500 руб (с учетом скидки)
Номер 101 (Single Room) - Групповое бронирование
Количество номеров: 2
Количество ночей: 2
Дополнительные услуги: обед
Общая стоимость: 3800 руб за номер (с учетом скидок)
Статус номеров: заняты
Паттерны проектирования
MVC (Model-View-Controller)
MVC (Model-View-Controller) — это архитектурный паттерн, который разделяет приложение на три основных компонента:
- Model (Модель): Отвечает за управление данными и бизнес-логику приложения. Модель не зависит от пользовательского интерфейса и может быть использована в различных контекстах.
- View (Вид): Отображает данные пользователю и предоставляет интерфейс для взаимодействия. Вид отвечает только за отображение данных и не содержит бизнес-логики.
- Controller (Контроллер): Обрабатывает пользовательский ввод, взаимодействует с Моделью и обновляет Вид. Контроллер служит посредником между Моделью и Видом, управляя потоком данных и обработкой событий.
Преимущества использования MVC:
- Разделение ответственности: Каждый компонент имеет четко определенную роль, что упрощает разработку и поддержку кода.
- Масштабируемость: Приложение легко расширять, так как изменения в одном компоненте не затрагивают другие.
- Тестируемость: Модель и контроллер могут быть протестированы независимо от вида, что упрощает написание модульных тестов.
- Повторное использование кода: Модель и контроллер могут быть использованы в различных видах, что повышает эффективность разработки.
Пример:
Разработать программу для управления каталогом товаров. Приложение должно позволять добавлять, удалять и просматривать товары.
#include <iostream>
#include <vector>
#include <string>
// Модель
class Product {
public:
std::string name;
double price;
int quantity;
Product(std::string n, double p, int q) : name(n), price(p), quantity(q) {}
};
class CatalogModel {
public:
void addProduct(const Product& product) {
m_products.push_back(product);
}
void removeProduct(int index) {
if (index >= 0 && index < m_products.size()) {
m_products.erase(m_products.begin() + index);
}
}
const std::vector<Product>& getProducts() const {
return m_products;
}
private:
std::vector<Product> m_products;
};
// Вид
class CatalogView {
public:
void displayProducts(const std::vector<Product>& products) {
for (size_t i = 0; i < products.size(); ++i) {
std::cout << i << ". " << products[i].name << " - $" << products[i].price
<< " - " << products[i].quantity << " шт." << std::endl;
}
}
void displayMenu() {
std::cout << "1. Добавить товар" << std::endl;
std::cout << "2. Удалить товар" << std::endl;
std::cout << "3. Показать товары" << std::endl;
std::cout << "4. Выход" << std::endl;
}
};
// Контроллер
class CatalogController {
public:
CatalogController(CatalogModel& model, CatalogView& view) : m_model(model), m_view(view) {}
void run() {
int choice;
do {
m_view.displayMenu();
std::cin >> choice;
switch (choice) {
case 1:
addProduct();
break;
case 2:
removeProduct();
break;
case 3:
m_view.displayProducts(m_model.getProducts());
break;
case 4:
std::cout << "Выход..." << std::endl;
break;
default:
std::cout << "Неверный выбор. Попробуйте снова." << std::endl;
}
} while (choice != 4);
}
private:
void addProduct() {
std::string name;
double price;
int quantity;
std::cout << "Введите название товара: ";
std::cin >> name;
std::cout << "Введите цену товара: ";
std::cin >> price;
std::cout << "Введите количество товара: ";
std::cin >> quantity;
m_model.addProduct(Product(name, price, quantity));
}
void removeProduct() {
int index;
std::cout << "Введите номер товара для удаления: ";
std::cin >> index;
m_model.removeProduct(index);
}
CatalogModel& m_model;
CatalogView& m_view;
};
int main() {
CatalogModel model;
CatalogView view;
CatalogController controller(model, view);
controller.run();
return 0;
}
MVC в Qt
Qt — это мощная кроссплатформенная библиотека для разработки приложений с графическим интерфейсом. Руководство по ее установке есть в нашем курсе. В Qt паттерн MVC можно организовать следующим образом:
- Model: Используется класс QAbstractItemModel или его подклассы (например, QStandardItemModel, QSqlTableModel). Модель предоставляет данные для отображения и управления ими.
- View: Используется класс QAbstractItemView или его подклассы (например, QListView, QTableView, QTreeView). Вид отображает данные, предоставленные моделью.
- Controller: В Qt контроллер часто объединен с виджетами, которые обрабатывают пользовательский ввод (например, кнопки, поля ввода). Контроллер взаимодействует с моделью и обновляет вид в зависимости от действий пользователя.
Ознакомиться с другими примерами можно в следующих проектах:
Задача: To-Do List
Описание предметной области:
Вам необходимо разработать масштабируемую систему управления списком задач (ToDo List), которая позволяет пользователям добавлять, удалять, отмечать как выполненные и просматривать задачи. Система должна поддерживать различные категории задач, приоритеты и сроки выполнения. Пользователи могут фильтровать задачи по категориям, приоритетам и статусу выполнения.
- Модель (Model):
- Реализуйте класс Task, который будет содержать информацию о задаче (название, описание, категория, приоритет, статус выполнения, срок выполнения).
- Создайте класс ToDoModel, который будет управлять списком задач. Предоставьте методы для добавления, удаления, изменения статуса выполнения и получения списка задач.
- Вид (View):
- Отображайте меню пользователю с возможными действиями (добавить задачу, удалить задачу, отметить задачу как выполненную, показать все задачи).
- Отображайте список задач с их атрибутами.
- Контроллер (Controller):
- Обрабатывайте пользовательский ввод.
- Взаимодействуйте с Моделью для выполнения действий (добавление, удаление, изменение статуса).
- Обновляйте Вид в зависимости от результатов действий.
Для реализации доступно два варианта: простой консольный и графический при помощи Qt, за второй будут дополнительные баллы. Вместе с Qt можно использовать Qml.
Доп. функции:
- Реализуйте возможность экспорта списка задач в файл (например, в формате CSV или JSON).
Factory Method (Фабричный метод)
Паттерн Фабричный Метод определяет интерфейс создания объекта, но позволяет субклассам выбрать класс создаваемого экемпляра. Таким образом, Фабричный Метод делегирует операцию создания экземпляра субклассам.
Когда стоит использовать?
Представьте, что вы разрабатываете систему логистики, в которой задействованы разные типы транспорта, например, грузовики и корабли. Добавление нового типа транспорта (например, самолетов) требует изменения существующего кода, что может привести к ошибкам. Паттерн Factory Method помогает решить эту проблему, инкапсулируя логику создания объектов внутри подклассов.
Компоненты
- Продукт (Product): Определяет общий интерфейс для всех создаваемых объектов.
- Конкретный продукт (Concrete Product): Реализует интерфейс продукта.
- Создатель (Creator): Определяет фабричный метод, который возвращает объекты продукта.
- Конкретный создатель (Concrete Creator): Реализует фабричный метод, создавая определённый тип продукта.
Пример:
Рассмотрим пример с системой доставки.
#include <iostream>
#include <memory>
#include <string>
// Продукт
class Transport {
public:
virtual ~Transport() = default;
virtual void deliver() const = 0;
};
// Конкретные продукты
class Truck : public Transport {
public:
void deliver() const override {
std::cout << "Доставка по суше грузовиком." << std::endl;
}
};
class Ship : public Transport {
public:
void deliver() const override {
std::cout << "Доставка по морю кораблем." << std::endl;
}
};
// Создатель
class Logistics {
public:
virtual ~Logistics() = default;
virtual std::unique_ptr<Transport> createTransport() const = 0;
void planDelivery() const {
auto transport = createTransport();
transport->deliver();
}
};
// Конкретные создатели
class RoadLogistics : public Logistics {
public:
std::unique_ptr<Transport> createTransport() const override {
return std::make_unique<Truck>();
}
};
class SeaLogistics : public Logistics {
public:
std::unique_ptr<Transport> createTransport() const override {
return std::make_unique<Ship>();
}
};
// Клиентский код
int main() {
std::unique_ptr<Logistics> logistics = std::make_unique<RoadLogistics>();
logistics->planDelivery();
logistics = std::make_unique<SeaLogistics>();
logistics->planDelivery();
return 0;
}
Преимущества и недостатки
Преимущества:
- Инкапсуляция: Логика создания объектов скрыта от клиентского кода.
- Масштабируемость: Легко добавить новый тип продукта, создав новый подкласс.
- Гибкость: Позволяет переключаться между разными типами объектов в зависимости от контекста.
Недостатки:
- Сложность: Введение дополнительного уровня абстракции может усложнить архитектуру.
- Множество подклассов: При добавлении большого числа продуктов требуется создавать множество новых классов.
Применение на практике
Если ваша система нуждается в создании объектов с общим интерфейсом, но с различным поведением, Factory Method станет полезным инструментом. Например:
- Логистика: Доставка грузов с использованием разных видов транспорта.
- Игры: Создание разных типов врагов в зависимости от уровня.
- Документы: Генерация отчетов в различных форматах (PDF, Word).
Задание: Система управления парком транспортных средств
Описание предметной области:
Вам необходимо разработать систему, которая поддерживает управление различными типами транспортных средств (например, грузовики, корабли, самолеты). Система должна позволять планировать доставку с использованием выбранного типа транспорта. Каждое транспортное средство должно иметь свои особенности, такие как способ доставки, стоимость доставки и ограничения по грузу. Система должна быть масштабируемой, чтобы в будущем можно было добавлять новые виды транспорта (например, дроны).
Задание:
- Реализуйте базовый класс
Transport, который содержит информацию о транспортном средстве (например, название, максимальная грузоподъемность).- Определите метод
deliver, который будет переопределяться в конкретных классах.
- Определите метод
- Создайте производные классы для конкретных видов транспорта:
Truckдля грузовиков (доставка по суше).Shipдля кораблей (доставка по морю).Planeдля самолетов (доставка по воздуху).
- Реализуйте базовый класс
Logisticsс фабричным методом для создания транспортных средств.- Определите метод
createTransport, который будет реализован в подклассах.
- Определите метод
- Создайте конкретные классы логистики:
RoadLogisticsдля грузовиков.SeaLogisticsдля кораблей.AirLogisticsдля самолетов.
- Реализуйте возможность расчета стоимости доставки на основе типа транспорта и расстояния.
Доп. функции:
- Добавьте поддержку нового типа транспорта (например, дронов) с собственными характеристиками.
- Реализуйте систему отчётов, которая выводит информацию о выполненных доставках (тип транспорта, расстояние, стоимость).
Входные данные для тестирования:
Доступные типы транспорта:
1. Грузовик (Truck) - Макс. груз: 10 тонн
2. Корабль (Ship) - Макс. груз: 100 тонн
3. Самолет (Plane) - Макс. груз: 20 тонн
Запросы на доставку:
1. Тип транспорта: Грузовик, расстояние: 300 км, груз: 5 тонн.
2. Тип транспорта: Корабль, расстояние: 1500 км, груз: 50 тонн.
3. Тип транспорта: Самолет, расстояние: 2000 км, груз: 15 тонн.
Выходные данные:
Доставка Грузовиком
Расстояние: 300 км
Груз: 5 тонн
Стоимость: 1500 руб
Доставка Кораблём
Расстояние: 1500 км
Груз: 50 тонн
Стоимость: 7500 руб
Доставка Самолётом
Расстояние: 2000 км
Груз: 15 тонн
Стоимость: 20000 руб
Отчёт о доставках:
1. Грузовик: 300 км, 5 тонн, 1500 руб
2. Корабль: 1500 км, 50 тонн, 7500 руб
3. Самолёт: 2000 км, 15 тонн, 20000 руб
Adapter (Адаптер)
Паттерн Адаптер используется для преобразования интерфейса одного класса в интерфейс, ожидаемый клиентом. Адаптер позволяет классам с несовместимыми интерфейсами работать вместе.
Когда стоит использовать?
Представьте, что у вас есть система управления платёжными сервисами. Система уже работает с одним API, но вам нужно интегрировать сторонний платёжный сервис с другим интерфейсом. Изменение существующего кода может быть сложным или нежелательным. Паттерн Adapter позволяет решить эту проблему, создавая промежуточный слой, который преобразует интерфейсы.
Компоненты
- Клиент (Client): Класс, использующий целевой интерфейс.
- Целевой интерфейс (Target): Интерфейс, ожидаемый клиентом.
- Адаптируемый класс (Adaptee): Класс с несовместимым интерфейсом, который нужно адаптировать.
- Адаптер (Adapter): Класс, который реализует целевой интерфейс и использует адаптируемый класс для выполнения своей работы.
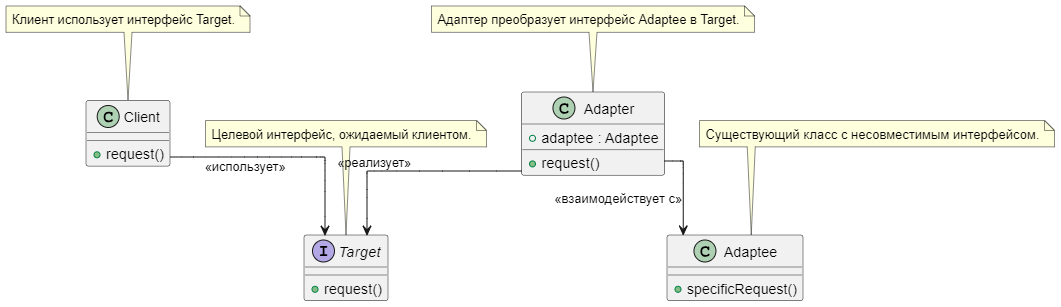
Пример
Рассмотрим пример с платёжными системами.
#include <iostream>
#include <string>
// Целевой интерфейс (Target)
class PaymentProcessor {
public:
virtual ~PaymentProcessor() = default;
virtual void processPayment(double amount) const = 0;
};
// Адаптируемый класс (Adaptee)
class OldPaymentSystem {
public:
void makeTransaction(const std::string& details) const {
std::cout << "Processing payment with details: " << details << std::endl;
}
};
// Адаптер (Adapter)
class PaymentAdapter : public PaymentProcessor {
private:
OldPaymentSystem* adaptee;
public:
PaymentAdapter(OldPaymentSystem* oldSystem) : adaptee(oldSystem) {}
void processPayment(double amount) const override {
// Преобразуем данные в формат, понятный старой системе
std::string details = "Amount: " + std::to_string(amount);
adaptee->makeTransaction(details);
}
};
// Клиент (Client)
class OnlineStore {
private:
const PaymentProcessor* paymentProcessor;
public:
OnlineStore(const PaymentProcessor* processor) : paymentProcessor(processor) {}
void checkout(double amount) const {
std::cout << "Starting payment process...\n";
paymentProcessor->processPayment(amount);
std::cout << "Payment complete.\n";
}
};
// Клиентский код
int main() {
OldPaymentSystem oldSystem;
PaymentAdapter adapter(&oldSystem);
OnlineStore store(&adapter);
store.checkout(99.99);
return 0;
}
Преимущества и недостатки
Преимущества:
- Совместимость: Позволяет использовать несовместимые классы без изменения их кода.
- Инкапсуляция: Изменения в адаптируемом классе не влияют на клиентский код.
- Гибкость: Позволяет легко подключать новые адаптируемые классы.
Недостатки:
- Сложность: Увеличивает сложность системы из-за добавления новых классов.
- Зависимость: Адаптер может стать слишком завязанным на структуру адаптируемого класса.
Применение на практике
Если ваша система работает с объектами, интерфейсы которых несовместимы, Adapter поможет их объединить. Например:
- Платёжные системы: Интеграция старого и нового API.
- Файловые системы: Работа с разными форматами файлов.
- Сетевые протоколы: Преобразование форматов данных для совместимости.
Задание: Система работы с данными GPS-устройств
Описание предметной области:
У вас есть система, которая работает с GPS-данными через современный интерфейс GeoTarget. В проекте появилась необходимость интегрировать старую библиотеку LegacyGPS, предоставляющую данные в ином формате. Необходимо разработать адаптер для взаимодействия с этой библиотекой, чтобы клиентский код не изменялся.
Инструкции:
- Создайте интерфейс
GeoTargetс методомgetCoordinates(), возвращающим координаты в формате(широта, долгота). - Реализуйте класс
LegacyGPS, который предоставляет координаты в виде строки ("lat:<широта>;lon:<долгота>"). - Создайте адаптер
GPSAdapter, который преобразует данные из форматаLegacyGPSв форматGeoTarget. - Напишите клиентский класс
GeoClient, который работает только с интерфейсомGeoTarget. - Напишите клиентский код, использующий адаптер для работы со старой библиотекой
LegacyGPS.
Входные данные для тестирования:
Данные от LegacyGPS:
"lat:59.9342802;lon:30.3350986"
Выходные данные:
Координаты:
Широта: 59.9342802
Долгота: 30.3350986
Observer (Наблюдатель)
Паттерн Наблюдатель определяет отношение "один ко многим" между объектами таким образом, что при изменении состояния одного объекта происходит автоматическое оповещение и обновление всех зависимых объектов.
Когда стоит использовать?
Представьте, что у вас есть система мониторинга, которая отслеживает состояние различных датчиков. Когда датчик изменяет свои показания, система должна уведомить все заинтересованные объекты (например, пользователей или другие системы). Вместо того чтобы напрямую обновлять каждый объект, паттерн Observer позволяет оповестить все наблюдатели о изменении.
Компоненты
- Наблюдаемый объект (Subject): Объект, за состоянием которого следят наблюдатели.
- Наблюдатель (Observer): Объект, который реагирует на изменения в наблюдаемом объекте.
- Конкретный наблюдаемый объект (ConcreteSubject): Реализация наблюдаемого объекта.
- Конкретный наблюдатель (ConcreteObserver): Реализация наблюдателя.
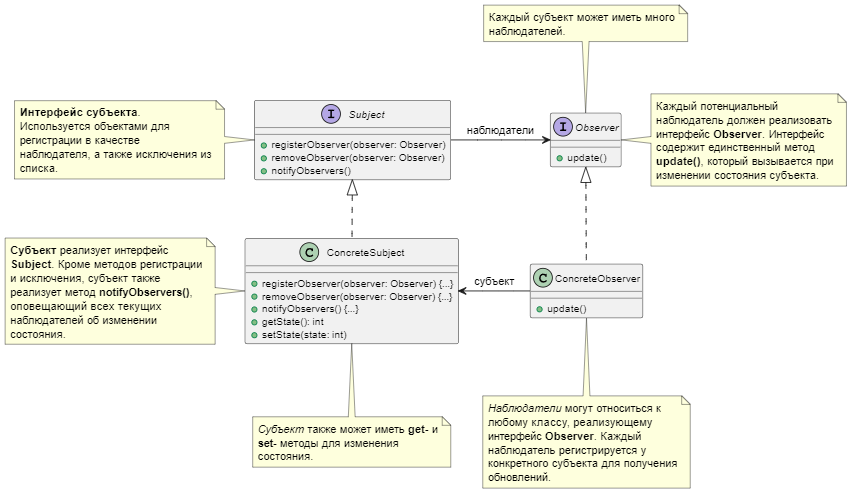
Пример
Рассмотрим пример с системой мониторинга погоды.
