Проектирование БД (ER-модели)
Концептуальное проектирование и ER-модель
Одной из важнейших трудностей в создании программного продукта считается нахождение взаимопонимания между разработчиком и заказчиком. Когда речь заходит о базах данных, сложность возрастает, поскольку специалист по СУБД мыслит категориями таблиц, индексов и транзакций, в то время как заказчик говорит про накладные, поставки, спецификации или оборудование. Экономисты, бухгалтеры или инженеры часто точно знают, какая информация должна храниться, но не представляют, как описывать это в терминах программирования. Параллельно программист, обладающий глубокими знаниями о реляционной теории, алгоритмах и языках SQL, может не знать тонкости бизнеса и технические нюансы предметной области.
Чтобы устранить это противоречие, в проектировании баз данных принято выделять этап концептуального проектирования. На нём разработчик и представители бизнеса пытаются выявить и зафиксировать ключевые сущности, необходимые для автоматизации реального предприятия, и определить их взаимосвязи. Пока не рассматривается, какая конкретно СУБД будет использована, как именно будут храниться файлы и где разместить индексы. Технические детали остаются за рамками, потому что в первую очередь важно отразить суть бизнеса.
Задачи концептуальной модели
В ходе концептуального проектирования создаётся обобщённая модель информации, которая должна быть представлена в БД. Эта модель не учитывает особенности SQL, аппаратные ограничения, детали операционной системы или оптимизацию хранения на диске. Цель – сформировать высокоуровневое понимание данных: какие объекты (сущности) должны храниться, какие у них атрибуты и какие связи между ними существуют. Подобный подход даёт свободу в выборе дальнейших архитектурных решений, а также упрощает процесс обсуждения с заинтересованными лицами, поскольку им проще рассматривать наглядные схемы, чем перечень реляционных таблиц или исходный код.
ER-модель (сущность–связь)
Для визуального и интуитивно понятного представления на концептуальном уровне была создана модель «сущность–связь», анонсированная Питером Ченом в 1976 году в работе «The Entity-Relationship Model. Toward a Unified View of Data». Эта модель опирается на несколько базовых понятий:
- Сущность (Entity). Является обобщённой категорией объектов из реального мира, о которых требуется хранить сведения. Примеры: «Сотрудник», «Договор», «Самолёт», «Книга», «Цех» и т. п.
- Атрибут (Attribute). Отражает свойства сущности, которые помогают характеризовать конкретный объект. Примером служат «Имя» и «Фамилия» для сотрудника, «Номер рейса» для самолёта, «Название» для книги.
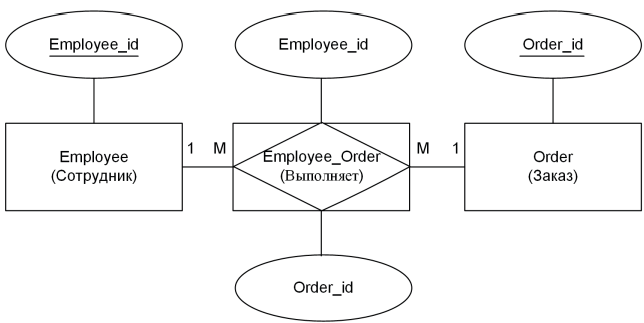
- Связь (Relationship). Описывает, каким образом сущности взаимодействуют между собой. Например, один сотрудник работает в одном отделе, а один отдел содержит многих сотрудников; книга пишется одним или несколькими авторами и т. д.
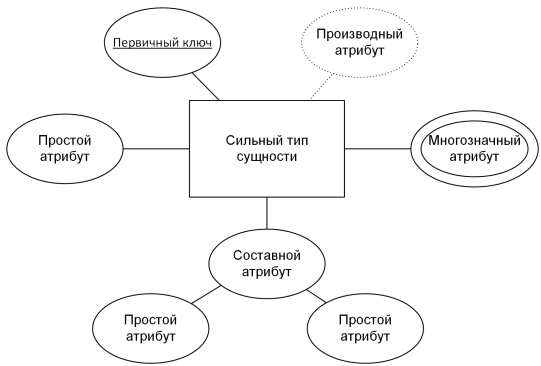
При построении диаграмм ER-модели сущности обычно рисуются прямоугольниками, атрибуты — эллипсами, а связи — ромбами, которые соединяют соответствующие сущности.
Сильные и слабые типы сущностей
В ER-диаграммах различаются сильные и слабые сущности. Сильная сущность способна существовать отдельно, а слабая зависит от «родительской» сущности. К примеру, «Сотрудник» может быть слабой сущностью по отношению к «Отделу», если не имеет смысла существование сотрудника вне отдела. На диаграмме сильный тип сущности изображается обычным прямоугольником, а контур слабого типа сущности рисуется двойной линией.