#include <iostream>
#include <vector>
#include <string>
// Абстрактный наблюдатель (Observer)
class Observer {
public:
virtual ~Observer() = default;
virtual void update(float temperature) = 0;
};
// Субъект (Subject)
class Subject {
public:
virtual ~Subject() = default;
virtual void addObserver(Observer* observer) = 0;
virtual void removeObserver(Observer* observer) = 0;
virtual void notifyObservers() = 0;
};
// Конкретный субъект (ConcreteSubject)
class WeatherStation : public Subject {
private:
std::vector<Observer*> observers;
float temperature;
public:
WeatherStation() : temperature(0.0f) {}
void setTemperature(float temp) {
temperature = temp;
notifyObservers();
}
float getTemperature() const {
return temperature;
}
void addObserver(Observer* observer) override {
observers.push_back(observer);
}
void removeObserver(Observer* observer) override {
observers.erase(std::remove(observers.begin(), observers.end(), observer), observers.end());
}
void notifyObservers() override {
for (Observer* observer : observers) {
observer->update(temperature);
}
}
};
// Конкретный наблюдатель (ConcreteObserver)
class DisplayUnit : public Observer {
private:
std::string name;
public:
DisplayUnit(const std::string& unitName) : name(unitName) {}
void update(float temperature) override {
std::cout << name << " received temperature update: " << temperature << "°C\n";
}
};
// Клиентский код
int main() {
WeatherStation weatherStation;
DisplayUnit display1("Display 1");
DisplayUnit display2("Display 2");
weatherStation.addObserver(&display1);
weatherStation.addObserver(&display2);
weatherStation.setTemperature(25.0f); // Обновление температуры
weatherStation.removeObserver(&display2);
weatherStation.setTemperature(30.0f); // Обновление температуры
return 0;
}
Преимущества и недостатки
Преимущества:
- Декуплирование: Наблюдатели и субъекты не зависят друг от друга напрямую, что упрощает расширение системы.
- Гибкость: Легко добавлять новых наблюдателей без изменения кода субъекта.
- Автоматическое обновление: Все наблюдатели получают уведомления о изменениях состояния без явного запроса.
Недостатки:
- Производительность: Если наблюдателей много, обновления могут повлиять на производительность.
- Сложность управления: В сложных системах может быть трудно отслеживать все взаимодействия между субъектами и наблюдателями.
Применение на практике
Паттерн Observer полезен, когда:
- Необходимо уведомлять несколько объектов о изменениях состояния одного объекта.
- Система имеет динамическое добавление/удаление компонентов, которые должны быть уведомлены.
- Например:
- Системы мониторинга: Обновления данных о погоде, изменениях состояния оборудования.
- UI-системы: Интерфейсы, где несколько элементов могут изменяться на основе одного состояния (например, изменение данных, отображаемых в нескольких местах).
- Системы событий: Регистрация и уведомление об изменениях в системе.
Задание: Система уведомлений о новых сообщениях
Описание предметной области:
У вас есть система уведомлений, которая сообщает пользователям о новых сообщениях в чате. Когда новое сообщение появляется в чате, все подписанные пользователи должны получить уведомление. Для реализации этой системы нужно использовать паттерн Наблюдатель.
Инструкции:
- Создайте абстрактный класс
Observerс методомupdate(), который будет получать уведомления о новых сообщениях. - Реализуйте класс
Subjectдля управления списком пользователей, которые подписаны на уведомления. - Создайте класс
ChatRoom, который будет наследоватьSubjectи реализовывать логику отправки уведомлений всем подписанным пользователям о новых сообщениях. - Реализуйте класс
User, который будет наследоватьObserverи отображать полученные сообщения. - Напишите код, который будет добавлять пользователей в чат и отправлять новое сообщение, чтобы все подписанные пользователи получили уведомления.
Входные данные для тестирования:
Пользователь "Alice" подписан на уведомления.
Пользователь "Bob" подписан на уведомления.
Новое сообщение: "Привет, мир!"
Пользователь "Alice" получил новое сообщение: Привет, мир!
Пользователь "Bob" получил новое сообщение: Привет, мир!
Проверка усвоенного материала
Всего вариантов задания: 5. Ваш номер варианта определяется по формуле: номер зачетки % 5 + 1.
Каждый из вариантов может быть реализован в простом (консольном) варианте, и усложненном - графическом. За второй можно получить существенно больше баллов и при условии закрытых предыдущих заданий предетендовать на автомат.
При выполнении всех заданий необходимо придерживаться архитектуры MVC.
Вариант 1: Система выбора категорий кэшбеков
Описание задачи: Система автоматически выбирает наиболее выгодную стратегию для выбора категорий кэшбека, предложенных различными банками на начало каждого месяца. Каждый банк может предложить несколько категорий с различными процентами кэшбека, а пользователь может выбрать только определенное количество категорий. Система должна учитывать предпочтения пользователя (например, всегда получать максимальный кэшбек по категории "продукты").
Основные компоненты:
- Категории кэшбеков: Каждая категория должна иметь наименование, процент кэшбека и возможность для пользователя задать приоритеты.
- Банки: Каждому банку могут быть присвоены определенные категории, которые он предлагает на текущий месяц.
- Предпочтения пользователя: Пользователь может установить, какие категории ему наиболее важны (например, "продукты").
- Алгоритм выбора: На основе предложенных категорий и пользовательских предпочтений, программа должна выбрать наиболее выгодные категории с учетом ограничений на количество выбранных.
- Экспорт/считывание данных: Возможность загрузки данных о банках и категориях из файлов и сохранения результатов выбора в файл для будущего использования.
Требования к паттернам:
- Использование паттерна Стратегия для алгоритма выбора категории с кэшбеком.
Вариант 2: Система составления расписания исходя из приоритетов
Описание задачи: Система создает расписание на неделю, с учетом заранее известных мероприятий (например, пары в университете, деловые встречи) и задач, которые нужно выполнить, но которые не имеют четких временных рамок. Каждому мероприятию или задаче можно присвоить приоритет, и система должна запланировать их таким образом, чтобы более важные задачи занимали место в расписании раньше менее важных.
Основные компоненты:
- Мероприятия: обязательные (например, пары в университете) с фиксированным заренее известным временем.
- Задачи: с неопределенным временем (например, рабочие задачи).
- Приоритеты: каждому мероприятию или задаче присваивается приоритет от 1 до 10.
- Рабочие часы: система учитывает рабочие часы пользователя.
- Алгоритм составления расписания: программа должна автоматически запланировать задачи с более высоким приоритетом.
- Экспорт/считывание данных: возможность сохранять расписания и данные о задачах в файл и загружать их для дальнейшего использования.
Требования к паттернам:
- Использование паттерна Стратегия для алгоритма планирования задач.
Вариант 3: Программа по учету прочитанной литературы и генерации рекомендаций
Описание задачи: Система учета прочитанной литературы, которая позволяет пользователю вводить книги с различными параметрами (название, категория, оценка, статус) и на основе этих данных предлагает новые книги для прочтения. Для предложения рекомендаций используется метод вычисления векторного расстояния между книгами, что позволяет находить книги, схожие по жанрам, авторам или предпочтениям пользователя.
Основные компоненты:
- Книги: Каждая книга имеет набор характеристик:
- Название, категория, оценка, автор, дата прочтения, сложность и т.д.
- Рекомендации: Программа должна предложить новые книги на основе анализа предыдущих прочитанных книг.
- Используются алгоритмы: Косинусное сходство, Евклидово расстояние, Метод ближайших соседей.
- Экспорт/считывание данных: Поддержка загрузки базы данных книг из файла (например, JSON, CSV, SQLite).
Требования к паттернам:
- Использование паттерна Фабричный метод для создания объектов книги.
Вариант 4: Система мониторинга и оповещений о статусе заказов с паттерном Наблюдатель
Описание задачи: Система для интернет-магазина отслеживает изменения статуса заказов и отправляет уведомления клиентам и менеджерам о каждом обновлении. Система поддерживает динамическое добавление подписчиков (клиентов, менеджеров) на уведомления по статусам заказов и обеспечивает обработку разных типов уведомлений в зависимости от ролей подписчиков.
Основные компоненты:
- Заказы: Каждый заказ имеет уникальный идентификатор и текущий статус (например, "в обработке", "отправлен", "доставлен").
- Пользователи: Пользователи могут подписываться на уведомления о статусах заказов. У пользователей есть роли (например, "клиент", "менеджер"), и уведомления для разных ролей могут быть разными по содержанию.
- Оповещения: Когда статус заказа меняется, система должна отправить уведомления всем подписанным пользователям. Уведомления для клиентов содержат минимальную информацию, а для менеджеров — более полную.
- Подписка на уведомления: Пользователи могут подписываться на уведомления для конкретных заказов или для всех заказов с фильтрацией по статусам.
- История уведомлений: Система должна хранить историю отправленных уведомлений для каждого заказа.
Требования к паттернам:
- Паттерн Наблюдатель: Для реализации системы оповещений, где заказ является субъектом, а пользователи — наблюдателями.
- Паттерн Фабрика: Для создания различных типов уведомлений в зависимости от роли пользователя (клиент, менеджер).
Вариант 5: Система интеграции данных о продуктах из локальных модулей с паттерном Адаптер
Описание задачи: Разработать систему, которая объединяет данные о продуктах из нескольких локальных модулей (файлов или внутренних источников), каждый из которых предоставляет данные в своем формате. Система должна преобразовывать данные из разных форматов в унифицированную структуру для дальнейшей обработки. Используемые модули эмулируют независимые источники данных с различными форматами, предоставляя информацию о продуктах.
Основные компоненты:
- Продукты: Каждый продукт имеет следующие характеристики:
- Название (
name) - Категория (
category) - Цена (
price) - Описание (
description) - Наличие на складе (
in_stock)
- Название (
- Модули данных:
- Модуль A возвращает данные в формате массива строк, где каждая строка представляет продукт, разделенный точкой с запятой (
;). - Модуль B предоставляет данные в формате словаря, где ключи и значения полей отличаются от целевого формата.
- Модуль C возвращает данные в формате списка объектов, где некоторые поля содержат дополнительные вложенные структуры.
- Модуль A возвращает данные в формате массива строк, где каждая строка представляет продукт, разделенный точкой с запятой (
- Единый формат данных: Все данные должны быть приведены к следующему унифицированному формату:
- Названия полей:
name,category,price,description,in_stock. - Цена должна быть представлена в виде десятичного числа.
- Наличие на складе должно быть булевым значением (
trueилиfalse).
- Названия полей:
Необходимо учесть:
- Проверка корректности данных:
- Уведомление о пропущенных или некорректных полях (например, отсутствие цены).
- Пометка строк с ошибками для дальнейшего анализа.
- Фильтрация данных: Возможность фильтрации продуктов по категории или наличию на складе.
- Объединение данных: После загрузки данных из всех модулей система должна объединить их в единый набор для вывода.
Требования к паттернам:
- Паттерн Адаптер: Для преобразования данных из различных модулей в унифицированный формат.
Ссылка на файл с лабораторными работами.
Общие требования к сдаче лабораторных работ:
- Среда разработки: Для выполнения всех лабораторных работ используем Visual Studio. Версию можно выбрать на свое усмотрение, но рекомендуется скачать актуальную версию с официального сайта.
- Единое решение (Solution): Для всех лабораторных работ создаем единый файл решения (sln). В этом файле каждый новый проект должен соответствовать отдельной лабораторной работе.
- Загрузка на GitHub: Полную директорию с файлом решения и всеми проектами необходимо загрузить на GitHub. Убедитесь, что все файлы и зависимости корректно загружены. Обновляем новыми лабораторками по мере их выполнения.
Ознакомиться с инструкцией по настройке SSH ключей для Github'a можно здесь.
Лабораторная работа: Реализация симплекс метода
Прочитать про разбор симплекс-метода можно здесь.
Обшие требования как к обычному, так и к усложненному варианту:
- Входные данные:
- Целевая функция.
- Система линейных ограничений.
- Обязательно должна присутствовать провера на корректность ввода и вывод сообщения для пользователя в случае невозможности решения задачи.
- Для реализации можно использовать следующие ЯП: JS, TS, C#, C++, Java, VBA.
- В программе должен быть предусмотрен блок тестов для автоматической проверки на типичных задачах. Для проверки собственной программы можно использовать онлайн калькулятор. В нижней части страницы с калькулятором присутствует общий алгоритм решения задач ЛП симплекс-методом.
- Должен быть обеспечен удобный ввод и вывод данных.
Простой вариант: Базовый симплекс метод
Ограничения
Решение задач линейного программирования (ЛП) с использованием симплекс метода. Условия:
- Ограничения могут быть только вида "≤".
- Все переменные неотрицательны.
- Целевая функция стремится к максимуму.
Пример задачи
Максимизировать: \[ Z = 2x_1 + 3x_2 \] при условиях: \[ x_1 + 2x_2 \leq 8 \] \[ 2x_1 + x_2 \leq 6 \] \[ x_1, x_2 \geq 0 \]
С примером и разбором решения задачи базовым симплекс-методом можно ознакомиться по ссылке.
Интерфейс
При решении базового (канонического) варианта допускается наличие только консольного интерфейса, однако он должен быть выполнен на должном уровне, обеспечивая ввод и вывод данных в удобном и понятном для пользователя формате. С примером можно ознакомиться на изображении ниже.
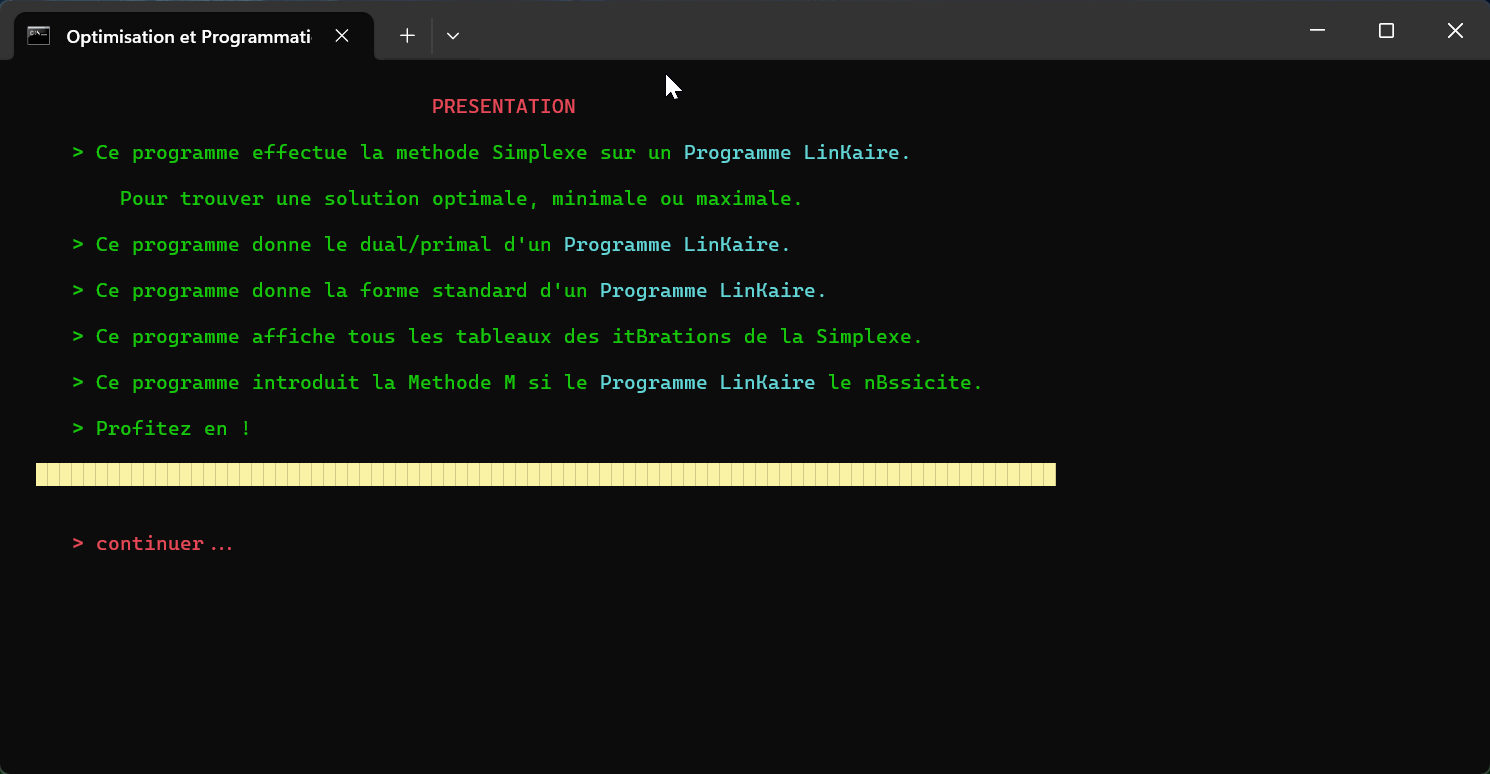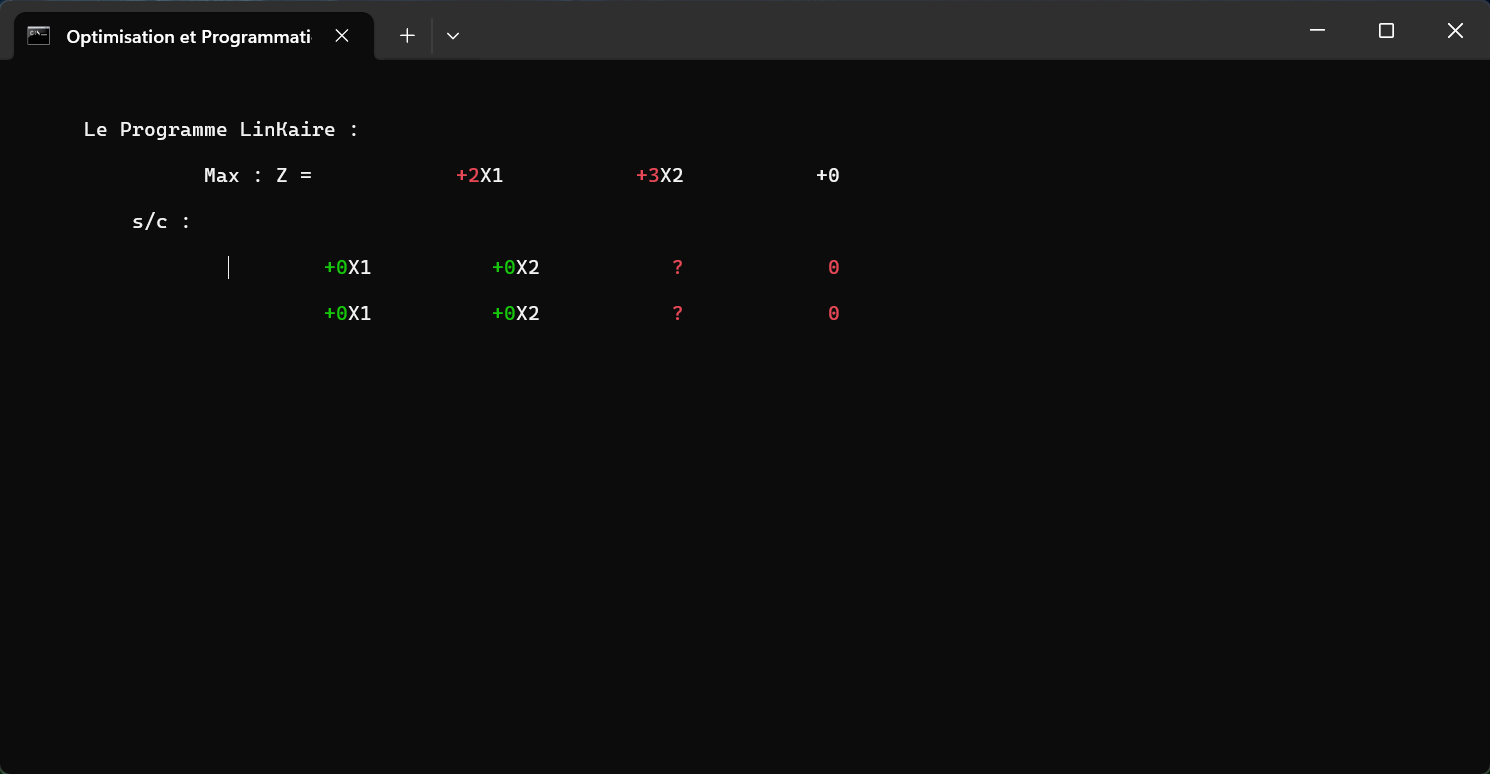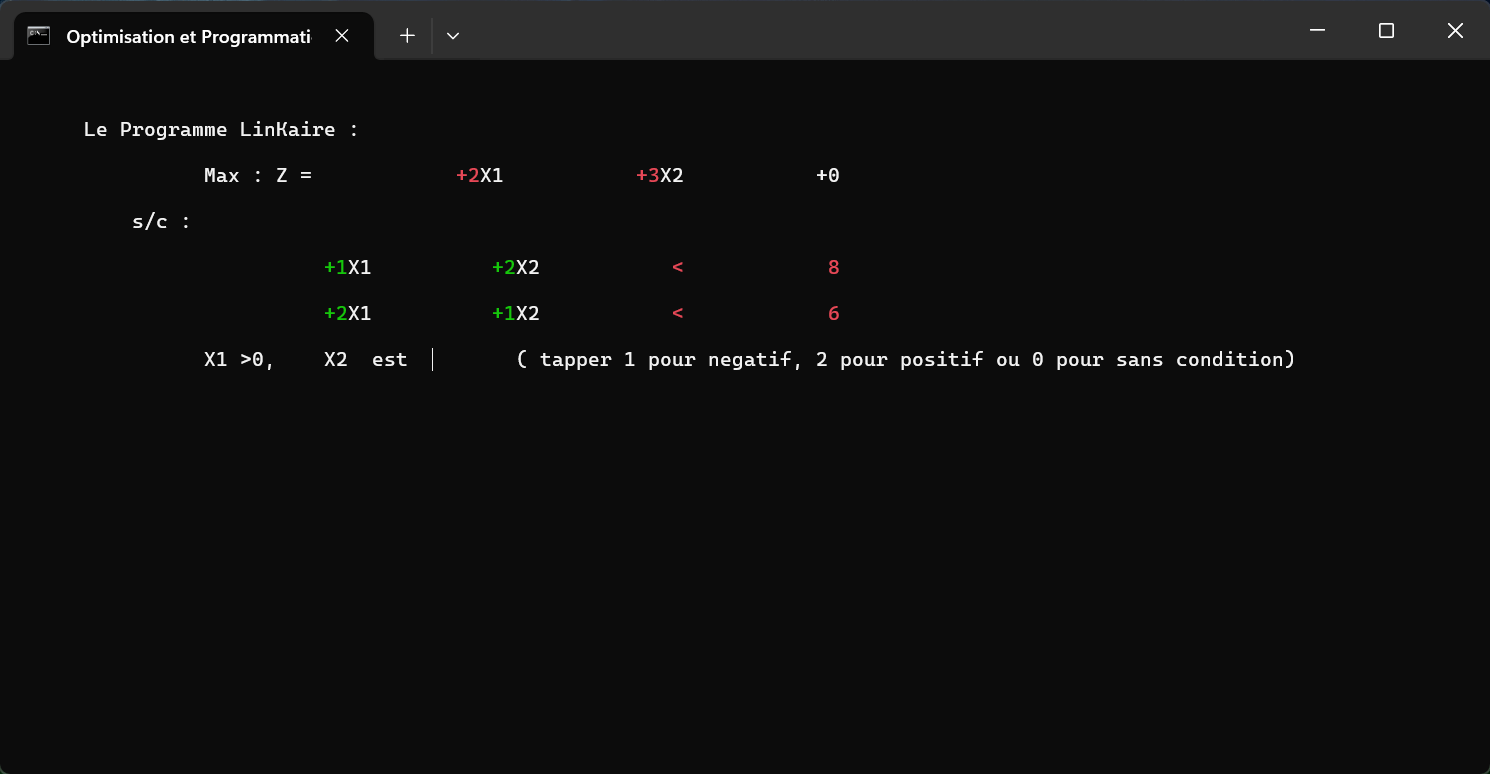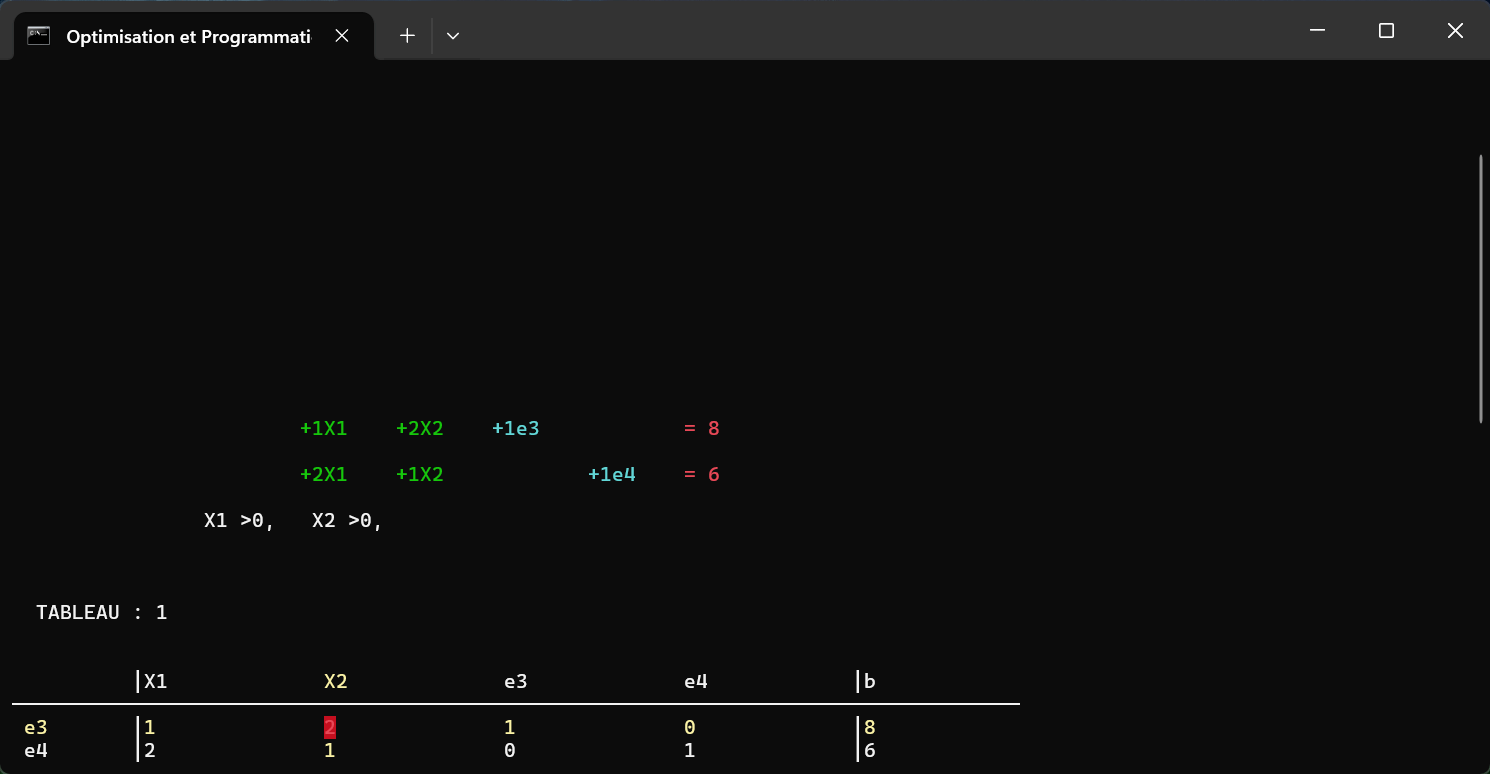
Усложненный вариант: Двойственный симплекс метод
Ограничения
Этот вариант предполагает решение более сложных задач с использованием двойственного симплекс метода. Условия:
- Задачи могут быть как на максимизацию так и на минимизацию.
- Допускаются различные типы ограничений: "≤", "≥", "=".
- Переменные могут быть как положительными, так и отрицательными.
Требования к решению
- Обязательно должен быть реализован GUI.
Пример задачи
Минимизировать: \[ Z = 4x_1 + 6x_2 + 3x_3 \] при условиях: \[ x_1 + 2x_2 - x_3 \geq 5 \] \[ 3x_1 + 2x_2 + x_3 = 8 \] \[ x_1 \geq 0, \quad x_2 \leq 0, \quad x_3 \geq 0 \]
С примером и разбором решения задачи двосйственным симплекс-методом можно ознакомиться по ссылке.
Интерфейс
Для сдачи усложненного (двойственного) симплекс-метода необходимо наличие GUI. Выбор за вами, но графический интерфейс проще будет сделать в вебе. После этого соотвественно либо пишете бек на JS, либо добавляете в схему сервер, на который будете отправлять считанные данные, и используете любой из разрешенных ЯП для решения задачи на серверной стороне.
Техническое задание (ТЗ): Программа мониторинга состояния ПК/сервера с интерфейсом
Описание задачи:
Необходимо разработать программу для мониторинга состояния ПК или сервера. Программа должна выводить следующие характеристики:
1. Аппаратная часть:
-
Процессор (CPU):
- Модель и количество ядер.
- Частота работы.
-
Оперативная память (RAM):
- Общий объём.
- Используемый объём.
- Свободный объём.
-
Жесткий диск (HDD/SSD):
- Общий объём диска.
- Используемое пространство.
- Свободное пространство.
-
Графический процессор (GPU) (если не встройка):
- Модель и основные характеристики.
2. Мониторинг системы:
-
Нагрузка на процессор:
- Текущая загрузка CPU в процентах.
-
Использование оперативной памяти:
- Объём использованной и свободной памяти RAM.
-
Использование диска (HDD/SSD):
- Занятое и свободное место на диске.
-
Список всех запущенных процессов с возможностью:
- Сортировки по объёму потребляемой оперативной памяти.
- Сортировки по загрузке процессора.
- Поиска по названию процесса.
3. Настройки программы:
- Возможность включения/отключения логирования выбранных ключевых показателей. В настройках можно выбрать, какие метрики логировать (например, нагрузку на CPU, использование RAM и т.д.).
Дополнительные требования:
- Реализовать проверку состояния SMART для HDD/SSD. SMART (Self-Monitoring, Analysis, and Reporting Technology) предоставляет информацию о состоянии накопителя и предсказывает возможные отказы. Основные показатели SMART включают:
- Температура диска.
- Количество переназначенных секторов.
- Время работы диска.
- Ошибки чтения/записи.
Ограничения:
- Запрещено использование скриптовых языков программирования (например, Python, AWK, Bash, PowerShell и других).
- Используемые библиотеки должны быть компилируемыми (например, на C, C++, Rust).
Крайне желательно: В интерфейсе программы должна присутствовать главная страница с Dashboard'ом с возможностью настройки отображаемых метрик. Визуализация должна быть реализована в виде графиков, диаграмм и текстовых полей, напоминающих Grafana.
Лабораторная работа: Логгер
Ознакомиться с ТЗ можно по ссылке.
Создание REST API
Что такое REST API?
REST (Representational State Transfer) — архитектурный стиль для создания распределенных приложений, который основан на использовании стандартных HTTP-методов для взаимодействия с ресурсами, представленных в виде данных. RESTful API предоставляет механизм обмена данными между клиентом и сервером.
Основные принципы REST:
- Безсессионность (Stateless): каждый запрос клиента к серверу должен содержать всю информацию, необходимую для его обработки (не сохраняется состояние между запросами).
- Использование стандартных HTTP-методов: для операций с ресурсами используются стандартные HTTP методы:
- GET — для получения данных.
- POST — для создания новых данных.
- PUT — для обновления существующих данных.
- DELETE — для удаления данных.
- Единообразие интерфейса: API должно иметь понятный и стандартизированный интерфейс, например, использовать правильные HTTP-коды для различных ситуаций (например, 200 — успех, 400 — ошибка запроса, 404 — не найдено).
Ознакомиться с полным списком актуальных HTTP кодов и их значения можно по ссылке
Пример запроса и ответа:
В большинстве случаев Rest API в качестве ответа предоставляют информацию в формате JSON.
Запрос:
GET /api/items HTTP/1.1
Host: example.com
Ответ:
[
{
"id": 1,
"name": "Item 1",
"description": "Description of Item 1"
},
{
"id": 2,
"name": "Item 2",
"description": "Description of Item 2"
}
]
Настройка сервера и подготовка к установке
Установка WSL и настройка окружения
Для использования NGINX на Windows лучше всего установить WSL, который позволяет работать с Linux-утилитами прямо на Windows.
Установка WSL: Откройте PowerShell и выполните команду:
wsl --install
Перезагрузите систему и установите Ubuntu через Microsoft Store.
Установка NGINX на WSL:
sudo apt update
sudo apt install nginx
sudo service nginx start
Установка PostgreSQL
В терминале Ubuntu установите PostgreSQL:
sudo apt update
sudo apt install postgresql postgresql-contrib
sudo service postgresql start
Создайте базу данных и пользователя:
- Войдите в PostgreSQL:
sudo -u postgres psql - Выполните команду для создания базы данных и пользователя:
CREATE DATABASE mydb; CREATE USER myuser WITH PASSWORD 'mypassword'; GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
Создайте таблицу для хранения данных:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
description TEXT
);
Установка Node.js и npm
Node.js — это среда выполнения JavaScript вне браузера, которая позволяет создавать серверные приложения. npm (Node Package Manager) — это менеджер пакетов для Node.js, который используется для установки различных библиотек и инструментов. Чтобы установить Node.js и npm, выполните следующие шаги:
-
Откройте терминал Ubuntu в WSL и обновите список пакетов:
sudo apt update -
Установите Node.js и npm:
sudo apt install nodejs npm -
Проверьте, что установка прошла успешно:
node -v npm -v
Эти команды должны вывести установленные версии Node.js и npm.
Создание REST API с использованием Node.js и Express
Инициализация проекта
Создайте новый проект:
mkdir {название_проекта}
cd {название_проекта}
npm init -y
Установите зависимости:
npm install express pg
Структура проекта
Создайте структуру проекта с использованием принципов MVC (Model-View-Controller):
{название_проекта}/
├── controllers/
│ └── itemsController.js
├── models/
│ └── itemModel.js
├── routes/
│ └── itemsRoutes.js
├── server.js
└── config/
└── db.js
Конфигурация подключения к базе данных
Создайте файл config/db.js:
const { Client } = require('pg');
const client = new Client({
user: 'myuser',
host: 'localhost',
database: 'mydb',
password: 'mypassword',
port: 5432,
});
client.connect();
module.exports = client;
Создание модели
В файле models/itemModel.js:
const db = require('../config/db');
const getAllItems = async () => {
const result = await db.query('SELECT * FROM items');
return result.rows;
};
const addItem = async (name, description) => {
const result = await db.query(
'INSERT INTO items (name, description) VALUES ($1, $2) RETURNING *',
[name, description]
);
return result.rows[0];
};
module.exports = { getAllItems, addItem };
Создание контроллеров
В файле controllers/itemsController.js:
const itemModel = require('../models/itemModel');
const getItems = async (req, res) => {
try {
const items = await itemModel.getAllItems();
res.status(200).json(items);
} catch (error) {
res.status(500).json({ message: 'Server Error' });
}
};
const createItem = async (req, res) => {
const { name, description } = req.body;
try {
const newItem = await itemModel.addItem(name, description);
res.status(201).json(newItem);
} catch (error) {
res.status(500).json({ message: 'Server Error' });
}
};
module.exports = { getItems, createItem };
Создание маршрутов
В файле routes/itemsRoutes.js:
const express = require('express');
const router = express.Router();
const itemsController = require('../controllers/itemsController');
router.get('/items', itemsController.getItems);
router.post('/items', itemsController.createItem);
module.exports = router;
Основной сервер
В файле server.js:
const express = require('express');
const app = express();
const itemsRoutes = require('./routes/itemsRoutes');
app.use(express.json()); // для обработки JSON-тел запросов
app.use('/api', itemsRoutes);
const port = 3000;
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
Расширение API
Добавьте новые маршруты для обновления и удаления данных. Ориентируетесь на пример с добавлением новых записей, который был представлен раньше.
Настройка NGINX
NGINX — это высокопроизводительный веб-сервер, который также может работать в качестве прокси-сервера. Прокси-сервер — это посредник между клиентом и сервером. Обратный прокси (reverse proxy) принимает запросы от клиентов и пересылает их на сервер приложений. Он может распределять нагрузку, управлять кэшированием, а также обеспечивать безопасность и масштабируемость приложения.
В нашем случае NGINX будет выступать в качестве прокси-сервера между клиентом и сервером Node.js, принимая запросы на порту 80 и перенаправляя их на наш API, запущенный на порту 3000.
CORS (Cross-Origin Resource Sharing) — это механизм, который позволяет управлять доступом к ресурсам API с других доменов. В конфигурации NGINX мы разрешим CORS, чтобы веб-клиенты могли взаимодействовать с нашим API.
Создание конфигурационного файла преокта
Для нашего API создадим новый конфигурационный файл в /etc/nginx/sites-available/ и настроим прокси-сервер с поддержкой CORS.
- Перейдите в директорию конфигурации NGINX и создайте файл
{название_проекта}.conf:sudo nano /etc/nginx/sites-available/{название_проекта}.conf - Вставьте следующую конфигурацию в файл и сохраните его.