Атрибуты сущностей
Каждая сущность обладает набором атрибутов, которые могут быть:
– простыми (одно значение, например «Имя»);
– составными (адрес или ФИО, которые объединяют несколько податрибутов);
– многозначными (несколько телефонных номеров);
– производными (значения, получаемые расчётом, например возраст, вычисляемый из даты рождения).
В реляционных таблицах производные атрибуты редко когда превращаются в реальные столбцы таблицы, физически хранящие значения. Ведь нет смысла занимать память под данные, которые можно получить путем элементарных вычислений.
На диаграмме производные атрибуты обычно окружены пунктирной линией, а многозначные — двойной. Если атрибут является идентификатором (первичным ключом в будущем), его название подчёркивается.
Связи в ER-модели
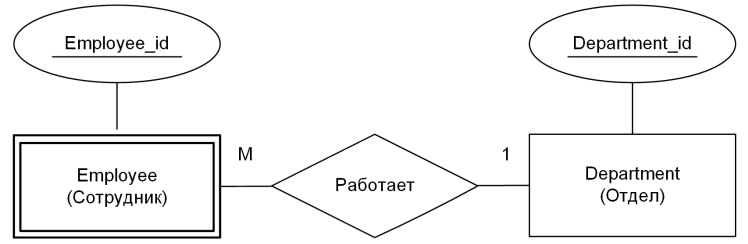
При концептуальном проектировании особое внимание уделяется тому, как объекты взаимодействуют. Часто встречаются три основных типа:
- 1:1 (например, «человек – паспорт»).
- 1:N (например, «отдел – сотрудники»).
- M:N (например, «книга – авторы» или «заказ – товары»).
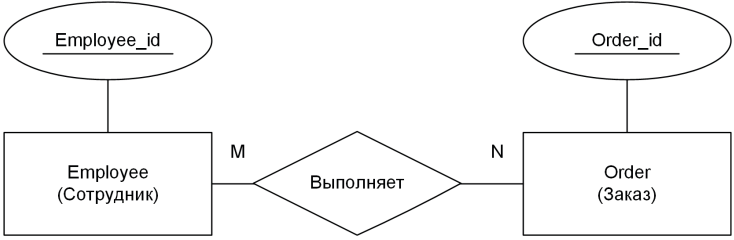
При этом связь M:N в классической реляционной БД прямо не поддерживается и в дальнейшем логическом проектировании преобразуется путём введения «коммутирующей» таблицы. Дополнительный тип сущности разрывает связь M:N пополам, что позволяет нам трансформировать неподъемное для реляционных баз данных отношение «многие ко многим» в пару обычных связей «один ко многим». Вне зависимости от всех хитросплетений нашей ER-модели искусственно созданная сущность-коммутатор в любом случае будет содержать два атрибута для внешних ключей.
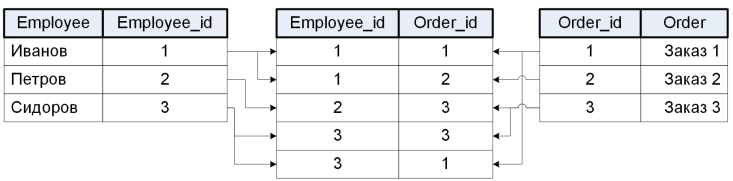
Кроме бинарных связей встречаются унарные (рекурсивные).Замыкание типа сущности на самого себя окажется весьма полезным при описании многоуровневых иерархических структур, подобных классификатору товаров, хранящихся на складе. Возможны и связи более высоких порядков (тернарные и т. д.), когда одна и та же связь объединяет три или более сущностей, но при реальной реализации чаще всего такая связь разбивается на несколько бинарных.
На практике для построения иерархии реальной реляционной таб лице потребуется как минимум три столбца: поле первичного ключа «Goodsclass_id», поле внешнего ключа «Parent_id» и содержащее названия категорий текстовое поле «Goodsclass». Рекурсивная связь между
записями таблицы обеспечивается за счет взаимодействия внешнего и первичного ключей, с этой целью поле внешнего ключа дочернего элемента хранит значение первичного ключа родительского узла. Если же идет речь о самом старшем элементе иерархии, который никому не подчинен (в нашем примере во главе дерева расположена папка «Классификатор»), то в его внешнем ключе окажется определитель NULL.