# Блок server, обрабатывающий запросы, поступающие на сервер
server {
# Порт для прослушивания. Поскольку NGINX работает на HTTP-порту по умолчанию, указываем порт 80.
listen 80;
# Имя сервера, которое будет использоваться для обработки запросов. Здесь можно указать IP или домен.
server_name localhost;
# Настройка расположения для обработки запросов к API
location / {
# Прокси-передача запросов на наш API, работающий на Node.js
proxy_pass http://localhost:3000;
# Установка версии HTTP-протокола
proxy_http_version 1.1;
# Настройка заголовков, необходимых для корректной работы прокси-сервера
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
# Разрешение CORS, чтобы API был доступен для кросс-доменных запросов
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'Content-Type, Authorization';
}
}
- Сохраните файл и закройте редактор.
После создания конфигурации, необходимо активировать ее, создав символическую ссылку в папке sites-enabled и удалив стандартный файл default.
# Создайте символическую ссылку на новый файл
sudo ln -s /etc/nginx/sites-available/{название_проекта}.conf /etc/nginx/sites-enabled/
# Удалите ссылку на стандартную конфигурацию
sudo rm /etc/nginx/sites-enabled/default
# Перезапустите NGINX для применения изменений
sudo systemctl restart nginx
Создание простого веб-клиента с поддержкой CRUD операций
Теперь создадим простой веб-клиент с использованием HTML и JavaScript для взаимодействия с нашим API. Все элементы загружаются из API и отображаются в виде списка. Пользователи могут добавлять новые элементы, обновлять существующие, вводя новую информацию через диалоговые окна, и удалять элементы с подтверждением.
Пример кода веб-клиента
Создайте файл index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Simple Web Client</title>
<style>
body { font-family: Arial, sans-serif; }
.item { border: 1px solid #ddd; padding: 10px; margin-bottom: 10px; }
.actions { margin-top: 5px; }
</style>
</head>
<body>
<h1>Items</h1>
<div id="items"></div>
<h2>Add New Item</h2>
<form id="itemForm">
<input type="text" id="name" placeholder="Name" required>
<input type="text" id="description" placeholder="Description" required>
<button type="submit">Add Item</button>
</form>
<script>
// Fetch all items from the API
async function fetchItems() {
const response = await fetch('/api/items');
const items = await response.json();
const itemsContainer = document.getElementById('items');
itemsContainer.innerHTML = '';
items.forEach(item => {
const itemElement = document.createElement('div');
itemElement.className = 'item';
itemElement.innerHTML = `
<strong>Name:</strong> \${item.name}<br>
<strong>Description:</strong> \${item.description}
<div class="actions">
<button onclick="updateItem(\${item.id})">Update</button>
<button onclick="deleteItem(\${item.id})">Delete</button>
</div>
`;
itemsContainer.appendChild(itemElement);
});
}
// Add a new item to the API
document.getElementById('itemForm').addEventListener('submit', async (e) => {
e.preventDefault();
const name = document.getElementById('name').value;
const description = document.getElementById('description').value;
await fetch('/api/items', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name, description })
});
document.getElementById('itemForm').reset();
fetchItems();
});
// Update an item
async function updateItem(id) {
const newName = prompt('Enter new name:');
const newDescription = prompt('Enter new description:');
if (newName && newDescription) {
await fetch(`/api/items/\${id}`, {
method: 'PUT',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ name: newName, description: newDescription })
});
fetchItems();
}
}
// Delete an item
async function deleteItem(id) {
if (confirm('Are you sure you want to delete this item?')) {
await fetch(`/api/items/\${id}`, { method: 'DELETE' });
fetchItems();
}
}
// Load items on page load
fetchItems();
</script>
</body>
</html>
Задание на разработку API
Ваша задача — создать REST API с базой данных и веб- или десктоп-клиентом на основе одного из предложенных вариантов.
Номер варианта определяется как
номер_зачетки % 5 + 1.
Требования к отчету:
-
Номер зачетки -> Номер варианта. Укажите номер зачетки и вычислите номер варианта по формуле:
номер_зачетки % 5 + 1. -
Описание структуры разработанной БД.
- Краткое описание таблиц базы данных и связей.
- Включите ER-диаграмму и SQL-дамп для развертывания базы данных.
- Документирование API. Список всех маршрутов API с методами, описанием, параметрами и кодами ответа. Пример:
| Маршрут | Метод | Описание | Параметры в body | Заголовки | Коды ответа |
|---|---|---|---|---|---|
/api/items | GET | Получение всех элементов | - | Content-Type: application/json | 200: Успех, 500: Ошибка |
-
Полный исходный код сервера. Весь исходный код проекта, включая конфигурации, модели, контроллеры и маршруты.
-
Полный исходный код клиента. Исходный код веб/десктоп-клиента с реализацией CRUD операций.
Код должен находиться в нормальном состоянии и быть структурированным, а не разбросанным как после пьянки.
- Инструкция по развертыванию системы.
С небольшим примером того как это все в теории может выглядеть, можете ознакомиться тут
Варианты заданий:
К обязательным требованиям относится только создание CRUD. За дополнительное расширение функциональности, например генерация отчетов в 1 варианте, можно получить дополнительные баллы. Для создания интерфейса не обязательно использовать голую связку html + css + js, можно использовать фреймворки, например сочетание React (фреймворк) + Vite (сборщик) + TS (ЯП, по сути JS с типами данных).
-
Вариант 1: Платформа для обмена растениями
- База данных: Таблицы для пользователей, растений, предложений обмена и истории обменов.
- Примерный список маршрутов API:
- CRUD операции для управления растениями, создания предложений обмена и отслеживания истории.
- Поиск предложений обмена, совместимых с растениями пользователя.
- Создание запросов на обмен и подтверждение/отклонение обменов.
- Генерация отчетов о наиболее активных пользователях и самых популярных растениях для обмена.
- Клиент: Веб-приложение с фильтрацией растений по типу и региону, поддержкой обменов и ведением истории.
-
Вариант 2: Система учета волонтерской активности
- База данных: Таблицы для волонтеров, мероприятий, организаторов и отчетов об активности.
- Примерный список маршрутов API:
- CRUD операции для управления мероприятиями и участниками.
- Регистрация и отмена участия в мероприятиях с учетом максимального количества участников.
- Автоматическое уведомление волонтеров за день до мероприятия письмом на почту.
- Генерация статистики об активности волонтеров и рейтинги за выполненные задачи.
- Клиент: Веб-приложение с календарем, уведомлениями и разделом для просмотра личной статистики волонтера.
-
Вариант 3: Платформа для рекомендаций маршрутов путешествий
- База данных: Таблицы для пользователей, маршрутов, точек интереса и отзывов.
- Примерный список маршрутов API:
- CRUD операции для добавления маршрутов и отзывов.
- Генерация персонализированных маршрутов на основе предпочтений пользователя и рейтингов.
- Создание коллекций маршрутов и возможность делиться ими с друзьями.
- Клиент: Веб-приложение с картами, сохранением маршрутов в избранное и функцией совместного использования.
-
Вариант 4: Экологическая платформа для учета отходов
- База данных: Таблицы для типов отходов, пунктов приема, пользователей и отчетов об утилизации.
- Примерный список маршрутов API:
- CRUD операции для управления пунктами приема и типами отходов.
- Расчет экологического вклада пользователя на основе сданных отходов.
- Система наград и достижений для активных пользователей.
- Клиент: Веб-приложение с поиском пунктов приема, статистикой и системой достижений.
-
Вариант 5: Платформа для кулинарных мастер-классов
- База данных: Таблицы для рецептов, кулинарных мастеров, пользователей и расписания мастер-классов.
- Примерный список маршрутов API:
- CRUD операции для управления рецептами и расписанием.
- Генерация списка покупок на основе выбранного рецепта.
- Рекомендации мастер-классов на основе предпочтений пользователя и истории посещений.
- Клиент: Веб-приложение с видеоуроками, подписками на мастеров и разделом рекомендаций.
Интеграция с внешними системами
Номер варианта, надеюсь, вы уже научились определять сами...
1. Путеводитель по городу
Приложение предназначено для туристов, которые хотят получить оперативную информацию о погоде и достопримечательностях в интересующем городе. Оно помогает лучше планировать прогулки и маршруты, предоставляя данные из нескольких источников.
Описание:
- Пользователь вводит название города.
- Приложение использует Weatherstack API для получения информации о погоде: температура, вероятность осадков, описание погоды.
- С помощью Google Maps API приложение предоставляет список основных достопримечательностей рядом с городом (например, музеи или исторические здания).
- Приложение выводит погоду и список достопримечательностей в виде интерактивных карточек. Карточки достопримечательностей содержат название, описание, координаты и ссылку для построения маршрута.
2. Органайзер для праздников
Приложение помогает пользователям узнавать информацию о праздниках и выходных днях в выбранной стране, позволяя планировать отдых или поездки с учетом государственных и национальных событий.
Описание:
- Пользователь выбирает страну и месяц.
- Приложение использует Calendarific API для получения списка праздников в выбранной стране и месяце.
- Одновременно приложение запрашивает Nager.Date API для получения информации о выходных днях (государственных и национальных).
- Выводится общий календарь с праздниками и выходными днями. Пользователь может щелкнуть на событие, чтобы увидеть его подробное описание.
3. Социальная платформа для любителей животных
Это приложение создано для объединения людей, любящих животных. Оно предоставляет фотографии и интересные факты, которые можно сохранять и делиться ими в социальных сетях.
Описание:
- Пользователь выбирает вид животного (кошки, собаки или птицы).
- Приложение использует The Dog API или Shibe.Online API для получения фотографий выбранного вида животных.
- Дополнительно приложение подключает Cat Facts API или Dog Facts API для вывода интересных фактов о животных.
- Пользователь может лайкать понравившиеся изображения и делиться ими с другими пользователями платформы (общая новостная лента).
4. Анализ доступных книг
Приложение помогает пользователям находить интересные книги, используя ключевые слова. Оно предоставляет подробную информацию о книгах, доступных в открытых библиотеках и других источниках.
Описание:
- Пользователь вводит ключевое слово (например, имя автора, название книги или жанр).
- Приложение обращается к Google Books API для получения списка книг, связанных с введенным ключевым словом.
- Дополнительно запрашивается информация из Open Library API для получения подробностей о книге (год издания, количество страниц, ссылка на электронную версию, если доступно).
- Приложение отображает результаты в виде карточек с названием, автором, кратким описанием и кнопкой для открытия книги.
5. Приложение для создания персональных подборок фильмов
Приложение помогает пользователям находить фильмы по их предпочтениям, создавая персонализированные подборки на основе рейтинга, жанра и года выпуска.
Описание:
- Пользователь указывает предпочтения: жанр, минимальный рейтинг (например, выше 7), и диапазон годов выпуска (например, с 2000 по 2023).
- Приложение использует OMDb API для поиска фильмов, соответствующих заданным критериям.
- Дополнительно приложение обращается к TMDb API для получения информации о популярных фильмах из выбранного жанра или рекомендаций на основе одного фильма.
- Приложение формирует список фильмов с описанием, постерами, ссылками на трейлеры и оценками.
- Пользователь может сохранить подборку в виде файла (например, JSON или CSV) или поделиться ею через социальные сети.
Регулярные выражения
Из заданий части 1 решаем 2 задачи с использованием регулярных выражений, 2 без.
Из заданий части 2 решаем любые 2 задачи на выбор, способ решения выбираем самостоятельно.
Создание и настройка User-Service
Архитектура
Приложение разделено на три микросервиса:
- User Service – регистрация, авторизация и получение данных пользователей.
- Chat Service – обработка сообщений и хранение истории чатов.
- API Gateway – единая точка входа для маршрутизации запросов к нужным сервисам.
Сосредоточимся на нинициализации User Service. Он будет использовать:
- JWT (с NestJS Passport) для авторизации.
- Prisma для работы с PostgreSQL.
- DTO с валидацией.
- Swagger для генерации документации API.
Также мы создадим отдельный Dockerfile для микросервиса и подготовим docker‑compose файл для всего проекта, который будет поднимать PostgreSQL (образ: postgres:17-alpine) с использованием переменных окружения из файла .env.
2. Установка зависимостей и подготовка проекта
Инструменты и зависимости
Убедитесь, что установлены:
- Node.js, npm, NestJS CLI
- Docker и docker‑compose
Создание проекта микросервиса
Создаём директорию для сервиса и инициализируем NestJS проект:
mkdir user-service && cd user-service
nest new .
При помощи пакетного менеджера npm установите дополнительные зависимости:
npm install @nestjs/passport passport passport-jwt jsonwebtoken
npm install prisma @prisma/client --save-dev
npm install class-validator class-transformer
npm install @nestjs/swagger swagger-ui-express
Настройка Prisma и базы данных PostgreSQL
Инициализируйте Prisma:
npx prisma init
В файле prisma/schema.prisma задайте следующую конфигурацию:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
email String @unique
password String
name String?
createdAt DateTime @default(now())
}
Создайте миграцию и примените её (перед этим нужно будет поднять docker контейнер):
npx prisma migrate dev --name init
В файле .env (на уровне проекта) добавьте строку подключения (это значение будет переопределено переменными из docker‑compose, но на локальной разработке оно может быть таким):
DATABASE_URL="postgresql://dbuser:dbpassword@localhost:5432/chat?schema=public"
Создание DTO с валидацией и Swagger‑документацией
DTO для регистрации
Создайте файл src/auth/dto/register.dto.ts:
import { ApiProperty } from '@nestjs/swagger';
import { IsEmail, IsNotEmpty, MinLength, Matches } from 'class-validator';
export class RegisterDto {
@ApiProperty({ example: 'user@example.com' })
@IsEmail()
email: string;
@ApiProperty({
example: 'StrongPass1',
description: 'Пароль должен состоять минимум из 8 символов и содержать хотя бы одну заглавную букву',
})
@IsNotEmpty()
@MinLength(8)
@Matches(/^(?=.*[A-Z]).{8,}$/, {
message:
'Пароль должен состоять минимум из 8 символов и содержать хотя бы одну заглавную букву',
})
password: string;
@ApiProperty({ example: 'John Doe', required: false })
name?: string;
}
DTO для логина
Создайте файл src/auth/dto/login.dto.ts:
import { ApiProperty } from '@nestjs/swagger';
import { IsEmail, IsNotEmpty } from 'class-validator';
export class LoginDto {
@ApiProperty({ example: 'user@example.com' })
@IsEmail()
email: string;
@ApiProperty({ example: 'StrongPass1' })
@IsNotEmpty()
password: string;
}
Создание сервиса и контроллера пользователей
Пользовательский сервис
Создайте модуль, контроллер и сервис для пользователей:
nest generate module users
nest generate controller users
nest generate service users
В src/users/users.service.ts реализуйте методы регистрации и валидации пользователя:
import { Injectable, ConflictException, UnauthorizedException } from '@nestjs/common';
import { PrismaService } from '../prisma/prisma.service';
import { RegisterDto } from '../auth/dto/register.dto';
import * as bcrypt from 'bcrypt';
@Injectable()
export class UsersService {
constructor(private prisma: PrismaService) {}
async register(dto: RegisterDto) {
const hash = await bcrypt.hash(dto.password, 10);
try {
const user = await this.prisma.user.create({
data: { email: dto.email, password: hash, name: dto.name },
});
return user;
} catch (error) {
throw new ConflictException('Пользователь с таким email уже существует');
}
}
async validateUser(email: string, password: string) {
const user = await this.prisma.user.findUnique({ where: { email } });
if (user && await bcrypt.compare(password, user.password)) {
const { password, ...result } = user;
return result;
}
throw new UnauthorizedException('Неверные учетные данные');
}
async findById(id: number) {
return this.prisma.user.findUnique({ where: { id } });
}
}
Prisma сервис
Создайте файл src/prisma/prisma.service.ts:
import { Injectable, OnModuleInit, INestApplication } from '@nestjs/common';
import { PrismaClient } from '@prisma/client';
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
await this.$connect();
}
async enableShutdownHooks(app: INestApplication) {
this.$on('beforeExit', async () => {
await app.close();
});
}
}
Не забудьте создать и зарегистрировать модуль для Prisma (например, src/prisma/prisma.module.ts), который экспортирует PrismaService.
import { Module } from '@nestjs/common';
import { PrismaService } from './prisma/prisma.service';
@Module({
providers: [PrismaService],
exports: [PrismaService],
})
export class PrismaModule {}
Реализация JWT аутентификации с использованием Passport
Модуль аутентификации
Создайте модуль, сервис и контроллер для аутентификации:
nest generate module auth
nest generate service auth
nest generate controller auth
В src/auth/auth.service.ts реализуйте методы аутентификации и генерации JWT:
import { Injectable } from '@nestjs/common';
import { UsersService } from '../users/users.service';
import { JwtService } from '@nestjs/jwt';
import { LoginDto } from './dto/login.dto';
@Injectable()
export class AuthService {
constructor(
private usersService: UsersService,
private jwtService: JwtService,
) {}
async validateUser(email: string, pass: string) {
return this.usersService.validateUser(email, pass);
}
async login(loginDto: LoginDto) {
const user = await this.validateUser(loginDto.email, loginDto.password);
const payload = { email: user.email, sub: user.id };
return {
access_token: this.jwtService.sign(payload),
};
}
}
Создайте стратегию JWT в файле src/auth/jwt.strategy.ts:
import { Injectable } from '@nestjs/common';
import { PassportStrategy } from '@nestjs/passport';
import { ExtractJwt, Strategy } from 'passport-jwt';
@Injectable()
export class JwtStrategy extends PassportStrategy(Strategy) {
constructor() {
super({
jwtFromRequest: ExtractJwt.fromAuthHeaderAsBearerToken(),
secretOrKey: process.env.JWT_SECRET || 'defaultSecretKey',
});
}
async validate(payload: any) {
return { userId: payload.sub, email: payload.email };
}
}
В src/auth/auth.module.ts подключите необходимые модули:
import { Module } from '@nestjs/common';
import { AuthService } from './auth.service';
import { UsersModule } from '../users/users.module';
import { PassportModule } from '@nestjs/passport';
import { JwtModule } from '@nestjs/jwt';
import { JwtStrategy } from './jwt.strategy';
@Module({
imports: [
UsersModule,
PassportModule,
JwtModule.register({
secret: process.env.JWT_SECRET || 'defaultSecretKey',
signOptions: { expiresIn: '1d' },
}),
],
providers: [AuthService, JwtStrategy],
exports: [AuthService],
})
export class AuthModule {}
Контроллер аутентификации
Создайте src/auth/auth.controller.ts:
import { Body, Controller, Post, UsePipes, ValidationPipe } from '@nestjs/common';
import { UsersService } from '../users/users.service';
import { RegisterDto } from './dto/register.dto';
import { AuthService } from './auth.service';
import { LoginDto } from './dto/login.dto';
import { ApiTags } from '@nestjs/swagger';
@ApiTags('auth')
@Controller('auth')
export class AuthController {
constructor(
private usersService: UsersService,
private authService: AuthService,
) {}
@Post('register')
@UsePipes(new ValidationPipe())
async register(@Body() dto: RegisterDto) {
return this.usersService.register(dto);
}
@Post('login')
@UsePipes(new ValidationPipe())
async login(@Body() dto: LoginDto) {
return this.authService.login(dto);
}
}
Интеграция Swagger для автоматической документации
В файле src/main.ts настройте Swagger:
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
import { ValidationPipe } from '@nestjs/common';
import { DocumentBuilder, SwaggerModule } from '@nestjs/swagger';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.useGlobalPipes(new ValidationPipe());
// Настройка Swagger
const config = new DocumentBuilder()
.setTitle('User Service API')
.setDescription('Документация API для управления пользователями')
.setVersion('1.0')
.addBearerAuth()
.build();
const document = SwaggerModule.createDocument(app, config);
SwaggerModule.setup('api-docs', app, document);
await app.listen(3001);
}
bootstrap();
После запуска приложения документация будет доступна по адресу http://localhost:3001/api-docs.