Вариации ER-моделей и CASE-системы
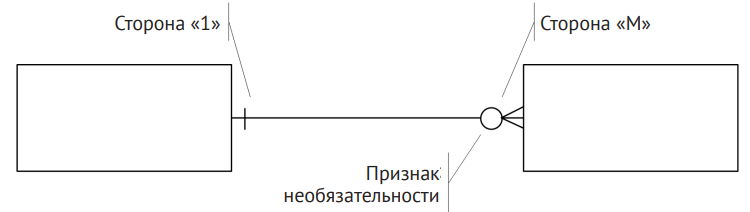
Модель Чена оказалась настолько удачной, что на её основе возникло несколько нотаций. Одна из популярных – Crow’s Foot («воронья лапка»), предложенная Чарльзом Бэчмэном. Там связи рисуются линиями, причём сторона «N» выглядит как «лапка», а сторона «1» изображается в виде одиночной черты. Существуют и другие варианты: IDEF1X, ERwin, PowerDesigner и т. д. Многие современные CASE-средства предоставляют графический интерфейс, позволяющий рисовать ER-диаграммы «наглядно», после чего могут автоматически генерировать структуры SQL для определённой СУБД.
Что получается в итоге?
Главным результатом становится набор схем, диаграмм и пояснений, отражающих реальную предметную область в удобном для понимания виде. Подобное представление даёт возможность проверить, действительно ли система точно отражает логику предприятия, и убедиться, что все ключевые объекты и связи учтены. После согласования концептуальной модели наступает очередь логического проектирования.
Логическое проектирование и нормализация
На логическом уровне происходит преобразование концептуальной ER-схемы в набор реляционных таблиц. Каждая сущность превращается в отдельную таблицу, а атрибуты становятся столбцами. Связи воплощаются через первичные и внешние ключи. Однако недостаточно просто «механически» перенести объекты на таблицы. Структура нуждается в проверке на отсутствие аномалий (нежелательных ситуаций при вставке, удалении или обновлении строк). Для этого применяется процесс нормализации.
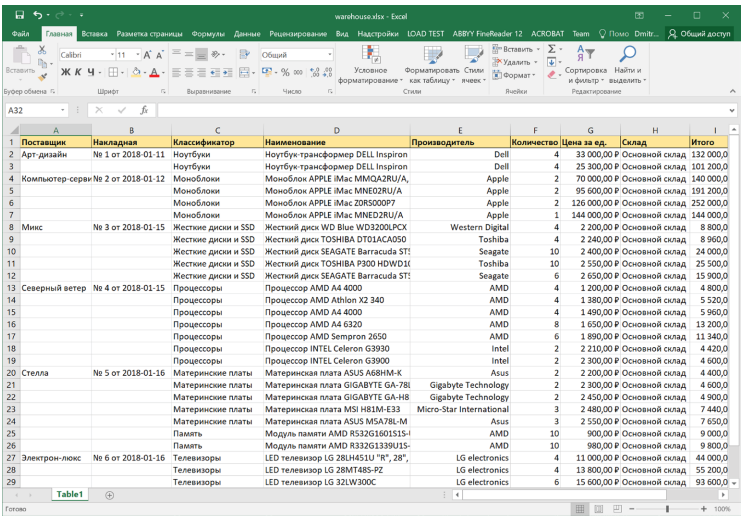
Ненормализованные таблицы могут содержать дублирующуюся информацию и некорректно отражать реальные объекты. Подобная избыточность может казаться безобидной, пока не приходится вносить изменения или добавлять новые данные. На этом фоне возникают три характерных вида аномалий — вставки, удаления и редактирования.
-
Аномалия вставки. В ненормализованной таблице при добавлении новой строки может оказаться, что требуется ввести лишнюю информацию, не относящуюся к сути добавляемых данных. Для примера — если по каждому товару приходится повторять одни и те же сведения о поставщике или накладной. Бывает и обратная ситуация: невозможно корректно вставить запись, пока не заполнены обязательные поля, которые пока неизвестны (например, номер накладной для товара ещё не получен). Компьютеру не ясно, что пустые поля означают «те же данные, что и в предыдущей строке», и это приводит к конфликтам или неполным записям.
-
Аномалия удаления. При удалении одной строки может утратиться информация, ценная для других записей. В примере склада указывается удаление ошибочно внесённого товара (жёсткого диска), а вместе с ним — потери сведений о накладной, поскольку поля накладной дублировались только в этой строке. В итоге оставшиеся товары «теряют» связь с накладной или переходят под другую. Лишние перемещения данных с одной строки в другую усложняют работу и могут приводить к полному рассогласованию учёта.
-
Аномалия обновления (редактирования). Если одинаковые сведения (название поставщика, классификатор товара, производителя) присутствуют во множестве строк, то при изменении одного из этих значений придётся искать и исправлять все дубликаты. Пропуск хотя бы одной строки приведёт к тому, что в базе будут сосуществовать старый и новый варианты. Тот же «классификатор» «Память» → «Модуль памяти» придётся массово переправлять во всех строках, что создаёт риск ошибиться или оставить часть ячеек без обновления.
Такие ситуации особенно ярко проявляются в примере с одним большим листом Excel, где дублируются названия поставщиков или другие поля.
Нормализация последовательно упорядочивает реляционные таблицы, устраняя повторяющиеся группы и расщепляя слишком «тесно связанные» столбцы. Этот процесс идёт ступенчато через нормальные формы: 1NF → 2NF → 3NF (затем BCNF, 4NF, 5NF). На каждой ступени таблица приобретает новые свойства, позволяющие избавиться от очередного типа аномалий.
Первая нормальная форма (1NF)
Неделимость (атомарность) значений
Основа 1NF — отсутствие повторяющихся групп и соблюдение атомарности. Если в одной ячейке хранится список значений (к примеру, «фантастический комедийный боевик» для жанров кино), это нарушает 1NF. С точки зрения реляционной теории каждая ячейка должна содержать строго одно значение. Аналогичная проблема возникает, если в ячейке объединён номер накладной и дата в виде «45/12.05.2021». Атомарность означает, что номер накладной и дата должны храниться отдельно.
Часто встречающимся примером нарушения атомарности становится хранение нескольких телефонных номеров в одном поле или перечисление категорий через точку с запятой. Для приведения к 1NF рекомендуется либо выделять отдельную таблицу для многозначных атрибутов, либо реализовать иной механизм хранения.
Под атомарностью значения понимается, с одной стороны, его целостность, а с другой – неделимость. Разделение данных на «атомы» впоследствии позволит нам вооружить БД дополнительным сервисом, в частности разнообразными способами сортировки данных и расширенными методами фильтрации и поиска данных.

Функциональные зависимости и их роль
Нормализация — это не только механическое разделение таблиц, но и анализ функциональных зависимостей. При записи A → B считается, что значению A соответствует единственное значение B (A — детерминант, B — зависимый атрибут). Различают несколько типов:
-
Частичная зависимость. Атрибут зависит лишь от части составного ключа (например, если ключ состоит из полей «Номер накладной» + «Дата», а какой-либо столбец зависит только от «Номера»). Подобная ситуация мешает 2NF и указывает на необходимость выносить зависимый столбец в отдельную таблицу или вводить искусственный ключ.
-
Полная зависимость. Каждый неключевой атрибут связан сразу со всей совокупностью ключа (или ключом из одного столбца). Пример: «ИНН» ↔ «ФИО владельца». Нет избыточного повторения, поскольку каждому значению ИНН строго соответствует одна фамилия, имя и отчество и наоборот.
-
Транзитивная зависимость. Возникает, если атрибут A зависит от B, а B — от C, при этом A косвенно зависит от C. В примере склада «Поставщик» может зависеть от «НомерНакладной + Дата», а «Производитель» относится уже к конкретному наименованию товара, и получается цепочка зависимостей. Транзитивность даёт повод выделять отдельные таблицы для тех групп атрибутов, которые связаны через «промежуточные» поля. Удаление транзитивных зависимостей обеспечивает третью нормальную форму (3NF).
-
Многозначная зависимость. Обозначает связь, при которой одному значению A сопоставляется набор значений B. Это прямая предпосылка наличия связи «многие ко многим» (M:N). Во избежание аномалий такая структура разносится на отдельную промежуточную таблицу, что соответствует четвёртой нормальной форме (4NF).
Наряду с зависимыми могут быть независимые атрибуты — те, что вообще никак не связаны между собой. К примеру, если «Поставщик» и «Склад» не влияют друг на друга напрямую, то в терминах функциональных зависимостей будет записано A ¬→ B и B ¬→ A. Когда таблица грамотно декомпозирована и ключи расставлены, функциональные зависимости становятся прозрачнее, а риск аномалий заметно снижается.
Вторая нормальная форма (2NF)
Частичные зависимости
Таблица соответствует 2NF, если в ней отсутствуют частичные зависимости неключевых атрибутов от части составного ключа. Если ключ составной, то некоторые столбцы могут зависеть только от одного из компонент ключа, что нежелательно. Чаще всего 2NF достигается, когда вместо составных ключей используются искусственные (суррогатные) первичные ключи, например поле-счётчик (INTEGER IDENTITY) или GUID. Тогда не возникает частичных зависимостей, так как ключ состоит из единственного поля.