Dockerfile для микросервиса
В корне проекта user-service создайте файл Dockerfile:
# Используем официальный Node.js образ
FROM node:20-alpine
# Создаем рабочую директорию
WORKDIR /usr/src/app
# Копируем package.json и package-lock.json
COPY package*.json ./
# Устанавливаем зависимости
RUN npm install
# Копируем исходный код приложения
COPY . .
# Генерируем Prisma клиент
RUN npx prisma generate
# Собираем проект
RUN npm run build
# Открываем порт
EXPOSE 3001
# Запускаем приложение
CMD ["node", "dist/main.js"]
Вариант с одновременным запуском всех сервисов:
- Создаем bash скрипт:
#!/bin/sh
set -e
echo "Waiting for database to be ready..."
until npx prisma migrate deploy > /dev/null 2>&1; do
echo "Database not ready yet. Retrying in 3 seconds..."
sleep 3
done
echo "Applying database migrations..."
npx prisma migrate deploy
echo "Starting application..."
exec node dist/src/main.js
- Меняем Dockerfile
FROM node:20-alpine as builder
RUN apk add --no-cache openssl \
&& apk add --no-cache curl
ENV NODE_ENV build
USER node
WORKDIR /home/node
COPY package*.json ./
RUN npm ci
COPY --chown=node:node . .
RUN npx prisma generate \
&& npm run build \
&& npm prune --omit=dev
# ---
FROM node:20-alpine as production
RUN apk add --no-cache openssl \
&& apk add --no-cache curl
ENV NODE_ENV production
USER node
WORKDIR /home/node
COPY --from=builder --chown=node:node /home/node/package*.json ./
COPY --from=builder --chown=node:node /home/node/node_modules/ ./node_modules/
COPY --from=builder --chown=node:node /home/node/dist/ ./dist/
COPY --from=builder --chown=node:node /home/node/prisma/ ./prisma/
COPY --from=builder --chown=node:node /home/node/entrypoint.sh ./entrypoint.sh
RUN chmod +x entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]
docker‑compose и .env файл
.env файл
В корневой директории общего проекта (рядом с docker‑compose файлом) создайте файл .env со следующим содержимым:
DATABASE_USERNAME=dbuser
DATABASE_PASSWORD=dbpassword
DATABASE_NAME=chat
JWT_SECRET=YourJWTSecretKey
docker‑compose файл
Создайте файл docker-compose.yml:
version: '3.8'
services:
postgres:
image: postgres:17-alpine
restart: always
environment:
POSTGRES_USER: ${DATABASE_USERNAME}
POSTGRES_PASSWORD: ${DATABASE_PASSWORD}
POSTGRES_DB: ${DATABASE_NAME}
ports:
- '5432:5432'
volumes:
- postgres_data:/var/lib/postgresql/data
user-service:
build: ./user-service
restart: always
ports:
- '3001:3001'
environment:
DATABASE_URL: "postgresql://${DATABASE_USERNAME}:${DATABASE_PASSWORD}@postgres:5432/${DATABASE_NAME}?schema=public"
JWT_SECRET: ${JWT_SECRET}
depends_on:
- postgres
# Дополнительные сервисы (chat-service, api-gateway) добавляем по аналогичной схеме
volumes:
postgres_data:
Теперь все параметры подключения к базе данных и секреты вынесены в файл .env, а docker‑compose использует их при запуске контейнеров.
Создание и настройка Chat-Service
Архитектура
Chat Service предназначен для приема, обработки и рассылки сообщений. Он реализует двунаправленный протокол WebSocket для обмена данными между клиентом и сервером, что обеспечивает низкую задержку и возможность «живого» общения.
WebSockets – это протокол, который позволяет устанавливать постоянное соединение между клиентом и сервером посредством одноразового рукопожатия, после которого происходит двунаправленная передача данных в реальном времени. Благодаря этому протоколу можно передавать данные без необходимости повторного установления соединения для каждого запроса. (Подробнее см. WebSocket Overview.)
В данном руководстве Chat Service будет использовать:
- WebSockets (с NestJS) для обработки сообщений в реальном времени.
- Prisma для работы с PostgreSQL.
- DTO с валидацией для структурирования данных.
- Swagger для генерации документации API (при наличии HTTP‑эндпоинтов, например, для получения истории чатов).
Также будет создан отдельный Dockerfile для микросервиса и дополнен docker‑compose файл для всего проекта, который поднимает PostgreSQL (образ: postgres:17-alpine) с использованием переменных окружения из файла .env.
2. Установка зависимостей и подготовка проекта
Инструменты и зависимости
Убедитесь, что установлены:
- Node.js, npm, NestJS CLI
- Docker и docker‑compose
Создание проекта микросервиса
Создаём директорию для сервиса и инициализируем новый проект NestJS:
mkdir chat-service && cd chat-service
nest new .
При помощи пакетного менеджера npm установите дополнительные зависимости:
npm install @nestjs/websockets @nestjs/platform-socket.io
npm install prisma @prisma/client --save-dev
npm install class-validator class-transformer
npm install @nestjs/swagger swagger-ui-express
Дополнительные зависимости необходимы для реализации функционала WebSocket (пакеты
@nestjs/websocketsи@nestjs/platform-socket.io), работы с базой данных PostgreSQL через Prisma, валидации данных в DTO, и для генерации документации с помощью Swagger.
Настройка Prisma и базы данных PostgreSQL
Инициализируйте Prisma:
npx prisma init
В файле prisma/schema.prisma задайте следующую конфигурацию:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model Message {
id Int @id @default(autoincrement())
content String
senderId Int
room String? // Название комнаты или канала, если потребуется
createdAt DateTime @default(now())
}
Модель Message хранит сообщения чата, включая содержание, идентификатор отправителя, название комнаты (если используется) и время создания. Автоматическая генерация идентификатора (autoincrement) и текущей даты (now()) упрощают ведение истории чатов.
Создайте миграцию и примените её (перед этим убедитесь, что docker-контейнер с PostgreSQL запущен):
npx prisma migrate dev --name init
В файле .env (на уровне проекта) добавьте строку подключения:
DATABASE_URL="postgresql://dbuser:dbpassword@localhost:5432/chat?schema=public"
Значение переменной
DATABASE_URLможет быть переопределено docker‑compose файлом для работы в контейнере, но оно будет использоваться для локальной разработки.
Создание DTO с валидацией и Swagger‑документацией
DTO для отправки сообщения
Создайте файл src/chat/dto/send-message.dto.ts:
import { ApiProperty } from '@nestjs/swagger';
import { IsNotEmpty, IsString, IsNumber } from 'class-validator';
export class SendMessageDto {
@ApiProperty({ example: 'Привет, как дела?' })
@IsNotEmpty({ message: 'Содержание сообщения не должно быть пустым' })
@IsString({ message: 'Содержание сообщения должно быть строкой' })
content: string;
@ApiProperty({ example: 123, description: 'ID пользователя-отправителя' })
@IsNotEmpty({ message: 'ID отправителя обязателен' })
@IsNumber({}, { message: 'ID отправителя должен быть числом' })
senderId: number;
@ApiProperty({ example: 'general', description: 'Название комнаты или чата', required: false })
room?: string;
}
Аннотации с помощью
ApiPropertyобеспечивают автоматическую генерацию документации Swagger, а валидаторы (например,IsNotEmptyиIsString) гарантируют корректность получаемых данных.
При необходимости можно создать дополнительные DTO для отображения истории сообщений или для формирования ответа API.
Создание сервиса и контроллера чатов
Prisma сервис
Создайте файл src/prisma/prisma.service.ts:
import { Injectable, OnModuleInit, INestApplication } from '@nestjs/common';
import { PrismaClient } from '@prisma/client';
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
// Устанавливаем соединение с базой данных при инициализации модуля
await this.$connect();
}
async enableShutdownHooks(app: INestApplication) {
// Обеспечиваем корректное завершение работы приложения при остановке
this.$on('beforeExit', async () => {
await app.close();
});
}
}
PrismaService наследует возможности PrismaClient и добавляет методы для подключения к базе данных и корректного завершения работы приложения. Это упрощает повторное использование сервиса в различных модулях.
Создайте и зарегистрируйте модуль для Prisma, например, src/prisma/prisma.module.ts:
import { Module } from '@nestjs/common';
import { PrismaService } from './prisma.service';
@Module({
providers: [PrismaService],
exports: [PrismaService],
})
export class PrismaModule {}
Создание сервиса для работы с сообщениями
Создайте модуль, контроллер и сервис для чатов:
nest generate module chat
nest generate controller chat
nest generate service chat
В src/chat/chat.service.ts реализуйте методы для сохранения сообщений и получения истории чатов:
import { Injectable } from '@nestjs/common';
import { PrismaService } from '../prisma/prisma.service';
import { SendMessageDto } from './dto/send-message.dto';
@Injectable()
export class ChatService {
constructor(private prisma: PrismaService) {}
/**
* Сохраняет сообщение в базе данных.
* @param dto DTO с информацией о сообщении.
* @returns Сохраненное сообщение.
*/
async saveMessage(dto: SendMessageDto) {
const message = await this.prisma.message.create({
data: {
content: dto.content,
senderId: dto.senderId,
room: dto.room,
},
});
return message;
}
/**
* Получает историю сообщений. Если задан параметр room, возвращает сообщения из указанной комнаты.
* @param room Название комнаты (опционально).
* @returns Массив сообщений.
*/
async getMessages(room?: string) {
const query = room ? { where: { room } } : {};
return this.prisma.message.findMany(query);
}
}
Методы сервиса используют Prisma для выполнения операций над базой данных. Метод
saveMessageсохраняет новое сообщение, аgetMessagesреализует поиск сообщений по критерию комнаты.
Реализация WebSocket Gateway для работы в реальном времени
Создайте файл src/chat/chat.gateway.ts:
import {
WebSocketGateway,
SubscribeMessage,
MessageBody,
WebSocketServer,
} from '@nestjs/websockets';
import { Server } from 'socket.io';
import { ChatService } from './chat.service';
import { SendMessageDto } from './dto/send-message.dto';
@WebSocketGateway({ cors: true }) // Разрешаем кросс-доменные запросы
export class ChatGateway {
@WebSocketServer()
server: Server;
constructor(private chatService: ChatService) {}
/**
* Обработчик входящих сообщений через WebSocket.
* При получении события 'sendMessage' сохраняет сообщение в базе и транслирует его всем подключенным клиентам.
* @param data Данные сообщения, переданные клиентом.
* @returns Сохраненное сообщение.
*/
@SubscribeMessage('sendMessage')
async handleSendMessage(@MessageBody() data: SendMessageDto) {
// Сохраняем сообщение в базу данных
const savedMessage = await this.chatService.saveMessage(data);
// Трансляция сообщения всем подключенным клиентам
this.server.emit('message', savedMessage);
return savedMessage;
}
}
Метод handleSendMessage является обработчиком события WebSocket.
"WebSockets позволяют устанавливать постоянное соединение, что дает возможность серверу и клиенту обмениваться сообщениями в режиме реального времени без необходимости повторного установления соединения. Это особенно важно для чатов, игровых приложений и онлайн-трансляций."
HTTP контроллер для работы с историей сообщений (опционально)
Если необходимо предоставлять историю сообщений через HTTP‑эндпоинты, настройте контроллер:
В src/chat/chat.controller.ts:
import { Controller, Get, Query } from '@nestjs/common';
import { ChatService } from './chat.service';
import { ApiTags, ApiQuery } from '@nestjs/swagger';
@ApiTags('chat')
@Controller('chat')
export class ChatController {
constructor(private readonly chatService: ChatService) {}
/**
* HTTP GET метод для получения истории сообщений.
* Если параметр room указан, возвращаются сообщения из конкретной комнаты.
* @param room Название комнаты (опционально).
* @returns Массив сообщений.
*/
@Get('history')
@ApiQuery({ name: 'room', required: false, description: 'Название комнаты чата' })
async getHistory(@Query('room') room?: string) {
return this.chatService.getMessages(room);
}
}
Этот эндпоинт может использоваться для исторического просмотра сообщений, а также для отладки или аналитики чатов.
Обновление модуля Chat
В файле src/chat/chat.module.ts импортируйте необходимые модули и зарегистрируйте компоненты:
import { Module } from '@nestjs/common';
import { ChatService } from './chat.service';
import { ChatController } from './chat.controller';
import { ChatGateway } from './chat.gateway';
import { PrismaModule } from '../prisma/prisma.module';
@Module({
imports: [PrismaModule],
providers: [ChatService, ChatGateway],
controllers: [ChatController],
})
export class ChatModule {}
Модуль объединяет в себе сервис, контроллер и gateway, что позволяет распределять ответственность за хранение, обработку и доставку сообщений.
Интеграция Swagger для автоматической документации
Если в Chat Service реализованы HTTP‑эндпоинты (например, для получения истории сообщений), настройте Swagger в файле src/main.ts:
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
import { ValidationPipe } from '@nestjs/common';
import { DocumentBuilder, SwaggerModule } from '@nestjs/swagger';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.useGlobalPipes(new ValidationPipe());
// Настройка Swagger
const config = new DocumentBuilder()
.setTitle('Chat Service API')
.setDescription('Документация API для работы с сообщениями и историей чатов')
.setVersion('1.0')
.build();
const document = SwaggerModule.createDocument(app, config);
SwaggerModule.setup('api-docs', app, document);
await app.listen(3002);
}
bootstrap();
После запуска приложения документация будет доступна по адресу:
http://localhost:3002/api-docs
Dockerfile для микросервиса
В корне проекта chat-service создайте файл Dockerfile:
# Используем официальный Node.js образ
FROM node:20-alpine
# Создаем рабочую директорию внутри контейнера
WORKDIR /usr/src/app
# Копируем файлы package.json и package-lock.json в рабочую директорию
COPY package*.json ./
# Устанавливаем зависимости
RUN npm install
# Копируем весь исходный код приложения в контейнер
COPY . .
# Генерируем Prisma клиент для работы с базой данных
RUN npx prisma generate
# Собираем проект (компиляция TypeScript в JavaScript)
RUN npm run build
# Открываем порт (например, 3002)
EXPOSE 3002
# Запускаем приложение
CMD ["node", "dist/main.js"]
В Dockerfile описан стандартный процесс сборки и запуска Node.js приложения: установка зависимостей, генерация Prisma клиента, сборка проекта и запуск конечного приложения.
Для продакшен-сборки можно применить технику многоступенчатой сборки, что поможет уменьшить размер конечного образа.
Вариант с использованием многоступенчатой сборки
# Stage 1: Сборка приложения
FROM node:20-alpine as builder
WORKDIR /home/node
COPY package*.json ./
RUN npm ci
COPY . .
RUN npx prisma generate && npm run build && npm prune --omit=dev
# Stage 2: Запуск в продакшене
FROM node:20-alpine as production
WORKDIR /home/node
COPY --from=builder /home/node/package*.json ./
COPY --from=builder /home/node/node_modules/ ./node_modules/
COPY --from=builder /home/node/dist/ ./dist/
COPY --from=builder /home/node/prisma/ ./prisma/
EXPOSE 3002
CMD ["node", "dist/main.js"]
docker‑compose и .env файл
.env файл
В корневой директории общего проекта (рядом с docker‑compose файлом) создайте файл .env со следующим содержимым:
DATABASE_USERNAME=dbuser
DATABASE_PASSWORD=dbpassword
DATABASE_NAME=chat
JWT_SECRET=YourJWTSecretKey
Все параметры подключения и секреты вынесены в отдельный файл .env, что упрощает управление конфигурацией в разных окружениях.
docker‑compose файл
Создайте файл docker-compose.yml:
version: '3.8'
services:
postgres:
image: postgres:17-alpine
restart: always
environment:
POSTGRES_USER: ${DATABASE_USERNAME}
POSTGRES_PASSWORD: ${DATABASE_PASSWORD}
POSTGRES_DB: ${DATABASE_NAME}
ports:
- '5432:5432'
volumes:
- postgres_data:/var/lib/postgresql/data
user-service:
build: ./user-service
restart: always
ports:
- '3001:3001'
environment:
DATABASE_URL: "postgresql://${DATABASE_USERNAME}:${DATABASE_PASSWORD}@postgres:5432/${DATABASE_NAME}?schema=public"
JWT_SECRET: ${JWT_SECRET}
depends_on:
- postgres
chat-service:
build: ./chat-service
restart: always
ports:
- '3002:3002'
environment:
DATABASE_URL: "postgresql://${DATABASE_USERNAME}:${DATABASE_PASSWORD}@postgres:5432/${DATABASE_NAME}?schema=public"
depends_on:
- postgres
# API Gateway можно добавить по аналогичной схеме
volumes:
postgres_data:
docker‑compose файл объединяет все сервисы (PostgreSQL, User Service, Chat Service). Благодаря использованию файла .env переменные удобно переопределяются, что упрощает разворачивание проекта как в локальной среде, так и в продакшене.
Инструкция по подключению к базе данных
Найти свой логин и пароль можно в документе, который прикреплен к курсу в мудле.
Подключение к базе данных вне внутренней сети СГУ
Для подключения к базе данных за пределами внутренней сети СГУ используйте следующие данные:
- Host:
78.37.82.13 - Port:
10207 - Логин (log): ваш логин
- Пароль (pwd): ваш пароль
- База данных (db):
{логин}_db
Подключение к базе данных из внутренней сети СГУ
Если вы подключаетесь из внутренней сети СГУ, меняются только host и port:
- Host:
172.16.46.207 - Port:
443 - Логин (log): ваш логин
- Пароль (pwd): ваш пароль
- База данных (db):
{логин}_db
Убедитесь, что у вас настроено корректное подключение в соответствии с сетью, в которой вы находитесь.
Задание 1
- Скачать iso-образ ОС Ubuntu 24.04 по ссылке с официального сайта Ubuntu.
- Установить Ubuntu 22.04 на виртуальную машину VMWare из iso-образа.