Предположим, что мы определили составной первичный ключ таблицы на основе атрибутов «Номер накладной», «Дата накладной» и «Наименование». Обсудим это решение с точки зрения частичных функциональных зависимостей. Наличие составного ключа привело к тому, что такой атрибут, как «Поставщик», зависит от первой половины ключа («Номер накладной» и «Дата накладной»), а атрибут «Производитель» зависит от другой части ключа – «Наименование». Следовательно, наша исходная таблица не соответствует требованиям 2NF.
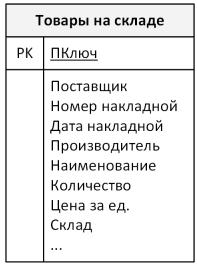
После приведения к 2NF между атрибутом ключа «ПКлюч» и любым другим столбцом таблицы установилось однозначное соответствие, частичные зависимости устранены.
Третья нормальная форма (3NF)
Транзитивные зависимости
3NF убирает транзитивные зависимости, при которых атрибут A зависит от B, а B зависит от ключа, и потому A косвенно зависит от ключа. Типичный пример — поля, указывающие имя поставщика, когда сам поставщик связан с другой таблицей. В 3NF требуется вынести такие группы столбцов в отдельные таблицы, чтобы каждый атрибут зависел напрямую только от первичного ключа. При выполнении 3NF обычно формируется несколько «справочных» таблиц (например, для производителей, категорий, типов и т. п.), а в основной таблице остаются лишь идентификаторы и ключи.
В таблице склада посредников больше чем достаточно – она прячет в себе несколько транзитивных зависимостей. Очевидный пример транзитивности – «Поставщик». Указанный атрибут непосредственно связан лишь с атрибутами, описывающими накладную («Номер накладной» и «Дата накладной»), а все остальные атрибуты связаны с «Поставщик» транзитивно.
Исправим сложившуюся ситуацию:
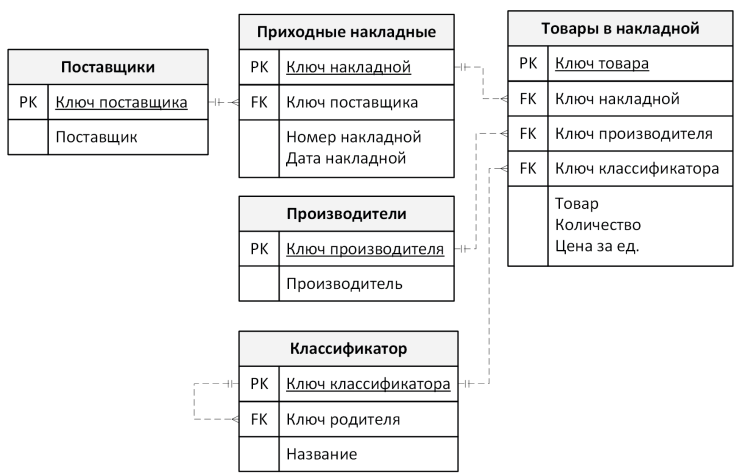
Справочные таблицы также имеют ряд очевидных преимуществ:
- существенно сокращается физический размер дочерней таблицы.
- при редактировании значения (например, переименование поставщика) нет необходимости просматривать сотни записей, а достаточно изменить одно значение в справочной таблице;
- при вводе данных значительно снижается вероятность появления ошибки пользователя, так как вместо ввода с клавиатуры ему предлагаются на выбор заранее подготовленные значения.
Формы BCNF, 4NF, 5NF
– BCNF (нормальная форма Бойса–Кодда) усиливает требования 3NF для случаев, когда в таблице имеется несколько потенциальных ключей.
– 4NF устраняет многозначные зависимости, то есть ситуацию M:N. Для её реализации вводится дополнительная таблица-связка, чтобы связь «многие ко многим» стала двумя «один ко многим».
– 5NF решает проблему зависимых сочетаний, когда при декомпозиции таблицы могут появиться ложные строки при обратном соединении (JOIN).
В большинстве обычных проектов достигается 3NF или BCNF, поскольку этого достаточно, чтобы исключить основные аномалии модификации и избыточность данных.
Что получается в итоге? На данном этапе формируются взаимосвязанные реляционные таблицы, удовлетворя хотя бы первым трём нормальным формам. Конечная схема обеспечивает удобство и целостность при вводе, обновлении и удалении данных. При этом внутри базы появляются внешние ключи, «справочные» таблицы для хранения отдельных категорий, а связи M:N заменяются промежуточными. Полученная логическая модель готова к реализации в конкретной СУБД.
Физическое представление данных
Когда реляционная схема таблиц утверждена, приходит черёд детального решения: как хранить данные на диске или другом постоянном носителе. В 1960-е годы преобладали файлы с последовательным доступом на магнитной ленте, и реализация БД была крайне примитивной. В современных СУБД обычно применяется двухуровневая структура хранения: часть данных находится в оперативной памяти (кеш/буфер), а основная копия размещается во внешней памяти (жесткий диск, SSD).