- Установить (на выбор):
- Postgresql:
sudo apt install postgresql - MariaDB:
sudo apt install mariadb-server
- Postgresql:
- Запустить сервер БД:
- Для Postgresql:
sudo systemctl start postgresql - Для MariaDB:
sudo systemctl start mysql
- Для Postgresql:
- Создать тестовую БД средствами консольного клиента:
- Для Postgresql:
sudo su postgres psql create database test; - Для MariaDB:
sudo mysql create database test;
- Для Postgresql:
- Присоединиться к тестовой БД:
- Для Postgresql:
\c test; - Для MariaDB:
use test;
- Для Postgresql:
- Создать простую таблицу:
CREATE TABLE my_table ( id SERIAL NOT NULL, code VARCHAR(10) NOT NULL, name VARCHAR(500) NOT NULL, PRIMARY KEY (id) ); - Произвести манипуляции как в лекции:
- Добавить колонку с текущим временем:
ALTER TABLE my_table ADD datetime timestamp NOT NULL DEFAULT now(); - Изменить тип данных колонки
code:ALTER TABLE my_table ALTER COLUMN code TYPE varchar(40); - Удалить колонку
datetime:ALTER TABLE my_table DROP COLUMN datetime; - Удалить таблицу:
DROP TABLE my_table;
- Добавить колонку с текущим временем:
Отчет
Отчет должен быть представлен в виде скриншотов успешного выполнения всех команд и манипуляций.
Задание 2
-
Произвести установку DBeaver на виртуальную машину, установленную в задании 1.
Инструкцию по установке и само приложение можно найти на официальном сайте - https://dbeaver.io/. -
Произвести подключение к установленной на предыдущем занятии СУБД.
-
Произвести манипуляции с БД, аналогичные заданию 1.
Отчет в виде скриншотов
Задание 3
Скачать, установить и развернуть демонстрационную базу данных.
Произвести подключение к ней. В отчете привести список таблиц базы, полученный SQL-запросом.
Открыть новое окно редактора запросов. Написать запрос по добавлению колонки city_name с типом text в таблицу aircrafts_data.
Написать запрос на обновление данных в колонке city_name, данные нужно взять из колонки city.
Написать запрос на удаление колонки city_name из таблицы aircrafts_data.
В отчете привести все SQL-запросы и результаты их выполнения (можно скриншоты).
Примечание: При использовании MySQL необходимо воспользоваться другим дампом БД и изучить документацию по развертыванию БД в MySQL.
Задание 4
Все работы производить с демонстрационной базой данных. База была установлена на прошлых занятиях!
Произвести подключение к ней. Открыть новое окно редактора запросов.
Написать запрос, который соединит таблицу «Полетов» (flights) с таблицей «Аэропорты» (airports_data).
Ключ соединения — поле «Аэропорт отправления» (flights.departure_airport).
Добавить в полученный запрос фильтрацию по полю «Дата отправления» (flights.scheduled_departure) старше, чем 2017-09-01.
В отчете привести все SQL-запросы и результаты их выполнения (можно скриншоты).
Задание 5
Все работы производить с демонстрационной базой данных. База была установлена на прошлых занятиях. Произвести подключение к ней.
1. Запрос к таблице «Полеты» (flights)
Откройте новое окно редактора запросов. Напишите запрос к таблице «Полеты» (flights), чтобы показать поля: «Номер рейса» (flights.flight_no), «Аэропорт отправления» (flights.departure_airport) и «Аэропорт прибытия» (flights.arrival_airport). Убедитесь, что в результате запроса отсутствуют дублирующиеся записи.
2. Запрос к таблице «Бронирования» (bookings)
Откройте новое окно редактора запросов. Напишите запрос к таблице «Бронирования» (bookings) и отобразите поля «Сумма бронирования» (bookings.total_amount) и «Месяц бронирования», округлив дату бронирования (bookings.book_date) до месяца. Далее напишите функцию lead со смещением на 2 вперед и отобразите поле «Номер бронирования» (bookings.book_ref).
В отчете привести тексты запросов, функции и скриншоты запуска.
Задание №6
Все работы производить с демонстрационной базой данных. База была установлена на прошлых занятиях. Произвести подключение к ней.
1. Соединение таблиц и создание материализованного представления
Открыть новое окно редактора запросов. Написать запрос, который соединит таблицы «Полеты» (flights), «Летательные аппараты» (aircrafts_data) (ключ соединения aircraft_code) и «Аэропорты» (airports_data) (ключ соединения departure_airport). На основе этого запроса создать материализованное представление. Далее обновить данные об одном летательном аппарате и материализованное представление.
2. Использование функции array_agg и создание представления
Открыть новое окно редактора запросов. Написать запрос, который использует таблицу «Посадочных мест» (seats). Используя функцию array_agg, собрать все посадочные места для каждого летательного аппарата. На основе этого запроса создать представление.
В отчете привести тексты запросов, функции и результаты их выполнения (можно в виде скриншотов).
Подготовка БД
Перед началом работы развернем следующую тестовую базу данных, название можете выбрать произвольно:
-- Основная таблица сотрудников
CREATE TABLE TAB1 (
ID SERIAL PRIMARY KEY,
FAM VARCHAR(50),
IMJ VARCHAR(50),
OTCH VARCHAR(50),
DT_ROJD DATE,
POL CHAR(1),
ADDRESS_REG TEXT,
ADDRESS_WORK TEXT
);
-- Временная таблица для корректировки и проверки данных
CREATE TABLE TAB1_TEMP (
ID SERIAL PRIMARY KEY,
FAM VARCHAR(50),
IMJ VARCHAR(50),
OTCH VARCHAR(50),
DT_ROJD DATE,
POL CHAR(1),
ADDRESS_REG TEXT,
ADDRESS_WORK TEXT
)
-- Таблица FPSP - в ней хранятся записи о пропусках (CARDNO) выданных сотрудникам (ID)
CREATE TABLE FPSP (
ID INT,
CARDNO VARCHAR(20),
SOME_DATA VARCHAR(100)
);
Загрузка данных первого филиала
Вы получили от филиала организации CSV-файл data.csv, содержащий данные о сотрудниках. В сообщении было написано, что вероятно, они были введены вручную в Excel и, потенциально, могут содержать ошибки и смесь различных форматов данных. Пример данных, которые потенциально могут находиться в полученном .csv файле:
FAM,IMJ,OTCH,DT_ROJD,POL,ADDRESS_REG,ADDRESS_WORK
Игнатова,Варвара,Валериевна,2015-11-14,m,,"ст. Джейрах, наб. Котовского, д. 9, 889080"
ЛихачевНиканорВитальевич,,,2012-12-23,м,,"г. Псков, ш. Декабристов, д. 4 стр. 48, 352194"
...
Чтобы справиться с этим, вы решаете сначала загрузить данные во временную таблицу TAB1_TEMP. Для этого воспользуемся следующей командой:
COPY STAGE_TAB1(FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK)
FROM '/path/to/data.csv' CSV HEADER ENCODING 'UTF8';
Теперь необходимо очистить данные, обратите внимание на:
- Слитное написание FAM,IMJ,OTCH в одном поле -
SPLIT_PART; - Несогласованные форматы дат (DD.MM.YYYY, YYYY-MM-DD и другие) -
TO_DATE; - Пустые значения в столбцах;
- Опечатки в поле POL (муж, жен, m, жe) -
LOWER&IN; - Дублирующиеся записи -
GROUP BY&DISTINCT; - Ошибки при заполнении поля DT_ROJD (даты в будущем или невозможные даты)
- Некорректные символы или пустые строки в текстовых полях
Массовая вставка из одной таблицы в другую (TAB1_TEMP -> TAB1)
Когда данные очищены, вы можете массово перенести их в TAB1:
INSERT INTO TAB1 (FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK)
SELECT FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK FROM TAB1_TEMP;
Теперь в TAB1 находятся корректные данные из первого филиала.
Массовая вставка нескольких строк напрямую
Помимо данных из филиалов, иногда нужно быстро добавить несколько записей вручную. Для этого можно использовать массовую вставку одним оператором INSERT ... VALUES:
INSERT INTO TAB1 (FAM, IMJ, OTCH, DT_ROJD, POL) VALUES
('T1', 'T1', 'T1', '2024-10-18', 'м'),
('T2', 'T2', 'T2', '2024-10-18', 'м'),
('T3', 'T3', 'T3', '2024-10-18', 'м');
Задача: при помощи генератора или вручную написать 10 новых записей для добавления в таблицу.
Получение данных второго филиала и проверка через EXCEPT
Через некоторое время от второго филиала поступает уже подготовленный специалистом CSV-файл data2.csv. Его данные должны быть загружены во временную таблицу TAB1_TEMP. Но прежде очистите TAB1_TEMP от прежних данных, чтобы избежать наложения:
TRUNCATE TABLE TAB1_TEMP;
Теперь загрузите новый CSV:
COPY TAB1_TEMP(FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK)
FROM '/path/to/data2.csv' CSV HEADER ENCODING 'UTF8';
Данные второго филиала уже корректны, но вы должны убедиться, что в TAB1 их ещё нет. Для этого можно воспользоваться оператором EXCEPT, задача которого найти расхождение между таблицами:
SELECT FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK
FROM TAB1_TEMP
EXCEPT
SELECT FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK
FROM TAB1;
Если результатом запроса будут строки, значит они присутствуют в TAB1_TEMP, но отсутствуют в TAB1. Можно их массово добавить при помощи комбинации массовой вставки и EXCEPT, так как предполагается, что предыдущий специалист их уже подготовил:
INSERT INTO TAB1 (FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK)
SELECT FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK
FROM TAB1_TEMP
EXCEPT
SELECT FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK
FROM TAB1;
Использование множественного IN по нескольким полям
Предположим, в таблице FPSP (файл с данными) хранится информация о пропусках для сотрудников: (ID, CARDNO). Если вы хотите вставить в TAB1 данные только о тех сотрудниках, которым уже выдан пропуск, вы можете использовать множественный IN. Например, при переносе сотрудников из TAB2:
INSERT INTO TAB1 (FAM, IMJ, OTCH, DT_ROJD, POL, ADDRESS_REG, ADDRESS_WORK)
SELECT T2.FAM, T2.IMJ, T2.OTCH, T2.DT_ROJD, T2.POL, T2.ADDRESS_REG, T2.ADDRESS_WORK
FROM TAB2 T2
WHERE (T2.ID, T2.CARDNO) IN (
SELECT ID, CARDNO FROM FPSP
);
Автоматизация
В реальной практике вы можете использовать хранимые процедуры и триггеры на BEFORE INSERT, чтобы автоматически очищать данные при загрузке в TAB1. Тогда не придётся вручную удалять некорректные строки или преобразовывать даты — всё будет происходить автоматически.
Можно реализовать на доп. баллы, передам Носову, что сделали дополнительный усложненный вариант и можете претендовать на дополнительный
+на экзамене.
Таким образом, вы последовательно:
- Обнаружили проблему при прямой загрузке «грязных» данных.
- Решили её, использовав промежуточную таблицу для загрузки и очистки, а затем выполнили массовую вставку в основную таблицу.
- Проверили уникальность новых данных с помощью
EXCEPT. - Освоили массовую вставку из одной таблицы в другую.
- Применили множественный
INпо нескольким полям. - Узнали о возможностях автоматизации процесса.
Все лабораторные составлены на основании стандарта с перечнем профессиональных компотенций "Цифрового куратора". Ознакомиться с ним можно по ссылке.
Лабораторная работа 1: Основы работы с облачными презентациями (Google Slides)
Цель: Развитие навыков работы с облачными сервисами для создания презентаций и публичного выступления.
- Введение в облачные технологии: их роль и преимущества.
- Обзор сервисов для создания презентаций:
- Google Slides;
- Фокус;
- Slidesgo;
- Figma;
- PowerPoint.
- Структура презентации и использование мультимедийных элементов.
Практическая часть: Необходимо создать презентацию на одну из предложенных тем:
- Защита персональных данных в интернете.
- Противодействие фейковым новостям.
- Основы работы с государственными онлайн-сервисами.
- Угрозы кибербезопасности и методы защиты.
В конце пары студенты должны выступить перед одногруппниками с целью развития навыков публичных выступлений. На последнем слайде должны присутствовать источники откуда бралась информация.
Лабораторная работа 2: Интерактивные образовательные материалы в Quizlet
Цель: Освоение инструментов для создания интерактивных обучающих материалов с использованием платформы Quizlet.
- Введение в интерактивные образовательные материалы.
- Примеры использования Quizlet для обучения и тестирования.
Практическая часть: Создание набора карточек по теме:
- Основные угрозы в интернете (вирусы, фишинг, мошенничество, ...).
Лабораторная работа 3: Сбор и анализ информации с использованием Google Forms
Цель: Формирование навыков сбора данных и анализа информации с помощью онлайн-инструментов.
- Принципы создания опросов.
- Использование Google Forms / Яндекс Форм для сбора данных.
- Методы анализа результатов.
Практическая часть:
- Создание анкеты на тему «Уровень цифровой грамотности населения».
- Рассылка анкеты и сбор данных среди студентов или в учебной группе.
- Анализ полученных данных с последующим обсуждением результатов (при проведении анализа необходимо оперирровать статистическими данными, для большей наглядности лучше использовать инфографику и визуализировать полученные данные).
Лабораторная работа 4: Разработка руководства по цифровой безопасности
Цель: Формирование навыков разработки практических руководств и совместной работы в облачных сервисах.
- Введение в информационную безопасность.
- Способы защиты данных и цифровой грамотности.
Практическая часть:
- Поиск и сбор информации о современных методах защиты данных.
- Создание практического руководства по безопасному поведению в интернете с использованием Google Docs.
- Совместное редактирование документа в группе.
Лабораторная работа 5: Организация вебинаров и дистанционных мероприятий
Цель: Освоение навыков организации и проведения онлайн-мероприятий для цифрового кураторства.
- Обзор инструментов для проведения вебинаров (Zoom, Google Meet).
- Основные правила модерации онлайн-мероприятий.
Практическая часть:
- Организация учебного вебинара на одну из тем курса.
- Подготовка сопроводительных материалов (презентация, документы).
- Проведение вебинара с участием группы.
Лабораторная работа 6: Создание информационных материалов и контента для социальных сетей
Цель: Освоение навыков разработки и визуального оформления информационных материалов (брошюр, буклетов) и создания образовательного контента для социальных сетей.
Часть 1: Создание информационного буклета
-
Тема для буклета:
- «Как начать использовать государственные электронные сервисы».
- Содержимое:
- Преимущества использования государственного сервиса (на выбор).
- Инструкция по регистрации и основным функциям.
- Советы по безопасности.
-
Процесс создания:
- Выберите один из предложенных сервисов (Canva, Adobe Express, Figma).
- Разработайте дизайн и структуру буклета.
- Добавьте инфографику и иллюстрации для визуализации информации.
-
Выходной результат: Буклет в формате PDF, готовый для печати или цифрового использования.
Часть 2: Создание и публикация постов в социальных сетях
-
Темы для постов:
- Основы цифровой безопасности: советы и рекомендации.
- Противодействие фейковым новостям: как отличить правду от вымысла.
- Советы по защите персональных данных в интернете.
-
Процесс работы:
- Создайте серию из трех постов на выбранную тему.
- Для создания визуальных элементов к постам используйте редакторы (например, Crello, Canva).
Итоговый отчет
Итоговый отчет должен включать:
- Описание процесса создания материалов.
- Пример оформленного буклета (скриншоты или PDF).
- Выводы и рекомендации для улучшения материалов.
Лабораторная работа 7: Поиск и проверка информации в интернете
Цель: Развитие критического мышления и навыков проверки информации в интернете.
- Методы эффективного поиска информации в интернете.
- Критерии оценки достоверности источников.
Практическая часть:
- Поиск информации по заданной теме (например, современные угрозы в киберпространстве).
- Анализ достоверности и источников информации с созданием краткого отчета.
Руководство по созданию диаграмм с помощью Mermaid и PlantUML
Введение
Разберем как создавать диаграммы с помощью кода на примере Mermaid и PlantUML.
Установка и настройка
Установка Java
Для работы PlantUML необходимо установить Java:
- Скачайте Java: Перейдите на официальный сайт Java Downloads и скачайте последнюю версию.
- Установите Java: Следуйте инструкциям установщика для вашей операционной системы.
- Проверьте установку: В командной строке введите
java -version, чтобы убедиться, что Java установлена корректно.
Установка Visual Studio Code
Скачайте и установите Visual Studio Code с официального сайта:
Установка расширений
Поддерживаемые диаграммы
Оба инструмента, Mermaid и PlantUML, поддерживают следующие типы диаграмм:
- Графы
- Блок-схемы
- Диаграммы Ганта
- Диаграммы последовательностей
- ER-диаграммы (для Mermaid)
- Диаграммы классов (для PlantUML)
- Диаграммы состояний (для PlantUML)
- Диаграммы активности (для PlantUML)
- ...
С полным перечнем можно ознакомиться в официальной документации: Mermaid и PlantUML.
Создание диаграмм с помощью Mermaid
Mermaid — это простой и мощный инструмент для создания диаграмм с использованием текста.
Пример диаграммы
graph LR
A[Начало] --> B{Вопрос?}
B -- Да --> C[Действие 1]
B -- Нет --> D[Действие 2]
C --> E[Конец]
D --> E[Конец]
Стилизация диаграмм
Диаграммы Mermaid можно стилизовать с помощью CSS и встроенных тем.
Пример стилизации:
graph LR
A[Начало] --> B{Вопрос?}
B -- Да --> C[Действие 1]
B -- Нет --> D[Действие 2]
C --> E[Конец]
D --> E[Конец]
classDef default fill:#f9f,stroke:#333,stroke-width:2px;
class A,C,E default;
Рендеринг онлайн
Диаграммы Mermaid можно рендерить онлайн через mermaid.live.
Создание диаграмм с помощью PlantUML
PlantUML — это мощный инструмент для создания UML-диаграмм с помощью текста. PlantUML требует установки Java для рендеринга диаграмм.
Пример диаграммы последовательностей
@startuml
Alice -> Bob : Привет!
Bob --> Alice : Привет, как дела?
@enduml
Пример диаграммы классов
@startuml
class Animal {
+String name
+int age
+run()
}
class Dog {
+String breed
+bark()
}
Animal <|-- Dog
@enduml
Пример диаграммы состояний
@startuml
[*] --> Idle
Idle --> Processing : Start
Processing --> Finished : Process complete
Finished --> [*]
@enduml
Пример диаграммы активности
@startuml
:start: -> :Request received;
if (Valid request?) then (yes)
-> :Process request;
-> :Send response;
else (no)
-> :Error;
endif
-> :End;
@enduml
Стилизация диаграмм
PlantUML позволяет настраивать стили диаграмм с помощью тегов и специальных команд. Например, можно изменять цвет, шрифт и положение элементов.
Пример стилизации:
@startuml
skinparam backgroundColor #EEEBDC
skinparam handwritten true
Alice -> Bob : Привет!
Bob --> Alice : Привет, как дела?
@enduml
Рендеринг онлайн
PlantUML диаграммы можно рендерить онлайн через PlantUML онлайн рендерер.