Двухуровневая модель
В типичной реляционной системе хранится один или несколько файлов БД, внутри которых размещаются блоки, а блоки состоят из записей. Записи, в свою очередь, включают поля, соответствующие столбцам таблицы. Примерная схема выглядит следующим образом:
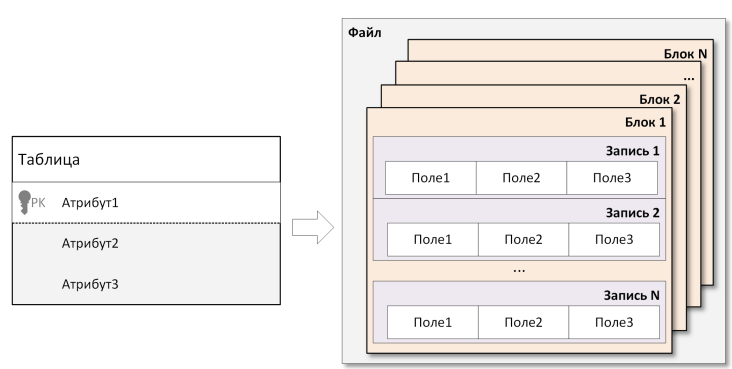
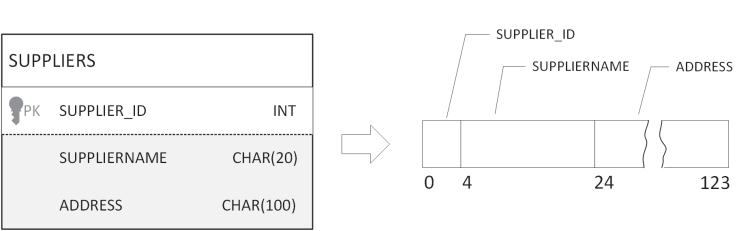
- Поле (Field). Является низкоуровневым элементом, соответствующим конкретному атрибуту (столбцу) в логической таблице. Может иметь фиксированный размер (числа, даты) или переменный (строки
VARCHAR). - Запись (Record). Объединение полей, обычно отражает одну строку таблицы (кортеж). Может быть фиксированной или переменной длины, если в ней есть хотя бы одно поле переменной длины. Зачастую запись сопровождается служебным заголовком с информацией о размере, времени модификации и т. д.
- Блок (Block/Page). Содержит одну или несколько записей, а также служебный заголовок, где указываются идентификатор блока, таблица смещений для записей, сведения о блокировках. Размер блока может быть, к примеру, 4 КБ. При недостаточном месте для новой записи выполняется «расщепление» или запись отправляется в блок переполнения.
- Файл (File). Набор блоков, представляющий физическую основу хранения. В реальных СУБД часто используется один или несколько крупных файлов, внутри которых СУБД сама распределяет таблицы, индексы и служебные объекты.
Модификация записей
Вставка новой строки приводит к созданию записи в одном из блоков, удаление — высвобождает пространство, которое помечается специальным признаком (tombstone), а обновление — заменяет содержимое полей, иногда с перемещением записи в другой блок при изменении длины. Подобная внутренняя механика скрыта от пользователя, который воспринимает таблицу логически.
Журнал транзакций
Одним из важнейших компонентов физического уровня выступает журнал (лог) транзакций. При каждом изменении СУБД записывает в него информацию о том, какие данные менялись, под каким идентификатором транзакции, в каком блоке или файле. Это даёт возможность откатывать изменения при сбоях, а также восстанавливать базу до согласованного состояния. Вследствие этого журнал транзакций рекомендуется включать в резервное копирование вместе с основными файлами БД.
Резюме
Разработка базы данных идёт поэтапно:
- Концептуальное проектирование: создаётся ER-модель, описывающая сущности, их атрибуты и связи. Этот уровень даёт полное представление о предметной области, не затрагивая технические детали.
- Логическое проектирование: ER-модель переводится в реляционные отношения (таблицы). Применяется нормализация (1NF, 2NF, 3NF и при необходимости более высокие формы), устраняются аномалии модификаций и избыточность, прорабатываются внешние ключи и структура столбцов.
- Физическое представление: определяется, как именно таблицы, индексы, журналы транзакций и другие объекты будут храниться на диске. Рассматриваются блоки, файлы, механизмы вставки, удаления, обновления, слияния и расщепления блоков, а также работа с журналом транзакций.
Такой подход обеспечивает системную и надёжную базу данных, точно отражающую реальные процессы предприятия и при этом оптимизированную для практической работы в конкретной СУБД.