Техническое задание на построение DFD
Задача 1: Оформление заказа в интернет-магазине
Пользователь оформляет заказ в интернет-магазине через сайт. Процесс начинается с того, что пользователь выбирает товары и вводит данные о доставке. После этого система интернет-магазина проверяет наличие выбранных товаров на складе. Если все товары есть в наличии, система переходит к этапу оплаты. Пользователь вводит данные своей банковской карты, а система передает информацию в платежную систему. Платежная система проверяет данные и возвращает статус оплаты (успешно или неуспешно). Если платеж успешен, система подтверждает заказ и передает данные в логистическую службу для отправки. Логистическая служба отправляет товар по указанному адресу.
Задача 2: Процесс подачи и рассмотрения заявки на кредит в банке
Клиент подает заявку на кредит через онлайн-форму на сайте банка. В заявке указываются личные данные клиента (ФИО, паспортные данные) и сумма кредита. После получения заявки система банка запрашивает кредитную историю клиента в внешней кредитной базе. После получения кредитной истории банк анализирует данные и принимает решение. Если решение положительное, клиенту отправляется уведомление с одобрением кредита и дальнейшими инструкциями. Если решение отрицательное, клиенту отправляется отказ с указанием причин.
Задача 3: Процесс найма сотрудника в компанию
Кандидат отправляет резюме через веб-форму на сайте компании. Система получает данные и сохраняет их в базу данных кандидатов. После этого начинается первичный отбор: HR-система анализирует резюме кандидата и принимает решение, следует ли его приглашать на собеседование. Если решение положительное, руководитель отдела проводит собеседование с кандидатом, оценивает его результаты и передает информацию в HR-отдел. Если кандидат принят, HR-отдел заключает с ним контракт, после чего его данные заносятся в базу данных сотрудников компании.
Задача 1: Бронирование столика в ресторане
Пользователь открывает мобильное приложение ресторана и выбирает подходящий ресторан. Далее он выбирает дату и время, когда хочет забронировать столик, а также указывает количество человек. После подтверждения данных система проверяет наличие свободных столиков на выбранное время. Если столик доступен, система подтверждает бронирование и отправляет уведомление администратору ресторана. Администратор может просмотреть все бронирования на выбранный день и время, а также изменить или отменить бронирование в случае необходимости. Пользователь может получить уведомление с напоминанием о предстоящем бронировании за день до даты.
Пример
- Пользователь: Выбрать ресторан, указать дату и время, подтвердить бронирование.
- Система: Проверить наличие столиков, подтвердить бронирование, отправить уведомление.
- Администратор ресторана: Просмотреть бронирования, изменить или отменить бронирование.
Задача 2: Управление расписанием занятий в школе
Учитель входит в школьную информационную систему и создает расписание для своего класса. Учитель может добавлять, удалять и изменять уроки, а также указывать кабинеты и время проведения занятий. Ученик может войти в систему и просмотреть расписание на текущую неделю или на будущее время. Администратор школы имеет возможность управлять расписанием всех учителей, утверждать или изменять расписание перед его публикацией, а также отправлять уведомления ученикам и родителям о внеплановых изменениях в расписании.
Пример
- Учитель: Создать расписание, редактировать уроки, указать кабинеты.
- Ученик: Просмотреть расписание, получить уведомление об изменениях.
- Администратор школы: Управлять общим расписанием, утверждать расписания, отправлять уведомления.
Задача 3: Регистрация на конференцию
Участник заходит на сайт конференции и выбирает тип участия: оффлайн или онлайн. Он заполняет форму регистрации, включая свои контактные данные и тему выступления (если это докладчик). После заполнения формы система отправляет подтверждение на электронную почту участника и предлагает оплатить регистрационный взнос (если требуется). Организатор конференции может просматривать список зарегистрированных участников, редактировать информацию о конференции и отправлять важные объявления участникам.
Пример
- Участник: Выбрать тип участия, заполнить форму регистрации, оплатить взнос.
- Система: Отправить подтверждение регистрации, предложить оплату взноса.
- Организатор конференции: Просматривать участников, редактировать информацию, отправлять объявления.
Задача 4: Обслуживание автомобиля в автосервисе
Клиент записывается на обслуживание своего автомобиля через мобильное приложение автосервиса. Он выбирает тип услуги (например, техническое обслуживание или ремонт), дату и время, а также указывает информацию о своем автомобиле. Система проверяет доступность времени для записи и отправляет менеджеру автосервиса уведомление о новой записи. Менеджер может подтвердить запись и распределить работу на конкретного механика. После завершения работы механик указывает выполненные работы и материалы, а система отправляет клиенту уведомление о готовности автомобиля.
Пример
- Клиент: Выбрать тип услуги, указать данные автомобиля, записаться на обслуживание.
- Система: Проверить доступность времени, отправить уведомление менеджеру.
- Менеджер автосервиса: Подтвердить запись, распределить работу.
- Механик: Внести информацию о выполненных работах, подтвердить завершение.
Задача 1: Оформление заказа в интернет-магазине
Пользователь оформляет заказ в интернет-магазине через сайт. Процесс начинается с того, что пользователь выбирает товары и вводит данные о доставке. После этого система интернет-магазина проверяет наличие выбранных товаров на складе. Если все товары есть в наличии, система переходит к этапу оплаты. Пользователь вводит данные своей банковской карты, а система передает информацию в платежную систему. Платежная система проверяет данные и возвращает статус оплаты (успешно или неуспешно). Если платеж успешен, система подтверждает заказ и передает данные в логистическую службу для отправки. Логистическая служба отправляет товар по указанному адресу.
Задача 2: Процесс подачи и рассмотрения заявки на кредит в банке
Клиент подает заявку на кредит через онлайн-форму на сайте банка. В заявке указываются личные данные клиента (ФИО, паспортные данные) и сумма кредита. После получения заявки система банка запрашивает кредитную историю клиента в внешней кредитной базе. После получения кредитной истории банк анализирует данные и принимает решение. Если решение положительное, клиенту отправляется уведомление с одобрением кредита и дальнейшими инструкциями. Если решение отрицательное, клиенту отправляется отказ с указанием причин.
Задача 3: Регистрация пользователя на онлайн-платформе
Пользователь вводит личные данные (имя, email, пароль) для создания нового аккаунта на онлайн-платформе. Система проверяет валидность данных и отсутствие дублирующих учетных записей в базе данных. После успешной проверки система отправляет пользователю письмо для подтверждения регистрации. Пользователь подтверждает регистрацию через ссылку из письма. После подтверждения аккаунт активируется, и пользователю предоставляется доступ к платформе.
Задача 4: Процесс отправки сообщения в мессенджере
Пользователь пишет и отправляет сообщение в мессенджере. Клиентское приложение передает сообщение на сервер мессенджера. Сервер проверяет наличие получателя и пересылает сообщение. Адресат получает уведомление и читает сообщение. Сервер уведомляет отправителя о доставке и прочтении сообщения.
Диаграмма WBS
Диаграмма WBS (Work Breakdown Structure), или Иерархическая Структура Работ, представляет собой инструмент проектного управления, который позволяет структурировать все работы, необходимые для достижения целей проекта.
Она визуально отображает разбивку проекта на более мелкие и управляемые компоненты в виде иерархической древовидной структуры. Это облегчает понимание объема работ, планирование ресурсов, оценку сроков и бюджетов, а также управление задачами на протяжении всего жизненного цикла проекта.
Компоненты диаграммы WBS
В основе диаграммы WBS лежит принцип декомпозиции, где каждый уровень иерархии представляет более детальное разбиение работ:
- Проект: самый верхний уровень, представляющий весь проект в целом.
- Этапы или фазы: крупные блоки работ, разделяющие проект на основные части (например, планирование, разработка, тестирование).
- Пакеты работ: более детальные задачи внутри этапов, которые могут быть назначены конкретным исполнителям или командам.
- Задачи и действия: самые мелкие единицы работ, имеющие конкретные цели, сроки и ресурсы.
Каждый элемент WBS обычно сопровождается уникальным идентификатором и описанием, что облегчает отслеживание и управление.
Пример применения WBS
Рассмотрим проект по организации конференции:
Проект: Организация конференции
- Планирование
- Определение темы и целей конференции
- Формирование команды
- Составление бюджета
- Маркетинг и продвижение
- Разработка маркетинговой стратегии
- Создание рекламных материалов
- Продвижение в социальных сетях
- Логистика
- Выбор и бронирование площадки
- Организация питания и проживания
- Транспортная логистика
- Проведение конференции
- Регистрация участников
- Техническое обеспечение
- Обслуживание гостей
Использование диаграммы WBS
Диаграмма WBS служит основой для многих процессов управления проектом:
- Планирование: помогает определить полный объем работ и установить последовательность выполнения задач.
- Управление ресурсами: облегчает идентификацию необходимых ресурсов.
- Оценка стоимости и сроков: позволяет более точно оценить бюджет и временные рамки.
- Управление рисками: выявляет потенциальные риски на ранних этапах.
- Коммуникация: обеспечивает прозрачность и ясность для всех членов команды.
- Контроль и мониторинг: предоставляет четкие критерии для отслеживания прогресса.
Применение в создании Sitemap
WBS используется в веб-разработке для создания Sitemap:
Пример структуры сайта интернет-магазина:
- Главная страница
- Каталог товаров
- Электроника
- Смартфоны
- Ноутбуки
- Одежда
- Мужская
- Женская
- Дом и сад
- Мебель
- Декор
- Электроника
- О нас
- История компании
- Команда
- Блог
- Статьи
- Новости
- Контакты
- Форма обратной связи
- Карта проезда
Инструменты для создания диаграмм WBS
- Microsoft Project — программное обеспечение для управления проектами.
- MindManager — программа для создания ментальных карт.
- Lucidchart — онлайн-сервис для создания диаграмм.
- Draw.io * — бесплатный онлайн-инструмент для создания диаграмм.
- PlantUML * — инструмент с открытым исходным кодом для текстового описания диаграмм.
* - рекомендую обратить особое внимание
PlantUML и создание WBS
PlantUML позволяет создавать диаграммы WBS с помощью простого текстового описания. Пример:
@startwbs OnlineStore_Sitemap
skinparam backgroundColor transparent
<style>
wbsDiagram {
arrow {
LineColor #4CAF50
LineThickness 0.5
}
:depth(0) {
BackgroundColor #F1F8E9
LineColor #388E3C
LineThickness 3
}
:depth(1) {
BackgroundColor #C8E6C9
LineColor #388E3C
LineThickness 2
}
:depth(2) {
BackgroundColor #A5D6A7
LineColor #388E3C
LineThickness 1.5
}
:depth(3) {
BackgroundColor #81C784
LineColor #388E3C
LineThickness 1
}
node {
Roundcorner 15
Margin 10
MaximumWidth 275
FontColor #212121
FontSize 12
}
}
legend {
Roundcorner 15
backgroundColor #F1F8E9
entrySeparator #F1F8E9
}
</style>
* Проект "Модернизация IT-инфраструктуры"
** Оценка и анализ
*** Сбор данных и анализ оборудования
*** Анализ программного обеспечения
** Планирование и бюджетирование
*** Разработка плана и бюджета
*** Определение требований к оборудованию и ПО
** Закупка и внедрение
*** Выбор поставщиков и заказ оборудования
*** Установка оборудования и настройка ПО
** Тестирование и обучение
*** Тестирование и обучение персонала
** Поддержка
*** Техническая поддержка и обновления
@endwbs
Задания для тренировки:
Задание 1: Разработка мобильного приложения для фитнес-трекера
Описание: Ваша команда получила заказ на разработку мобильного приложения для фитнес-трекера. Приложение должно синхронизироваться с носимым устройством, отслеживать физическую активность пользователя, предоставлять аналитические данные, планы тренировок и диету. Также требуется реализовать социальные функции, позволяющие пользователям делиться достижениями и соревноваться с друзьями.
Основные этапы
- Сбор требований;
- Дизайн интерфейса;
- Разработка функционала;
- Тестирование;
- Запуск и поддержка.
Задание 2: Организация выставки современного искусства
Описание: Вы являетесь координатором проекта по организации выставки современного искусства в городском музее. Проект включает в себя отбор работ художников, аренду выставочных залов, маркетинговую кампанию, организацию открытия с участием прессы и VIP-гостей, а также обеспечение безопасности экспонатов.
Основные этапы
- Планирование и подготовка;
- Работа с художниками;
- Маркетинг и продвижение;
- Логистика и установка экспонатов;
- Мероприятие открытия и закрытия;
- Последующие действия после выставки.
Задание 3: Строительство и запуск интернет-кафе
Описание задачи: Вы планируете открыть интернет-кафе в центре города. Проект включает поиск подходящего помещения, ремонт и дизайн интерьера, закупку оборудования (компьютеры, мебель, сеть), получение необходимых разрешений, найм персонала, маркетинговую кампанию и торжественное открытие.
Основные этапы
- Подготовка и планирование;
- Ремонт и оснащение помещения;
- Установка технического оборудования;
- Юридические аспекты и лицензирование;
- Подбор и обучение персонала;
- Маркетинг и продвижение;
- Открытие и дальнейшая деятельность.
Задание 4: Проведение научно-исследовательского проекта
Описание задачи: Группа ученых получила грант на проведение исследования в области возобновляемых источников энергии. Проект рассчитан на два года и включает этапы литературного обзора, экспериментальных исследований, анализа данных, публикации результатов и презентации на международной конференции.
Основные этапы
- Планирование исследования;
- Проведение экспериментов;
- Анализ и интерпретация данных;
- Подготовка публикаций;
- Участие в конференциях;
- Управление проектом.
Диаграмма MindMap
Диаграмма MindMap (ментальная карта) — инструмент визуализации, который помогает структурировать информацию, идеи или задачи вокруг центральной концепции. Она широко применяется в программировании и управлении проектами для документирования систем, планирования архитектуры, разработки маршрутов API и создания дорожных карт проектов.
Основные элементы и применение MindMap
Концепция MindMap была популяризирована британским психологом Тони Бьюзеном в 1970-х годах. Радиальная структура ментальных карт отражает естественный процесс работы мозга, способствуя более эффективному обучению и стимулируя творческое мышление.
В центре диаграммы располагается главная идея или тема, от которой отходят ветви первого уровня — основные компоненты системы или проекта. Далее они разветвляются на подветви, раскрывающие детали и связанные функции. Каждая ветвь содержит ключевые слова или краткие фразы, описывающие понятия. Связи между ветвями показывают взаимодействия или зависимости между различными частями системы. Для улучшения восприятия используются цветовые кодировки, иконки, образы и символы, усиливающие ассоциации и облегчающие запоминание.
MindMap нашла свое применение в различных сферах деятельности:
- Документирование систем: визуализация структуры приложения, модулей и их взаимодействия, что облегчает коммуникацию внутри команды.
- Проектирование API: структурирование эндпоинтов, методов и связей между ними, упрощая процесс разработки и тестирования.
- Планирование архитектуры: помощь при выборе архитектурных решений, отображение плюсов и минусов различных подходов.
- Создание дорожных карт: эффективное планирование спринтов, определение этапов разработки и распределение задач по командам.
- Управление требованиями: структурирование функциональных и нефункциональных требований, облегчение их анализа и приоритезации.
Избегайте перегруза диаграммы лишней информацией, отсутствия четкой структуры, использования мелкого шрифта и плохого контраста. Регулярно обновляйте MindMap, чтобы она отражала актуальное состояние проекта.
Особое распространение ментальная карта получила при работе в командах, поскольку она хоророшо подходит мозговых штурмов и позволяет в удобном формате представить задачи из различных систем управления проектами: Jira, Trello и др.
Примеры использования MindMap
1. Документирование архитектуры системы микросервисов
Архитектура микросервисной системы для онлайн-платформы электронной коммерции.
- API Gateway
- Маршрутизация запросов
- Аутентификация
- Балансировка нагрузки
- Сервис управления пользователями
- Регистрация и аутентификация
- Профили пользователей
- Управление ролями и правами доступа
- Сервис каталога товаров
- Управление товарами
- Категоризация
- Поиск и фильтрация
- Сервис корзины и заказов
- Корзина покупок
- Оформление заказа
- История заказов
- Сервис платежей
- Интеграция с платежными шлюзами
- Обработка транзакций
- Возвраты и возмещения
- Сервис уведомлений
- Email-рассылки
- SMS-уведомления
- Push-уведомления
- Инфраструктура
- Оркестрация (Kubernetes)
- Мониторинг (Prometheus, Grafana)
- Логирование (ELK Stack)
- Безопасность
- SSL/TLS шифрование
- Защита от DDoS
- Контроль доступа

2. Планирование дорожной карты проекта (Roadmap)
Дорожная карта разработки SaaS-платформы (software as a service) для управления проектами.
- Q1 2024
- Модуль управления задачами
- Создание и назначение задач
- Канбан-доска
- Приоритеты и статусы
- Базовая аутентификация
- Регистрация пользователей
- Вход по email и паролю
- Интеграция с календарями
- Синхронизация с Google Calendar
- Напоминания о дедлайнах
- Модуль управления задачами
- Q2 2024
- Модуль командной работы
- Чат внутри приложения
- Совместное редактирование документов
- Уведомления в реальном времени
- Улучшение безопасности
- Двухфакторная аутентификация
- Роль-based Access Control (RBAC)
- Мобильное приложение
- Версия для iOS
- Версия для Android
- Модуль командной работы
- Q3 2024
- Модуль аналитики
- Отчеты по производительности
- Дашборды для менеджеров
- Интеграции с сторонними сервисами
- Slack
- Jira
- GitHub
- Масштабирование инфраструктуры
- Автоматическое масштабирование серверов
- Оптимизация базы данных
- Модуль аналитики
- Q4 2024
- Модуль управления ресурсами
- Планирование загрузки сотрудников
- Отслеживание времени (time tracking)
- Многоязычная поддержка
- Локализация на основные языки
- Поддержка разных часовых поясов
- Подготовка к публичному запуску
- Маркетинговая кампания
- Обучающие материалы и документация
- Модуль управления ресурсами

Инструменты для создания MindMap
Существует множество инструментов для создания ментальных карт:
- Visual Paradigm — мощный инструмент для моделирования и документирования систем.
- Coggle — онлайн-сервис для совместной работы над MindMap.
- Draw.io * — бесплатный онлайн-инструмент для создания диаграмм, поддерживает интеграцию с GitHub.
- PlantUML * — инструмент для текстового описания и генерации диаграмм, поддерживает MindMap.
- MindManager — профессиональное ПО для создания MindMap с расширенными возможностями.
- XMind — кроссплатформенное приложение для создания ментальных карт.
* - рекомендую обратить особое внимание
Cоздание MindMap при помощи PlantUML
PlantUML позволяет создавать MindMap с помощью простого текстового описания, что удобно для интеграции в системы контроля версий и совместной работы разработчиков.
@startmindmap API
skinparam BackgroundColor transparent
title API Архитектура
left side
* /api/v1
** /login
** /register
** /users
*** /{id}
**** GET
**** PUT
right side
** /transactions
*** /
**** GET
**** POST
** /notifications
*** /email
**** POST
*** /push
**** POST
@endmindmap

Например, при помощи MindMap можно также отобразить навигационную структуру веб-сайта:

Задания для тренировки:
Задание 1: Разработка комплексной системы управления контентом (CMS)
Предметная область: Вы архитектор проекта по разработке новой системы управления контентом (CMS) для крупного медиа-холдинга. Система должна поддерживать создание и публикацию различного типа контента (статьи, видео, подкасты), управление пользователями с разными уровнями доступа, интеграцию с социальными сетями, а также иметь модуль аналитики для отслеживания взаимодействия пользователей с контентом.