Кейс: «Небольшая библиотека»
Ситуация:
В учреждении (например, в учебном заведении) открывается библиотека с ограниченным каталогом книг. Требуется вести базу данных, чтобы учитывать:
- Сами книги (название, автор, ISBN и т. д.).
- Читателей, имеющих право брать книги (фамилия, имя, контакты).
- Факт выдачи книги: кто и когда взял, когда нужно вернуть, когда вернул.
Задача — спроектировать БД, не усложняя её дополнительными справочниками, но при этом правильно учесть основные принципы:
- Отдельные сущности для книг и читателей (а не всё в одной таблице).
- Хранение фактов выдачи/возврата в отдельной структуре, чтобы понимать текущее состояние книги (на руках у читателя или в наличии).
- Исключение дублирующихся полей (автор/название/фамилия) и обеспечение целостности.
1. Концептуальная (ER) модель
В самом простом варианте можно выделить такие сущности:
-
Book (Книга)
Содержит основные характеристики: название, автор, год издания, ISBN (при наличии) и, возможно, издательство. -
Reader (Читатель)
Описывает людей, имеющих право получать книги на руки: Фамилия, Имя, Отчество (опционально), контактный телефон, адрес или другой идентификатор (например, номер читательского билета). -
Loan (Выдача)
Отражает конкретный акт выдачи книги читателю. Хранит дату выдачи, дату возврата (может быть NULL, если книга ещё на руках), а также ссылки на какую книгу выдали и какому читателю.
С точки зрения ER-диаграммы:
- «Book» и «Reader» — две сильные сущности.
- «Loan» выступает как отдельная сущность, указывающая связь между «Book» и «Reader». Фактически это связь многие ко многим, превращённая в сущность: одна книга может иметь много записей о выдаче (в разное время разным людям), а один читатель может брать много книг.
При желании можно усложнить сценарий, добавив сущность «Автор», если предполагаются книги с несколькими авторами (возникнет связь M:N между «Book» и «Author»). Однако для знакомства достаточно считать, что поле «Автор» хранится внутри «Book» как текстовая строка.
2. Логическая модель (реляционная структура)
Вводим первичные ключи (ID) и внешние ключи:
-
Таблица
BookBook_ID(PK, автоинкремент или GUID)Title(Название)Author(Автор книги)Year(Год издания)ISBN(Уникальный международный код, опционально)
-
Таблица
ReaderReader_ID(PK)LastName(Фамилия)FirstName(Имя)PhoneAddress(или другой идентификатор, например номер билета)
-
Таблица
LoanLoan_ID(PK)Book_ID(FK →Book.Book_ID)Reader_ID(FK →Reader.Reader_ID)DateBorrowed(дата выдачи)DateReturned(дата возврата, NULL, если не вернули)
Минимальная нормализация
- 1NF: Каждое поле — атомарное значение: название книги, фамилия читателя и пр. Запрещается хранить несколько авторов в одной ячейке через запятую (в нашем упрощении допустимо считать «Автор» одним текстовым полем).
- 2NF: Отсутствуют частичные зависимости, поскольку ключи (
Book_ID,Reader_IDиLoan_ID) состоят из одного столбца. - 3NF: Нет транзитивных зависимостей: «Автор» напрямую привязан к книге, а не к чему-то ещё.
Пример аномалий
Если попытаться в одной «общей» структуре записать название книги, фамилию читателя, дату выдачи, дату возврата и т. д., то возникнут аномалии:
- Аномалия вставки: при добавлении новой книги придётся указывать читателя (который может быть неизвестен), либо же пустые поля создадут путаницу.
- Аномалия удаления: при удалении одной записи (например, если ошибочно внесли неверную дату выдачи) можно потерять данные о книге или о читателе.
- Аномалия обновления: если потребуется переименовать книгу, в которой автор опечатан, придётся исправлять это во всех строках (где она фигурирует вместе с разными датами выдачи).
Разделение на три таблицы решает эти проблемы: каждая книга описывается один раз, каждый читатель — один раз, а выдачи отражаются только через связи.
3. Физическая реализация
На физическом уровне (например, в любой SQL-СУБД) создаются три таблицы с полями, как описано выше. Индексы ставятся по первичным ключам и, возможно, по столбцу ISBN (если требуется быстрый поиск книг). При выдаче книги в программу вносится новая строка в Loan со ссылками на Book_ID и Reader_ID, фиксируется текущая дата. При возврате просто заполняется DateReturned.
Задание
Ниже приводятся пять возможных вариантов небольших учебных проектов по созданию базы данных. Конкретный вариант выбираете, исходя из формулы: Вариант = (номер зачётки % 5) + 1
Общие требования к заданию для всех вариантов:
- Сначала необходимо выполнить концептуальное проектирование (ER-модель), определить сущности, их атрибуты и связи.
- После этого — логическое проектирование (реляционные таблицы, ключи, внешние ключи и т. д.).
- Реализовать базу данных в Microsoft Access.
Для получения представления о работе в MS Access и стандартных приёмах создания форм и отчётов предлагается курс у А. Ермоленко: https://aermolenko.ru/2012/02/bazy-danny-h/.
- Создать не менее двух оформленных форм (например, для ввода/поиска данных) и как минимум один отчёт (для вывода результатов).
Прим. При желании можно согласовать собственную тематику, если имеется интерес к другой предметной области.
Вариант 1: «Учёт посетителей фитнес-клуба»
Небольшой фитнес-клуб выдаёт абонементы клиентам. Необходимо учитывать данные:
- Клиенты (ФИО, дата рождения, контактный телефон, вид абонемента).
- Тренеры (ФИО, специализация, стаж).
- Посещения (кто, в какой день и время пришёл, в какой зал пошёл).
- Возможность формирования отчёта по активным клиентам и их плану тренировок.
Задачи:
- Выделить сущности «Клиент», «Тренер», «Абонемент» (или атрибут типа абонемента), «Посещение», прописать основные атрибуты.
- Продумать, как фиксируется факт визита и кто из тренеров занимается с клиентом (если такая опция нужна).
- Создать формы для ввода/редактирования клиентов и регистрации посещений.
- Подготовить отчёт, например, о текущих активных абонементах или статистику по посещениям за месяц.
Вариант 2: «Учёт студентов и дисциплин»
В учебном заведении необходимо учитывать информацию о студентах, изучаемых ими предметах и оценках за сессии. База данных помогает формировать итоговую ведомость.
Задачи:
- Определить сущности «Студент» (ФИО, группа, дата рождения), «Дисциплина» (название, кафедра), «Успеваемость» (студент, дисциплина, оценка, семестр).
- Организовать связи: один студент может сдавать много дисциплин, а одна дисциплина — многим студентам (M:N, решается промежуточной сущностью «Успеваемость»).
- Создать формы для ввода/редактирования студентов и добавления оценок.
- Сформировать отчёт, например, сводную ведомость оценок по группе или по конкретной дисциплине.
Вариант 3: «Учёт заявок на ремонт компьютеров»
Сервис по ремонту компьютеров принимает заявки от клиентов (ФИО, контактные данные). Каждый клиент может обращаться многократно с разными устройствами (ноутбук, стационарный ПК, планшет). Для каждой заявки фиксируется дата, тип проблемы (аппаратная, программная), предварительная стоимость. После ремонта указывается окончательная стоимость и дата завершения.
Задачи:
- Определить сущности: «Клиент» (ФИО, телефон), «Устройство» (тип, модель), «Заявка» (дата начала, дата завершения, статус, стоимость). Связь «Клиент–Устройство» может быть 1:N, а сами заявки могут содержать ссылку и на клиента, и на устройство.
- Создать формы для регистрации новых заявок, закрытия (завершения) заявок, поиска по клиентам.
- Сделать отчёт, например, о текущих незавершённых ремонтах или сводку суммарных затрат по клиентам за месяц.
Вариант 4: «Мини-магазин электроники»
Небольшой магазин торгует электроникой. Необходимо хранить информацию о товарах, поставщиках и продажах.
Задачи:
- Выделить сущности «Товар» (название, категория, цена), «Поставщик» (название компании, контактные данные) и «Продажа» (номер продажи, дата, клиент, список купленных товаров).
- Подумать, как оформляются покупки: одна продажа может включать несколько позиций. Это может потребовать дополнительную таблицу «Продажа_Товар» (M:N).
- Создать формы для добавления новых товаров и регистрации продаж.
- Реализовать отчёт о сумме продаж за период или о количестве проданных устройств конкретного типа.
Вариант 5: «Небольшой автопарк»
Есть автопарк, где учитывают наличие машин, водителей и их командировки (или рейсы).
Задачи:
- Определить сущности «Автомобиль» (марка, модель, госномер, год выпуска), «Водитель» (ФИО, стаж, категория прав), «Рейс» (дата выезда, дата возврата, водитель, автомобиль).
- Продумать связи: один автомобиль может совершить множество рейсов (но в каждый момент времени — не более одного рейса), водитель также может участвовать в разных рейсах.
- Создать формы для ввода новых автомобилей и регистрации рейсов.
- Сформировать отчёт: например, список всех поездок за месяц по конкретному автомобилю или водителю.