Необходимо создать детализированную MindMap диаграмму, которая отразит все компоненты системы, их взаимодействия и зависимости.
Возможный вариант MindMap:
-
Контентные модули
- Типы контента:
- Статьи
- Видео
- Подкасты
- Галереи изображений
- Редактор контента:
- WYSIWYG-редактор
- Поддержка drag-and-drop
- Управление медиафайлами
- Организация контента:
- Теги
- Категории
- Метаданные (SEO)
- Типы контента:
-
Управление пользователями
- Роли и права доступа:
- Автор
- Редактор
- Администратор
- Гость
- Аутентификация:
- Локальная (логин/пароль)
- SSO (OAuth2, LDAP)
- Профили пользователей:
- Настройки
- Персонализация
- Роли и права доступа:
-
Интеграции
- Социальные сети:
- Импорт/Экспорт контента:
- RSS-фиды
- API сторонних сервисов
- Уведомления:
- Email-рассылки
- Push-уведомления
- Социальные сети:
-
Аналитика
- Сбор метрик:
- Просмотры
- Лайки/Реакции
- Комментарии
- Отчеты:
- Еженедельные отчеты
- Ежемесячные отчеты
- Дашборды для редакторов и администраторов
- Интеграция с аналитическими сервисами:
- Google Analytics
- Яндекс.Метрика
- Сбор метрик:
-
Безопасность и производительность
- Безопасность:
- SSL/TLS шифрование
- Защита от SQL-инъекций
- Защита от XSS-атак
- Логирование и мониторинг
- Производительность:
- Кэширование:
- Redis
- Memcached
- CDN для статического контента
- Балансировка нагрузки
- Кэширование:
- Безопасность:
Задание 2: Проектирование и документирование RESTful API для финансового приложения
Предметная область: Вы разрабатываете финансовое приложение, которое предоставляет пользователям возможность управлять своими личными финансами: отслеживать доходы и расходы, устанавливать бюджеты, анализировать финансовые данные. Необходимо спроектировать и задокументировать RESTful API, которое будет использоваться мобильными и веб-клиентами.
Требования:
- Пользователи:
- Регистрация и аутентификация.
- Управление профилем.
- Счета:
- Создание разных типов счетов (банковский, наличные, кредитная карта).
- Получение баланса по счетам.
- Транзакции:
- Добавление доходов и расходов.
- Категоризация транзакций.
- Поддержка повторяющихся транзакций.
- Бюджеты:
- Установка месячных и годовых бюджетов.
- Отслеживание превышения бюджета.
- Аналитика:
- Генерация отчетов по периодам.
- Диаграммы расходов и доходов.
- Безопасность:
- Шифрование данных.
- Ограничение доступа по токенам.
Возможный вариант решения:
- Аутентификация
- POST /api/v1/login
- POST /api/v1/register
- Пользователи
- GET /api/v1/users/{id}
- PUT /api/v1/users/{id}
- Счета
- GET /api/v1/accounts
- POST /api/v1/accounts
- GET /api/v1/accounts/{id}
- PUT /api/v1/accounts/{id}
- DELETE /api/v1/accounts/{id}
- Транзакции
- GET /api/v1/transactions
- POST /api/v1/transactions
- GET /api/v1/transactions/{id}
- PUT /api/v1/transactions/{id}
- DELETE /api/v1/transactions/{id}
- Бюджеты
- GET /api/v1/budgets
- POST /api/v1/budgets
- GET /api/v1/budgets/{id}
- PUT /api/v1/budgets/{id}
- DELETE /api/v1/budgets/{id}
- Аналитика
- GET /api/v1/reports/summary
- GET /api/v1/reports/category
- Безопасность
- Использование HTTPS
- Токены доступа (JWT)
Контрольные кейсы для закрепления нотаций
Вариант определяется по принципу
№ зачетки % 5 + 1.
Вариант 1: Система управления умным городом (Smart City Management System)
Система управления умным городом предназначена для мониторинга и автоматизации различных процессов городского хозяйства, таких как управление уличным освещением, оптимизация маршрутов общественного транспорта, мониторинг качества воздуха и уровня шума, сбор данных с камер наблюдения, а также управление парковками и мусоровывозящими машинами. Система работает с большим объемом данных, поступающих от различных сенсоров и камер, и должна оперативно реагировать на изменения, например, включать дополнительное освещение в местах с высокой концентрацией людей в темное время суток или перенаправлять транспорт в случае пробок.
Построить:
- IDEF0
Для отображения высокоуровневых процессов мониторинга и управления умным городом, включая входные данные (сенсоры и камеры) и управляющие сигналы (освещение, транспорт). - DFD
Для визуализации потоков данных от сенсоров к системам анализа и принятия решений, а также взаимодействий между различными подсистемами (например, системой управления транспортом и системой освещения). - Диаграмма последовательности (Sequence Diagram)
Для детального описания последовательности операций, связанных с мониторингом и реакцией на событие, например, при обнаружении аварии.
Вариант 2: Платформа для предотвращения кибератак в корпоративной среде
Платформа для предотвращения кибератак предназначена для защиты корпоративной сети от вторжений, анализа подозрительного трафика, выявления уязвимостей и предотвращения утечек данных. Она включает в себя модуль мониторинга трафика в реальном времени, систему оповещения о подозрительных действиях, функции анализа уязвимостей в ПО, а также инструменты для анализа поведения пользователей. Система должна уметь оперативно реагировать на угрозы, блокируя вредоносные действия и оповещая администраторов.
Построить:
- MindMap
Для отображения структуры системы защиты, включая модули мониторинга, анализа уязвимостей, реагирования на инциденты и отчетности. - DFD
Для визуализации потоков данных между системой анализа трафика, системой оповещения и администраторами, а также для показания взаимодействия с внешними источниками угроз (например, антивирусные базы). - Use Case
Для описания действий администраторов и пользователей системы, таких как настройка политик безопасности, реагирование на инциденты и мониторинг состояния сети.
Вариант 3: Платформа для поддержки медиков при лечении хронических заболеваний
Система поддержки медиков помогает в управлении лечением пациентов с хроническими заболеваниями. Она собирает данные из разных источников, включая носимые устройства, медицинские приборы, и позволяет врачам отслеживать состояние пациента в реальном времени, настраивать индивидуальные планы лечения и отслеживать результаты. В случае ухудшения состояния система отправляет предупреждения врачу, а также может назначить дополнительные обследования или изменить курс лечения.
Построить:
- WBS
Для декомпозиции задач, связанных с настройкой и мониторингом пациентов, включая сбор данных, диагностику и управление лечением. - IDEF0
Для моделирования основных процессов, связанных с управлением здоровьем пациента, включая функции мониторинга и интервенции, а также взаимодействие с пациентами и медицинским персоналом. - Диаграмма последовательности (Sequence Diagram)
Для описания последовательности действий при мониторинге пациента, например, в случае изменения состояния и назначения нового лечения.
Вариант 4: Интерактивная платформа обучения с адаптивным контентом
Интерактивная образовательная платформа предназначена для персонализации учебного контента на основе успеваемости и предпочтений студентов. Платформа отслеживает прогресс, анализирует успехи и сложности, после чего адаптирует учебный материал для каждого студента. Также она позволяет преподавателям получать отчеты об успеваемости и проводить оценки в режиме реального времени. Система должна быть интегрирована с виртуальной лабораторией для выполнения практических заданий.
Построить:
- MindMap
Для отображения структуры образовательного контента и взаимодействия различных модулей платформы, таких как адаптивный контент, виртуальная лаборатория, отчеты для преподавателей. - DFD
Для описания потоков данных между модулем отслеживания прогресса, модулем адаптивного контента и интерфейсом преподавателей. - Диаграмма вариантов использования (Use Case)
Для отображения возможностей студентов, преподавателей и администраторов на платформе (например, прохождение тестов, загрузка заданий, получение отчета).
Вариант 5: Платформа для управления цепочками поставок с прогнозированием спроса
Система управления цепочками поставок помогает организациям контролировать запасы, прогнозировать спрос, отслеживать заказы и управлять логистикой. Она включает в себя инструменты для управления запасами, взаимодействия с поставщиками, управления заказами и прогнозирования спроса на основе исторических данных. Система должна учитывать сезонные колебания спроса, а также реагировать на изменения в производственных и логистических процессах.
Построить:
- WBS
Для детализации задач, связанных с управлением запасами, логистикой и прогнозированием спроса, включая интеграцию с ERP-системами. - Use Case
Для описания различных сценариев использования платформы (например, оформление заказа, контроль поставок, анализ данных). - Диаграмма последовательности (Sequence Diagram)
Для описания шагов при оформлении заказа, обновлении запасов и прогнозировании спроса на основе анализа текущих и исторических данных.
Диаграмма UserFlow
Диаграмма UserFlow, или диаграмма пользовательского пути, представляет собой инструмент проектирования интерфейсов, который отображает пути, по которым пользователи взаимодействуют с приложением или сайтом. Она помогает визуализировать все возможные сценарии использования продукта, начиная от первого контакта с пользователем и заканчивая достижением им своих целей.
Компоненты диаграммы UserFlow
Обычно диаграмма UserFlow состоит из нескольких ключевых элементов:
- Начальная точка: Точка входа пользователя в приложение или сайт.
- Действия пользователя: Последовательность действий, которые пользователь выполняет для достижения своей цели.
- Условные переходы: Ветвления, которые зависят от действий или выбора пользователя.
- Конечная точка: Точка, где пользователь достигает своей цели или выходит из приложения/сайта.
Пример применения UserFlow
Пример UserFlow для десктоп клиента приложения по управлнию проектами (Kanban) (3 курс):
.png)
Шаблон FigJam, который использовался при создании диаграммы: https://www.figma.com/community/file/970968239557865113
Пример UserFlow для детализации процесса авторизации в VPN-клиенте (рабочий проект):

Использование диаграммы UserFlow
Диаграмма UserFlow служит для:
- Понимания путей пользователя: Помогает проектировщикам и разработчикам понять, как пользователи взаимодействуют с продуктом.
- Оптимизации пользовательского опыта: Выявляет потенциальные проблемы и узкие места в пользовательском опыте.
- Планирования функционала: Помогает определить, какие функции и экраны необходимы для удовлетворения потребностей пользователей.
- Тестирования и валидации: Используется для тестирования и проверки гипотез о пользовательском поведении.
Пример UserFlow с PlantUML
PlantUML позволяет создавать диаграммы UserFlow с помощью простого текстового описания. Вот пример UserFlow для онлайн-магазина:
@startuml UserFlow_OnlineStore
skinparam backgroundColor transparent
(*) --> "Заходит на главную страницу"
"Заходит на главную страницу" --> "Ищет товар в поисковой строке"
"Ищет товар в поисковой строке" --> "Товар найден"
"Ищет товар в поисковой строке" --> "Товар не найден"
"Товар не найден" --> "Заходит на главную страницу"
"Товар найден" --> "Просматривает страницу товара"
"Просматривает страницу товара" --> "Добавляет товар в корзину"
"Просматривает страницу товара" --> "Заходит на главную страницу"
"Добавляет товар в корзину" --> "Переходит в корзину"
"Переходит в корзину" --> "Оформляет заказ"
"Переходит в корзину" --> "Заходит на главную страницу"
"Оформляет заказ" --> "Заказ успешно оформлен"
"Оформляет заказ" --> "Переходит в корзину"
"Заказ успешно оформлен" --> (*)
@enduml
Задания для тренировки
Задание 1: Мобильное приложения для фитнес-трекера
Описание: Разработайте UserFlow для мобильного приложения, которое синхронизируется с фитнес-трекером. Приложение должно отслеживать физическую активность пользователя, предоставлять аналитические данные, планы тренировок и диету. Также требуется реализовать социальные функции, позволяющие пользователям делиться достижениями и соревноваться с друзьями.
Основные этапы
- Запуск приложения;
- Синхронизация с фитнес-трекером;
- Просмотр статистики активности;
- Выбор плана тренировок;
- Социальные функции;
- Выход из приложения.
Задание 2: Выставка современного искусства
Описание: Разработайте UserFlow для сайта выставки современного искусства. Сайт должен позволять пользователям просматривать информацию о выставке, покупать билеты, узнавать о художниках и их работах, а также оставлять отзывы.
Основные этапы
- Заход на сайт;
- Просмотр информации о выставке;
- Покупка билетов;
- Просмотр информации о художниках;
- Оставление отзыва;
- Выход из сайта.
Задание 3: Интернет-кафе
Описание: Разработайте UserFlow для сайта интернет-кафе. Сайт должен позволять пользователям забронировать место, узнать о доступном оборудовании, ознакомиться с меню и контактной информацией.
Основные этапы
- Заход на сайт;
- Просмотр информации о кафе;
- Бронирование места;
- Просмотр меню;
- Контактная информация;
- Выход из сайта.
Анализ и разработка требований и создание wireframe макетов
Задание: На основе представленных примеров сформировать требования к разрабатываемой системе и разработать wireframe макеты экранных форм в соответствии с этими требованиями.
Супершип
Проект в Figm'e: ссылка
Система контроля за производством блюд
Задание на подготовку доклада по бизнес-нотациям
Необходимо подготовить доклад на тему, связанную с одной из бизнес-нотаций (например, BPMN, IDEF, ArchiMate и другие). В качестве темы должна быть выбрана нотация, которая ранее не разбиралась на занятиях. Работа может быть выполнена индивидуально или в составе группы (не более 3-4 человек). Доклад должен быть оформлен в формате реферата и сопровождаться презентацией, а также исходными файлами диаграмм и проектов.
Требования к докладу
Доклад должен включать следующие структурные элементы:
1. Титульный лист
- Название работы.
- Информация о составе группы (если работа выполняется в группе).
- Данные учебного заведения.
2. Оглавление
- Список разделов с указанием страниц.
3. Введение
- Обоснование актуальности выбранной нотации.
- Цели и задачи исследования.
- Краткая структура доклада.
4. Основная часть
4.1. Обзор выбранной нотации
- История появления и развития.
- Основные принципы и особенности.
- Область применения.
4.2. Компоненты и элементы нотации
- Подробное описание компонентов в виде таблицы:
- Название компонента.
- Его назначение.
- Примеры применения.
- Обязательно указание стандарта, регулирующего использование нотации (например, BPMN 2.0, UML 2.5 и т.д.).
4.3. Примеры использования компонентов
- Детализированные диаграммы и схемы, демонстрирующие применение компонентов.
4.4. Кейсы и практические примеры
- Разбор нескольких кейсов, иллюстрирующих применение нотации на практике.
- Обязательный элемент: готовые диаграммы и схемы с пояснением.
- Дополнительные кейсы для самостоятельного анализа.
4.5. Обзор инструментов для построения диаграмм
- Описание доступных инструментов (например, Lucidchart, Draw.io, Bizagi Modeler, Visio и т.д.).
- Сравнительный анализ по ключевым критериям: стоимость, функциональность, совместимость, сложность освоения.
5. Заключение
- Выводы и значимость изученной нотации.
- Возможности дальнейшего использования в профессиональной деятельности.
6. Список использованных источников
- Перечень использованной литературы, статей, стандартов и веб-ресурсов.
Необходимо учитывать:
- Таблица с описанием компонентов должна содержать ссылки на соответствующие стандарты.
- Примеры использования нотации должны быть наглядными и содержать пояснения.
- Исходные файлы (диаграммы, проекты, коды) необходимо приложить в соответствующих форматах (.bpmn, .drawio, .vdx и т.д.).
Диаграмма развертывания
С теоретической справкой можно ознакомиться в документе.
Диаграммы развертывания можно рисовать при помощи нашего любимого PLantUML. Пример диаграммы из ВКР приведен ниже.
@startuml
node "User Client" <<device>> {
node "Web Browser" <<device>> {
[HTML5] <<artifact>>
}
}
node "Web Server (NGINX)" <<device>> {
node "PHP FPM 8.2" <<execution environment>> {
node "Web Site" <<artifact>> {
[Model]
[View]
[Webhook Handler]
[Cache]
[Controller]
[Middleware]
[Route Handler]
[Asset Manager]
}
}
[HTML5] -d- [PHP FPM 8.2] : <i>**https:80**</i>
}
node "DB Server" <<device>> {
[PostgreSQL DB] <<artifact>>
}
[Web Site] -d- [DB Server] : <i>**Propel ORM**</i>
node "YooKassa" <<artifact>> {
[Payment Service] <<component>>
}
[Web Site] -u- [YooKassa] : <i>**YooKassa SDK (YooKassa API)**</i>
node "VK" <<artifact>> {
[VK Group] <<artifact>>
}
[Web Site] -u- [VK]: <i>**VK API**</i>
node "SMTP Server" <<device>> {
[SMTP Service] <<artifact>>
}
[Web Site] -r- [SMTP Server] : <i>**PhpMailer (SMTP session)**</i>
node "Telegram" <<artifact>> {
[Supership Group] <<artifact>>
}
[Web Site] -u- [Telegram] : <i>**Monolog (Telegram API)**</i>
@enduml
Как вы видите, здесь используются уже методы для ручного направления стрелок (u, r, d, l), иначе элементы на диаграмме уже будут расположены нелогично и громоздко. Не забывайте про них. Можете поэксперементировать и убрать их.
Итоговый результат представлен на изображении ниже:
Тестовые кейсы
По этим кейсам рисуют только те, кто еще НЕ определился с темой ВКР.
Кейс 1: Базовое веб-приложение с CDN
Создайте диаграмму развертывания для веб-приложения, которое использует CDN для статических ресурсов, веб-сервер для обработки запросов, и базу данных для хранения данных.
Требования:
- Клиент: веб-браузер, который загружает HTML и взаимодействует с сервером через HTTPS.
- CDN: для доставки статических ресурсов (CSS, JS, изображения).
- Веб-сервер: обрабатывает запросы через NGINX и использует PHP.
- База данных: MySQL для хранения пользовательских данных.
Подсказка:
- Включите компоненты HTML5, CDN, веб-сервер, PHP-обработчик и MySQL.
- Пример связи:
[Web Server] -u- [CDN]: "GET Static Files"
Кейс 2: Микросервисная архитектура
Разработайте диаграмму для приложения, построенного на микросервисной архитектуре, где несколько сервисов взаимодействуют через API.
Требования:
- Клиент: мобильное приложение.
- API Gateway: маршрутизирует запросы на соответствующий микросервис.
- Микросервисы:
- User Service: обрабатывает данные пользователей.
- Order Service: управляет заказами.
- Payment Service: обрабатывает платежи.
- База данных: разделена по микросервисам (MongoDB для пользователей, PostgreSQL для заказов).
- Внешний API: используется сервис оплаты (например, Stripe).
Подсказка:
- Используйте разные устройства (например, контейнеры Docker).
- Пример связи:
[API Gateway] -u- [Payment Service]: "POST /payment"